Community på Sveriges dataportal
-
Nedan delar jag ett inlägg från min kollega Jonas Södergren på Jobtech Development/AF kring nyckelhantering av öppna API:er. (I detta inlägg föreslås inga nycklar, men frivillig registrering via exempelvis detta forum!)
Tillåt anonym användning av öppna apier
Förslaget bygger på principen att det ska vara frivilligt att ange vem man är vid interaktion med det offentligas öppna data, förslaget i sin korthet innebär att:-
det ska vara frivilligt att ange vem man är
-
ett spårbarhets-id kan anges vid interaktion med offentliga öppna API:er ^1
-
offentliga aktörer kan använda DIGG:s forum som utfärdare av id:n för spårbarhet
Definitionen av öppna data säger:
Öppna data är sådana data som vem som helst fritt får använda, återanvända och distribuera med som största motprestation att ange källa eller krav på att dela data på samma sätt.
– Open Knowledge Foundation, en ideell organisation som verkar för utveckling av öppna data [^2]En tvingande identifiering av användare bör ses som icke förenlig med intentionen i PSI-lagstiftningen [^3] och kommande öppna data direktiv 2019/1024. En rimlig tolkning är att det offentliga ska undvika att ställa motkrav på konsumenterna av offentlig information vilket inkluderar identifiering av användaren.
Organisationer som tillhandahåller öppna data vill kunna stävja missanvändning och följa hur öppna data skapar nytta, det blir rimligen svårare när det finns en osäkerhet angående vem som använder ett API. Från användarens synvinkel föreligger oftast behov av att få regelbunden information om kommande uppdateringar och inträffade incidenter etc. Med en genomtänkt arkitektur föreligger ingen motsättning i att tillhandahålla en anonym tillgång och samtidigt ha en dialog med användarna i en separat kanal. Möjlighet att följa användningen och att garantera driftsäkerhet går alltså att kombinera med anonym tillgång till API:et där alternativet att spåra användning erbjuds som ett tillägg.
Förslag till lösning
I korthet innebär lösningen att användaren:kan prova eller använda API:er i produktion utan att ange sin identitet.
frivilligt kan förmedla en identitet som används för att följa användningen och kan vara krav för att erbjuda en högre servicenivå.
kan kvittera ut ett id baserat på sitt användarkonto i Sveriges utvecklarportal [^6].Hur förmedlar användaren sin identitet?
I HTTP-protokollet finns attributet referer [^4]. Detta attribut kan med fördel användas för att förmedla från vilken del av en webbtjänst som anropet görs. Informationen från referer är lämplig att använda för analys, logging med mera.Attribut from kan användas för att frivilligt förmedla en identitet. Ursprungligen användes attributet för att förmedla en e-mailadress. Men i denna rekommendation föreslås en kryptologisk hashad URL (till ett användarkonto) som inte kan återskapas av tredje part. Processen för att hasha URL:en föreslås ske från ett redan öppet forum såsom DIGG:s utvecklarportal där användaren frivilligt har skapat ett användarkonto.
Referer
HTTP headers är ett sätt för en klient att skicka ytterligare information till en server. Mozilla beskriver syftet enligt följande.When making resource requests to another domain, this would be the address of the page using the resource
Exempel på information som kan förmedlas till API:et via en http header:
Referer: https://jobbsajt.se/jobbsök
Vilken del av URL som förmedlas till servern bestäms av den referrer-policy [^5] som klienten väljer.Referrer-Policy: no-referrer
Referrer-Policy: no-referrer-when-downgrade
Referrer-Policy: origin
Referrer-Policy: origin-when-cross-origin
Referrer-Policy: same-origin
Referrer-Policy: strict-origin
Referrer-Policy: strict-origin-when-cross-origin
Referrer-Policy: unsafe-urlFrom
Myndigheter har användarforum för att diskutera med sina användare, antingen i form av den nationella Community på Sveriges dataportal eller domänspecifika som exempelvis Jobtechdev.se/forum. För dessa forum finns redan existerande användarprofiler och det är utifrån dessa användarprofiler som ett spårbarhets-id kan skapas. Attributet from i HTTP specificerar från början en email för den användaren som kontrollerar anropet. Föreslagen lösning är är att användaren av offentliga API:er frivilligt kan ange sin hashade URI som värde i detta attribut.Exempel på http header för en användare
From: 4cdf99d62d21f5f81dd6880e01a5390e
Exempel på hur användaren hämtar sitt id genom att logga in på portalen
Profil på generisk utvecklarportal
Profil på generisk utvecklarportal
1932×442 79.4 KBHur kan DIGG eller annan myndighet skapa ett id för användaren Profil - jonas - JobTech Development forum
echo -n https://forum.jobtechdev.se/u/jonas/ | md5
4cdf99d62d21f5f81dd6880e01a5390e
Notera! Istället för md5 bör kanske sha256 användas och eventuellt med en HMAC (innehåller en privat nyckel) så att inte tredjepart kan återskapa hashsumman från de publika profilerna.echo -n "URI-till-publik-profil" | openssl dgst -sha256 -hmac "hemlig-nyckel" -binary | openssl enc -base64 -A
Lösningen är alltså inte en autentiseringslösning och ska inte heller användas för att bestämma åtkomst till en resurs.En lösning som skalar
Fördelen med att identiteten skapas baserat på att användaren finns i DIGG:s Community på Sveriges dataportal underlättar både för användaren och de myndigheter som tillhandahåller öppna data. Användaren kan skapa ett konto med tillhörande “nyckel” för alla myndigheters API:er samtidigt som myndigheter inte behöver ha en egen kontohantering.Införande
Arbetsförmedlingens plattform jobtechdev.se planerar att prova ovan koncept i Q2 och vi är väldigt intresserade av återkoppling.Referenslista
[^2]: Open Definition 2.1 - Open Definition - Defining Open in Open Data, Open Content and Open Knowledge, 2019-10-16.
[^3]: Lag (2010:566) om vidareutnyttjande av handlingar från den offentliga förvaltningen Svensk författningssamling 2010:2010:566 t.o.m. SFS 2019:943 - Riksdagen
[^4]: Referer - HTTP | MDN
[^5]: Referrer-Policy - HTTP | MDN
[^6]: https://community.dataportal.se/ -
-
@maria_dalhage @jonass När vi jobbar mot Wikimedia servrar i Wikidata finns liknande behov och problemställningar.
De öppna APIerna på Wikidata serverar miljontals svar per månad.
De som använder tjänsterna uppmanas att ge sig till känna genom att höra av sig först. Ytterligare är det ett krav att sätta User-Agent header vilket jag tycker bättre om än att "missbruka" HTTP-Referer.If you want to make a lot of API calls, and perhaps run very busy and active bots, talk to wiki admins ahead of time, so they do not block you. See list of Administrators of Wikimedia projects. Read more about this topic on API:Etiquette.
https://m.mediawiki.org/wiki/API:Etiquette
https://meta.m.wikimedia.org/wiki/User-Agent_policyPersonligt tycker jag det är helt OK att nån bliver blockad om de vill skickar enorma mängder frågor och vägrar identifiera sig på något sätt. IT är en mycket värdefull samhälls-/organisationell resurs som kostar på miljön och det är värt att designa verktyg och program så att de belastar minst möjligt.
Själv får jag ibland skriva om verktyg för jag har helt enkelt skrivit dem för ineffektiva/långsamma. -
@dennis_priskorn GITHUB har valt att ha en rate limiting som känns lite mer mogen approach då man differentierar sina användare
- hur Wikidata används
- Grafana Wikidata Query Service
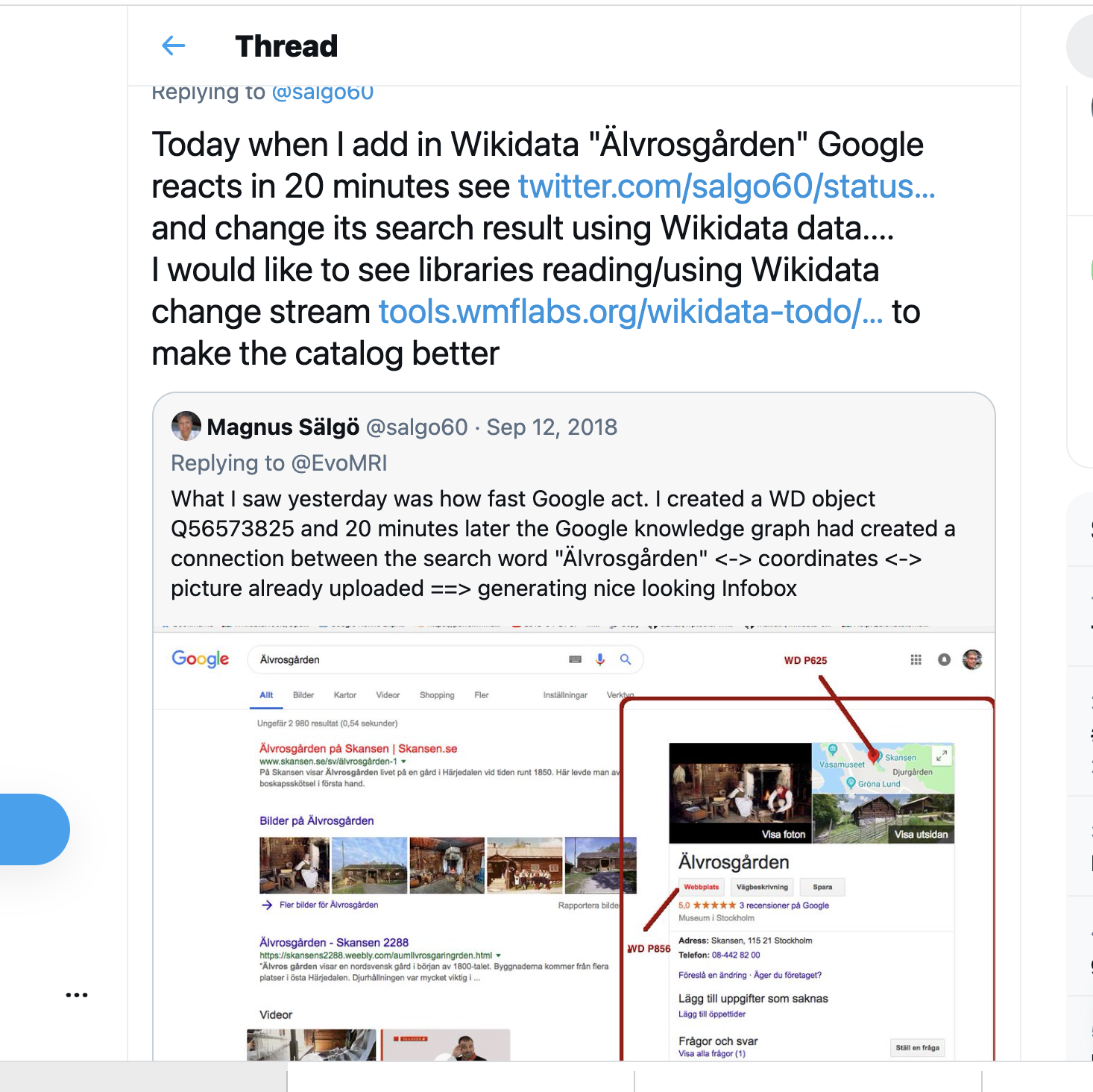
- Wikidata change stream - detta API skapades om jag fattar rätt för att Google webscrapade allt vilket kostade enormt med resurser... se exempel då Google läst en uppdatering 20 minuter efter jag ändrat i Wikidata på ett objekt på Skansens tweet och direkt uppdaterat sin infobox på söksidan...
- hur Wikidata används
-
@dennis_priskorn bra kommentarer. Funkar det bra för Wikimedia borde det vara gångbart även för oss.
-
@dennis_priskorn sa i Anonym användning av öppna apier:
User-Agent
Tack för bra kommentar. Det är dock from jag föreslår att använda istället för User-Agent. Referer föreslår jag att den ska användas som det var tänkt.
-
@salgo60 Driftsäkerhet är en viktig fråga när öppna data tillhandahålls via API:er. Min poäng är i mångt och mycket att api-nycklar inte bidrar till den frågan nämnvärt/enbart. Rate limit är ett mycket bra förslag. Behöver en aktör en väldigt hög tillgänglighet eller prestanda är det inte orimligt att man kontaktar berörd myndighet.
Istället för att enbart reglera tillgänglighet i avtal såsom SLA försöker arbetsförmedlingen också vara öppen med vilken tillgänglighet vi faktiskt har. På det sättet kan konsumenten fatta ett eget beslut om det går att lita på myndighetens API.
Kolla in våran tillgänglighet:
https://statping.jobtechdev.se///Jonas
-
@jonass Precis, när vi började lansera våra API:er och även lanserade betaAPI:er var den vanligaste frågan. "Kan man lite på beständigheten". Ingen vill riska tid och därmed pengar på att utveckla mot något som kan tas bort eller ändras markant på kort tid eller är för instabilt.
-
Behovet av API-nycklar
Jag har lite svårt att förstå syftet med varför API-nyckeln ska behövas. Min magkänsla är snarare att detta är någon slags säkerhetsteater. Dessa är de potentiella syften jag kan utläsa:1. Möjlighet att ur ett driftsäkerhetsmässigt sätt begränsa trafiken mot användare
Om vi inte kan kräva en registrering med identifiering före uthämtning av API-nyckel så finns inte heller en realistisk teknisk möjlighet att med hjälp av API-nyckeln effektivt strypa påverkan på driftsäkerheten. Med min erfarenhet av bl.a. DDOS-attacker på några av sveriges största nyhetssajter så kan jag säga att det bästa sättet är utan tvivel att samarbeta med stora DDOS-skydd eller helt enkelt göra tjänsten så snabb och uppskalad att driften ändå inte blir problemet man behöver lösa med API-nyckeln.Exempelvis med den föreslagna lösningen så ska nycklar inte krävas för tillgång. Då kan man tänka sig att en försvarsmekanism är att när man utsätts för problematisk trafik tillfälligt blockera all trafik som inte har API-nyckel och bara servera till de med API-nycklar. Problemet är att en attackerare kan göra så att det ser ut komma från nästan vilket IP-nummer som helst och dessutom slumpa vilket IP-nummer som används för varje förfrågan. För varje förfrågan så kan även en attackerare generera upp en ny slumpad nyckel eftersom nyckelrymden är stor.
I övrigt anser jag att rate-limiting i kombination med en uppskalad tjänst är hygiennivån för ett öppet konsumerat API precis som @salgo60 föreslår.
2. Möjlighet att debitera för högre servicenivå
I din lösning har du angett alla parametrar som en användare behöver för att med relativt hög grad kunna tillförlitligt gissa sig till en användares API-nyckel(hashas url till användarkonto), det räcker med att jag skapar ett eget konto med en API-nyckel och testa mig fram till vilket krypto som används eftersom jag har all kunskap som behövs eller kan tillämpa statistiska metoder för att gissa salt med mera motmetoder.En alternativ lösning (eftersom centraliserad öppen-data-api-nyckel är en bra idé om API-nyckel krävs för tillgång) skulle kunna vara genererade 2stycken uuid (client_id och client_token) som är helt slumpade men lagrad på ditt community-konto.
Isåfall måste en lista med priviligerade tjänster och deras token etableras som får verifiera client_id och client_token mot en api-nyckels-verifierande tjänst etableras som övriga myndigheter(de priviligerade tjänsterna) kan använda.En vidareutveckling på en sådan lösning skulle kunna vara att den centrala tjänsten tillhandahåller samtliga API-nycklar som en data-källa och en webhook-baserad lösning(förmodligen med en AMQP eller liknande lösning i botten som data-garant) för att kontinuerligt informera de priviligerade tjänsterna om nya och borttagna API-nycklar. Detta skulle lösa ett problem med driftsäkerheten för att vi inte har en single point of failure(SPOF) i API-nyckel-verifierings-tjänsten utan varje myndighet kan ha sin egen instans av den gemensamt ägda öppen-källkods-tjänsten.
Om vi inte skulle se denna API-nyckelslösning som en autentiseringslösning öppnas nämligen en potentiell attackyta där en elak 3:e part kan överanvända api-användarens nyckel vilket beroende på debiteringsmodell kostar den godartade användaren pengar utan att så menades.
3. Möjlighet att för registrerade betalande kunder hålla en separat instans
Detta är en solid anledning att använda någon form av teknisk autentisering eller identifiering. Så att inte en attackerande part påverkar de betalande 3:e parternas prestanda likt det klassiska noisy-neighbour-problemet som är vanligt inom moln-infrastruktur.Angående val av headers
FROM-headern
Jag tycker detta verkar vara ett missbruk av en existerande header. Att använda en header på ett sätt som det inte är avsett är generellt inte att rekommendera. Om ni väljer att skapa upp e-post-adresser som client-id så kan det vara en god idé. T.ex:
<user-uuid>@api-users.dataportal.se. Jag skulle rekommendera att använda from-fältet i kombination med Authorizationfältet som kan innehålla en token, exempelvis en JWT-token om ni vill på något vis scope:a token till vissa öppna API:er då ni kan skicka med scopes i JWT-tokenen och dela den nyckeln till den kryptokrafiska hashen av JWTn's innehåll med priviligerade tjänster.Det står utryckligen i MDN:
You shouldn't use the From header for access control or authentication.
I HTTP-standarden är det ganska tydligt att det borde vara en e-post-adress.
The "From" header field contains an Internet email address for a
human user who controls the requesting user agent. The address ought
to be machine-usable, as defined by "mailbox" in Section 3.4 of
[RFC5322]. -
@stefan-wallin tolkar tråden och ditt inlägg som om flera i forumet är inne på rate-limiting i kombination med en uppskalad tjänst där någon nivå av identifiering förekommer. Tanken med att koppla till Diggs Community är att låta myndigheter lita på varandra och på sina invånare. Säger någon att de är från Jordbruksverket eller IDG så kan vi välja att lita på detta, även om vi inte har krav på eID-lösning. Det är ju fortfarande API:er för öppna data lösningen bygger på. Inte data där vi förväntar oss eller har rätt att ens förvänta oss motprestationer. Däremot har olika API:er i alla fall hos oss olika kapacitet. Lösningen borde då bli att:
- Vill man inte identifiera sig finns det en rate-limiting
- Identifierar man sig genom forumet (som teoretiskt inte behöver vara sanningsenligt, men som vi tror kommer vara det i högre utsträckning än bara en email eftersom det finns incitament till att medverka i communityn) så kan man via forumet kontakta ansvarig för API:et och på så sätt få den kapacitet man behöver, eller att vi blir varse att det finns ett reellt behov av mer kapacitet.
-
Kolla in våran tillgänglighet:
https://statping.jobtechdev.se/Gillar skarpt att ni kör fri programvaran statping och att man tydligt kan se om ni är pålitliga över tid

-
@maria_dalhage sa i Anonym användning av öppna apier:
@stefan-wallin tolkar tråden och ditt inlägg som om flera i forumet är inne på rate-limiting i kombination med en uppskalad tjänst där någon nivå av identifiering förekommer. Tanken med att koppla till Diggs Community är att låta myndigheter lita på varandra och på sina invånare. Säger någon att de är från Jordbruksverket eller IDG så kan vi välja att lita på detta, även om vi inte har krav på eID-lösning. Det är ju fortfarande API:er för öppna data lösningen bygger på. Inte data där vi förväntar oss eller har rätt att ens förvänta oss motprestationer. Däremot har olika API:er i alla fall hos oss olika kapacitet. Lösningen borde då bli att:
- Vill man inte identifiera sig finns det en rate-limiting
- Identifierar man sig genom forumet (som teoretiskt inte behöver vara sanningsenligt, men som vi tror kommer vara det i högre utsträckning än bara en email eftersom det finns incitament till att medverka i communityn) så kan man via forumet kontakta ansvarig för API:et och på så sätt få den kapacitet man behöver, eller att vi blir varse att det finns ett reellt behov av mer kapacitet.
Jag gillar att man enkelt kan komma i kontakt med ansvariga. Jag har inget problem med att min konto härinne används för identifiering på nått sätt när jag använder API:er i det offentliga och vill göra det utan taktbegränsning.
Apropå taktbegränsning så finns det även för inloggade i Wikidatas-miljö eftersom att infrastrukturen (BlazeGraph-grafdatabasen bakom WDQS) skalar undermåligt. Om inte ni har flaskhalsar så låter det bra med noll begränsning.
Apropå begreppet rate-limit, vad heter det på svenska? Jag hittade taktbegränsning i IT-ord och la till det på https://www.wikidata.org/wiki/Q3420050 och använde det ovan.

-
@dennis_priskorn eller kanske bara begränsning
-
 K Kristine_ moved this topic from Tipsa och fråga on
K Kristine_ moved this topic from Tipsa och fråga on