Community på Sveriges dataportal
-
appropå persistenta identifierare så har vi med det i vägledningen för att tillgängliggöra information.
Innebär det att man ska äga ett domännamn för att skapa identifierare, eller hur ser praxis ut? Finns det exempel på hur detta tillämpas och organiseras?
Beständiga identifierare bör utformas som URI:er, (Uniform Resource Identifier), enligt formatet:
http(s)://{domän}/{typ}/{koncept}/{referens}
Inom vissa sektorer/områden kan det vara relevant med specifika typer av identifierare. -
@jonor I dagsläget har vi tyvärr inga konkreta exempel eller mer information än det som står i vägledningen. På frågan om man ska äga domännamnet så har jag lite svårt att svara på det eftersom jag är lite för dåligt insatt i hur man skapar beständiga identifierare, men det som är viktigt är ju att länken blir hållbar över tid, även om tex organisationen för datamängden ändras eller man väljer att göra ändringar på webbplatsen där datamängden är åtkomlig ifrån. Vi har sett ett behov av att ta fram en tydligare vägledning kring detta och att förankra den hos ett antal centrala aktörer i frågan. Bla Riksarkivet/Riksantikvarieämbetet, MSB och SND (Svensk nationell datatjänst, en portal för forskningsdata) har ju idag lite rekommendationer som inkluderar beständiga identifierare. Och det vore fint om vi kunde få till lite samsyn kring en rekommendation om hur man ska gå tillväga med detta:) Men vi är inte där ännu. Kanske några fler i den här tråden kan hjälpa dig vidare?
-
@josefinlassi Ja det låter ju som identifierare bör ligga under något namn avsett för registerföring och mer långsiktig förvaltning, då ligger kanske arkivmyndigheter eller dataförvaltare nära till hands. Jag gissar att det klarnar mer när man börjar använda URI:er och ställa frågor mot dem eller vill koppla ihop dem för egen del. Om DIGG ska stödja och hjälpa organisationer i detta behöver man nog kunna förklara hur det fungerar, gärna inbegripande exempel och fallstudier. Tack för tipsen om rekommendationer.
Apropå trådämnet, har dataportalens API-register URI:er och kopplingar till Wikidata?
-
@jonor dataportalen har ingen formell koppling till Wikidata, men dom som jobbar där hämtar bl.a. data från dataportalen. Förfrågningar från Wikidata har också varit en anledning till att vi har snabbat upp arbetet med att sätta öppna licenser på information som ligger på digg.se, tex vägledningar, rapporter mm. Det arbetet är igångsatt ganska nyligen.
-
@jonor sa i Kategorisera API:er efter datasort:
Apropå trådämnet, har dataportalens API-register URI:er och kopplingar till Wikidata?
Vad tänker du att de ska koppla mot/länka till? Olika datasorter i Wikidata (exempelvis Q7300787 (realtidsdata) )?
-
[Tar och städar lite genom att bryta ut denna dialog till en egen tråd ]
@ainali @jonor
Man kan nog diskutera frågan på två nivåer;-
Dataportalen bygger på metadata i RDF där unika identifierare i sig är centralt både för innehållet i metadatan och för själva processen att automatiskt hämta in och visa upp i sökmotorn. Det finns riktlinjer och rekommendationer kring hur detta ska genomföras i bland annat i specifikationer för metadatan och skördning.
-
Respektive tillhandahållande aktör uppmuntras till att tillhandahålla unik identifierare för deras datamängder och API:er. Vi detekterar inte idag om enskilda datamängder/API:er på Sveriges dataportal har kopplingar till Wikidata. Om man skulle vilja som publicerande aktör peka ut kopplingar mellan datamängden/API:et och till Wikidatas identifierare, skulle man kunna använda fält såsom "Identifier", dvs att peka på att datamängden har en sekundär identifierare. Dataportalens begreppstjänst (beta) kan också användas för att terminologier och kodlistor ska erhållas maskinläsbara och refererbara. Det i sin tur möjliggör en sammanlänkning och relationer med entiteter i Wikidata, men även såklart för fler sammanhang.
Klicka här för mer information om dataportalens tjänster , samt om skördning av metadata till Sveriges dataportal
-
-
@ainali sa i Identifierare och relationer:
@jonor sa i Kategorisera API:er efter datasort:
Apropå trådämnet, har dataportalens API-register URI:er och kopplingar till Wikidata?
Vad tänker du att de ska koppla mot/länka till? Olika datasorter i Wikidata (exempelvis Q7300787 (realtidsdata) )?
Det låter en av värdemängdena inom "Uppdateringsfrekvens"
-
@josefinlassi kolla på Havs- och vattenmyndigheten dom gör rätt och har EU unika identifierare. Det jag ser mer och mer är att det finns en tydlighet i fördningar 2001:100 vem som äger den officiella statistiken och de är de som bör skapa tydliga identifierare...
Kollar vi på Badplatser där dataset skapats av flera kommuner men det blir bara rörigt och SILOS
- Uppsala kommun
- hittar på egna ID:n och länkar inte Havs- och vattenmyndigheten som är dom som har persistenta identifierare för EU bad
- resultat data SILO
- Södertälje kommun
- hittar på egen identifierare, har koordinater i RT90
- resultat data SILO
- Karlskrona kommun
- hittar på ett eget idArea dvs. använder inte EU varianten NUTS dvs. dom refererar inte Havs- och vattenmyndighete
- resultat data SILO
- ....
Mer om detta kaos med badvatten: min GITHUB Svenskabadplatser där jag nu importerat Havs- och vattenmyndigheten badplatser och håller på att koppla dessa... vi har egna identifierare men pekar på NUTS som finns hos Havs- och vattenmyndigheten
Min tro varför det blir detta kaos organisationerna förstår inte vilka myndigheter som är ansvariga för badvatten och troligen har identifierare
- Löses med
- bättre myndighetskunskap
- bättre plattformar att kommunicera med dom som är anvariga ex. Havs- och vattenmyndigheten. Idag svarade dom på email efter en vecka men saknar ex. yta på GITHUB
- känns som det är ofta externa konsulter som gör lösningarna dom måste styras upp eller skaffa kompetens inhouse
- Uppsala kommun
-
@ainali sa i Identifierare och relationer:
@jonor sa i Kategorisera API:er efter datasort:
Apropå trådämnet, har dataportalens API-register URI:er och kopplingar till Wikidata?
Vad tänker du att de ska koppla mot/länka till? Olika datasorter i Wikidata (exempelvis Q7300787 (realtidsdata) )?
Jag tänker mig t.ex. att det kan gå att hitta datamängder jag är intresserad av via Wikidata. Jag provade att söka efter kommunernas dataportaler och fick upp en lista där bl.a. Stockholms dataportal dök upp. Där kunde jag sedan leta vidare efter data.
Sedan vore det intressant att veta om jag kan inkludera den nuvarande nationella dataportalen i sökningen också.
Dock ser ämnesmärkningen i de nationella portalerna ganska sporadisk och ojämn ut så långt jag sett. Jag föreställer mig att det kunde finnas möjligheter till friare kategorisering och koppling, och mer kraftfulla och enhetliga sökverktyg, om informationen finns representerad på Wikidata.
Jag tänker också på fallet där jag skulle vilja hitta datamängder av samma typ från Sverige och andra länder som jag skulle vilja göra jämförelser mot.
Jag vet inte hur informationen om kommunernas dataportaler hamnat i Wikidata, om det är av ideella krafter eller offentligt sanktionerat, men jag tycker det verkar värdefullt att den kan göras åtkomlig där för meta-sökning över spridda informationskällor.
Frågan om realtidsuppdateringar är väl också intressant. Samlas data in löpande till Wikidata från public service och andra som publicerar nyhetsartiklar och media t.ex.?
-
@jonor Jag skulle säga att följande riktlinje från DIGGs andra vägledning är relevant i detta sammanhang. Det är att betrakta som en e-tjänst även om den kanske inte har ett webbgränssnitt:
https://webbriktlinjer.se/riktlinjer/6-tillhandahall-e-tjanster-pa-en-webbadress-som-tillhor-myndigheten/ -
@jonor Wikidata Egenskapen Open Data portal jag begärde en egenskap på Wikidata 24 jun 2020
- den skapades 4 jul 2020
- sedan matade jag in så många jag hitta se karta
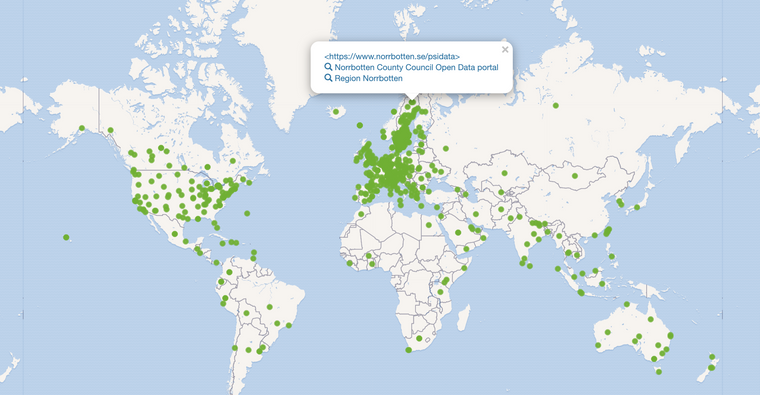
- min vision var
- steg ett var att enklare börja hitta dataportalen och att Google hittar den se hur snabbt Google läser Wikidata tweet
- att om det blir bra så skulle alla Wikipedia artiklar om ex. en kommun kunna ha en länk till deras öppna dataportal var min tanke... tanken möttes med försiktig positiva kommentarer (att inför förändring på Wikipedia är oftast halvt omöjligt
") )
)
- att om det blir bra så skulle alla Wikipedia artiklar om ex. en kommun kunna ha en länk till deras öppna dataportal var min tanke... tanken möttes med försiktig positiva kommentarer (att inför förändring på Wikipedia är oftast halvt omöjligt
- steg ett var att enklare börja hitta dataportalen och att Google hittar den se hur snabbt Google läser Wikidata tweet
- steg 2 var att beskriva enskilda dataset. Jag slog ihop en POC med Wikibase se sweopendata.wiki.opencura.com
- samtidigt med detta då jag fortfarande trodde på Öppen data så var tanken att hämta från alla kommuner exempelvis deras vindskyddsdata se blog , lesson learned ofta visste en kommun inte vad Öppen data är....
- försökte även få in metasolution och dataportalen eller så är det någon annan man skall prata med (tror tyvärr att metasolution ser Wikidata som ett hot än en möjlighet men vi har väl alla olika agendor
Jag har nog backat 10 år på mina visioner....
- skall saker hända så måste det till saker som JobTech och Fastighetslab .... röran med badplatser pekar på att vi efter minst 6 års jobbande med Öppen data kanske mer ser brister än framsteg....
Frågan om realtidsuppdateringar är väl också intressant. Samlas data in löpande till Wikidata från public service och andra som publicerar nyhetsartiklar och media t.ex.?Som med alla frivilliga communities så är Wikidata spretigt man gör det man tycker är kul
Börjar Öppen data levereras mer proffsigt så kan nog någon synkronisera det nedan vad några försökt göra men som det är även i denna diskussionsgrupp är att dom som sitter på dataset är svåra att hitta/kommunicera med
- Riksdagens ledamöter kollar en engelsman tweet
/ GITHUB- tror även motioner etc. uppdateras av Robin etc... se "Analysera rikspolitiken med hjälp av Wikidata" / video om HD beslut
- Nobelpriset har jag en Jupyter notebook
- Svenskt Kvinnobiografiskt lexikon har jag uppdaterat med Jupyter notebook - men har sagt till dom att jag inte gör det längre men att dom enkelt kan göra det själva
- Litteraturbanken samma där Notebook - men har slutat uppdatera
- Riksarkivet SBL har inget API men jag gjorde webskrabing med en Notebook
- lite "intressant" att Riksarkivet var ansvariga för Öppen data 2016 men har inte ens API till sitt eget data...
- osv....
-
@salgo60 Tack för bakgrunden, kul att veta hur det gjordes och bra insats med att registrera dataportalerna. Ja det går förstås att se historiken för när och hur en egenskap infördes och populerades på Wikidata, att den möjligheten finns är man ju inte riktigt van vid.
Jag såg också att det tidigare fanns en egenskap för "external data available at", men att den endast var definierad som ett textvärde snarare än en entitet som kan ha egenskaper i sig.
-
@jonor det var ett infall jag hade.... jag hade kollat på data.europa.eu (EDP) se min Jupyter Notebook och dit skickar svenska dataportalen text strängar med språkkod vilket är helt fel 2021

Fick inget svar av dom varför dom gör så fel.... ställde senare en fråga på en workshop se video om att Google Dataset Search Engine har kunskapsgraf min fråga vid 54 min om att EDP springer åt fel håll som skickar textsträngar. Särskilt när det är Europiska dataset med massor med olika språk.... gissar att ordet kommuner inte är självklart i hela Europea utan bättre kommunicera med en graf
Jag har försökt lyfta detta på GITHUB DIGGSweden/DCAT-AP-SE/issues/84 men får en sur bismak att den specen drivs för att passa Metasolutions produkt plus att DIGG känns för svaga på kunskapsgrafer och att förstå länkade data så dom kan inte driva detta mot EDP.... känns som Open Data har svårt att lämna startblocken....
/med hopp att jag har fel
-
@salgo60 Ja jag provkörde OpenRefine lite i dagarna, och det framstår som att en uttalad målsättning vid publicering av data borde vara att förebygga och undvika rekonsiliering/manuellt arbete med sammanställningar.
Alla instanser som arbetar med arkiv och register borde väl också vara fullt medvetna om nyttan med och användningen av referensnummer och standardiserade egenskaper, det måste ju tillhöra den grundläggande praktiken i den världen.
När det gäller ekonomidata är det kanske sämre med standardisering och identifiering av betydelser av olika fält, men det beror väl på ev. bakomliggande redovisningskrav också.
Med en referens för fältegenskapen skulle den ju enkelt kunna översättas till önskat språk.
Jag vet inte i vilken mån detta återspeglas i styrningen av offentlig datapublicering i dagsläget. Det borde kanske finnas någon form av beställarroll som checkar av att detta fungerar och tillgodoses i publicerade datamängder så man undviker onödigt arbete vid nyttjande.
Ex. på rekonsiliering i Refine:
https://youtu.be/5tsyz3ibYzk?t=205 -
@jonor coolt... för mig tog det 2-3 veckor innan jag blev kompis med Open Refine.... min gamla trötta hjärna fick kortslutning
Japp det är så självklart för den som använder datat att data skall vara länkat....
- I FB gruppen OpenGov publicerades en länk till en DN artikel "Till stora kostnader samlas data in som aldrig används”" där vi kanske har förklaringen som är så enkel att ingen använder dagens data.... 5 års jobb och ingen använder data
""Intresset för att samla in och bearbeta data inom offentlig sektor åtföljs ofta av ointresse att använda sig av dessa data.""
studie som verkar peka på att Öppen data inte används och i såfall spelar det ju inte så stor roll

Jag är lite rädd att en organisation som DIGG inte lyckas anställa folk som är "data scientist" och vill jobba med data och skapa ett svenskt ekosystem.... utan fokus blir mer att leverera en pdf och inte göra skitgörat som det är att styra upp och tvätta data och ha en prioriterad backlog. Att DIGG på 2 år skapat ett dataset kanske visar denna Digitala brist på vision..... kollar man vad som ramlat in enligt datahamstern var det 2164 uppdaterade dataset nu senast gissa om detta 100000 dubblas om vi får fart på kommuner och myndigheter och att sitta med fritextsökning funkar inte.... Wikipedia insåg detta 2012, Google 2012 ....

Snyggt exempel på Kunskapsgrafer vs. text strängar idag skickas datat vidare till Europeiska dataportal där svenska kommuner är en text sträng med en språklabel om jag förstått det rätt

I WIkidata som är långt från perfekt utan enligt mig mer ett socialt experiment kan vi fråga efter
- alla administrativa enheter på nivå 2 = Svenska kommuner
- Q13220204 är WD objektet för nivå 2
- 1692 av dessa objektet har P3896 som är ytan --> vi kan visa en karta över objektets utbredning (saknas mycket i Sverige) dvs. skulle vi kunna få bra data så har vi en infrastruktur som är enormt spännande och skalar snyggt till hela världen....
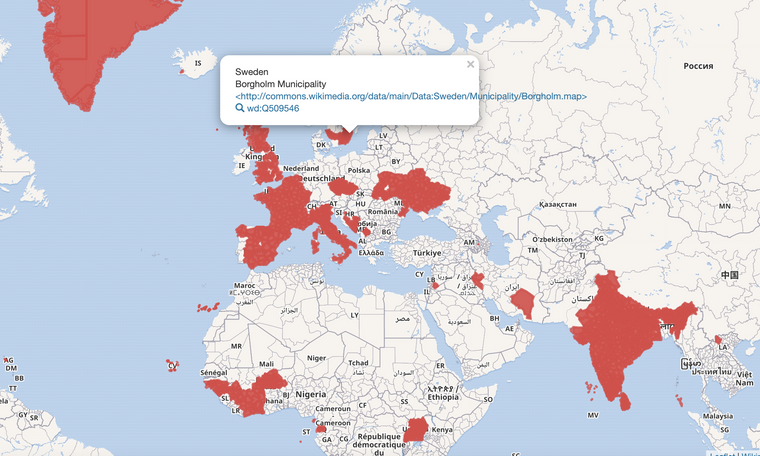
lite intressant att vi lyckats få bättre data från Malawi
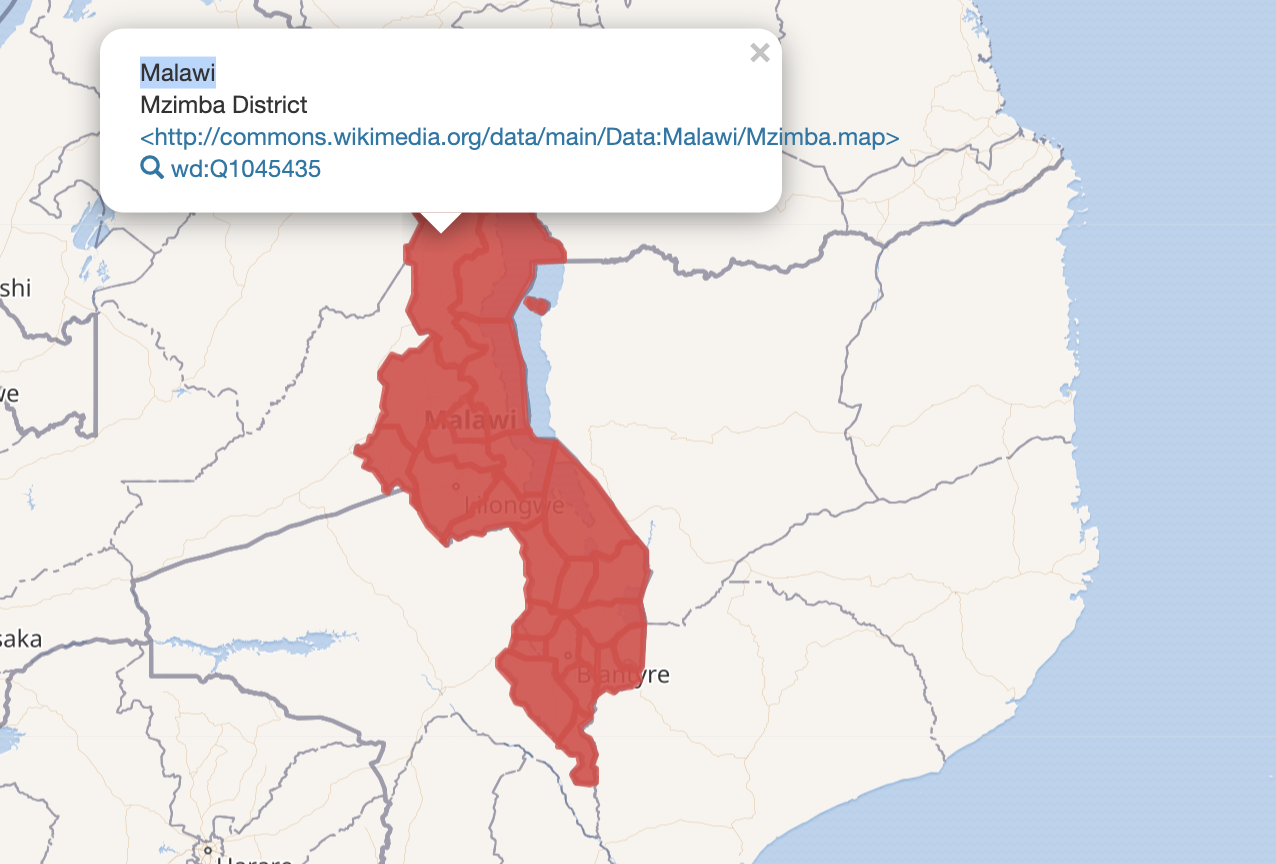
OT Exempel på verktyg Wikidata har för att kolla kvaliten på exempelvis Svenska Badplatser länk känns också saker DIGG borde ha i sin portfölj för att styra upp Öppen Data och kunna se var det behövs bättre data kvalitet, nu verkar man lyssna på EDP som räkna antal uppladdade dataset...
- I FB gruppen OpenGov publicerades en länk till en DN artikel "Till stora kostnader samlas data in som aldrig används”" där vi kanske har förklaringen som är så enkel att ingen använder dagens data.... 5 års jobb och ingen använder data
-
@salgo60 Jag känner också att det kan behövas några veckor för att komma in i Refine, även om introduktionsvideorna var ganska bra. En del saker är svåra att komma på hur man ska göra även om man har en idé om vad man vill konceptuellt. Det verkar vara lite av en hybrid av UI och ett expression language API för mer avancerade operationer.
Jag får 2 träffar på dataset från DIGG på länken, Status och Leverantörsfakturor, men de kanske har ramlat in med två års mellanrum. Det kan ju vara en övning att försöka hitta historiken i metadatan för dataseten.
Hade hört talas om den artikeln på DN och tänkte försöka läsa den, det låter intressant. Hörde också om en annan debatt-artikel som tar upp att Sveriges som det verkar lite speciella decentraliserade administration har lett till en inofficiell centralisering.
https://www.dn.se/debatt/man-och-invandrare-borde-ha-prioriterats-i-vaccineringen/
DN DEBATT 24/4. Bo Rothstein
...
Som Riksrevisionens rapport gör klart leder denna ”uppgörelsestyrning” till minskad offentlig insyn och, som det nu med fatala konsekvenser visat sig, ”otydlig ansvarsfördelning”.
...
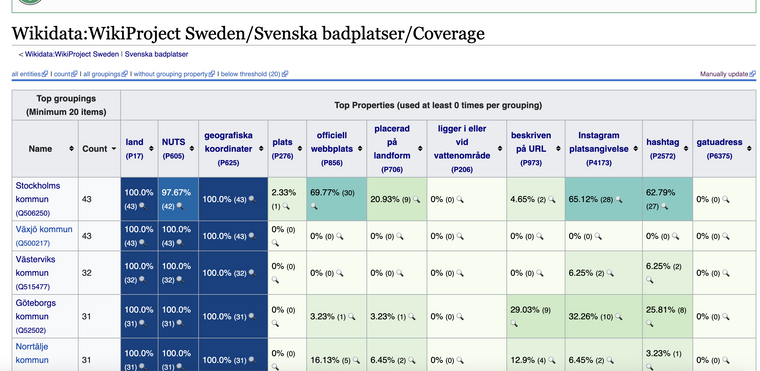
Riksrevisionens rapport slår fast följande: ”Många gånger har regeringens insatser syftat till att höja ambitionsnivån, men Riksrevisionen bedömer att dessa inte har inneburit nya åtaganden för kommuner och landsting.”Intressant med sidan med täckningsgrad för egenskaperna, jag hade själv börjat tänka i de banorna hur man kunde få en översikt över hur komplett information är inom ett område.
-
@jonor ring om du har problem med Open Refine 0705937579 jag finns även på Telegram salgo60 Har nog ett antal video som svar på email till andra du har även bra support på Gitter och GITHUB
- finns även bra på programminghistorian.org exempel "Fetching and Parsing Data from the Web with OpenRefine" där man webscrapar och hämtar från API
-
@jonor sa i Identifierare och relationer:
Det kan ju vara en övning att försöka hitta historiken i metadatan för dataseten.
Utgivningsdatum för ett dataset skulle isf. heta "issued" enligt DCAT?
Jag kan inte hitta det i metadatan från DIGG:s dataset.https://docs.dataportal.se/dcat/sv/#dcat_Dataset-dcterms_issued
Egenskap http://purl.org/dc/terms/issued
Kravnivå Rekommenderadhttps://admin.dataportal.se/store/760/metadata/1536?recursive=dcat
https://admin.dataportal.se/store/760/metadata/1544?recursive=dcat -
@jonor jag är inte alls kopis med docs.dataportal.se/dcat tycker inte jag hittar mycket som är intressant. Jag skulle vilja koppla ihop organisationer i Wikidata med deras organisations identifierare i dataportal.se så kan du hitta denna koppling så kan vi begära att skapa en Wikidata egensak
-
@salgo60 Det låter som en bra idé, tyvärr verkar dataportalen sådana här adresser till organisationer:
https://www.dataportal.se/sv/datasets?p=1&q=&s=2&t=20&f=http%3A%2F%2Fpurl.org%2Fdc%2Fterms%2Fpublisher||http%3A%2F%2Fid.kb.se%2Forganisations%2FSE2021000837||false||uri||Organisationer||Statistikmyndigheten SCB - Statistiska centralbyrån&rt=dataset%24esterms_IndependentDatadär identifieraren är
http%3A%2F%2Fid.kb.se%2Forganisations%2FSE2021000837%7C%7Cfalse%7C%7Curi%7C%7COrganisationer%7C%7CStatistikmyndigheten%20SCB%20-%20Statistiska%20centralbyr%C3%A5n&rt=dataset%24esterms_IndependentDatalycka till att göra en regex på den
