Community på Sveriges dataportal
-
@jonor sa i Identifierare och relationer:
Intressant med sidan med täckningsgrad för egenskaperna, jag hade själv börjat tänka i de banorna hur man kunde få en översikt över hur komplett information är inom ett område.
I en öppen community som Wikidata är kvaliten ett problem, särskilt om det inte finns bra öppen data från auktoriteter. Du har en bra sessions från 2019 där Lydia Pintscher pratar om hur dom tänker en annan intressant aspekt är att data i Wikidata är enkelt att använda så många forskar på Wikidata se scholia.toolforge.org/topic Wikidata lista senaste forskningsrapporter
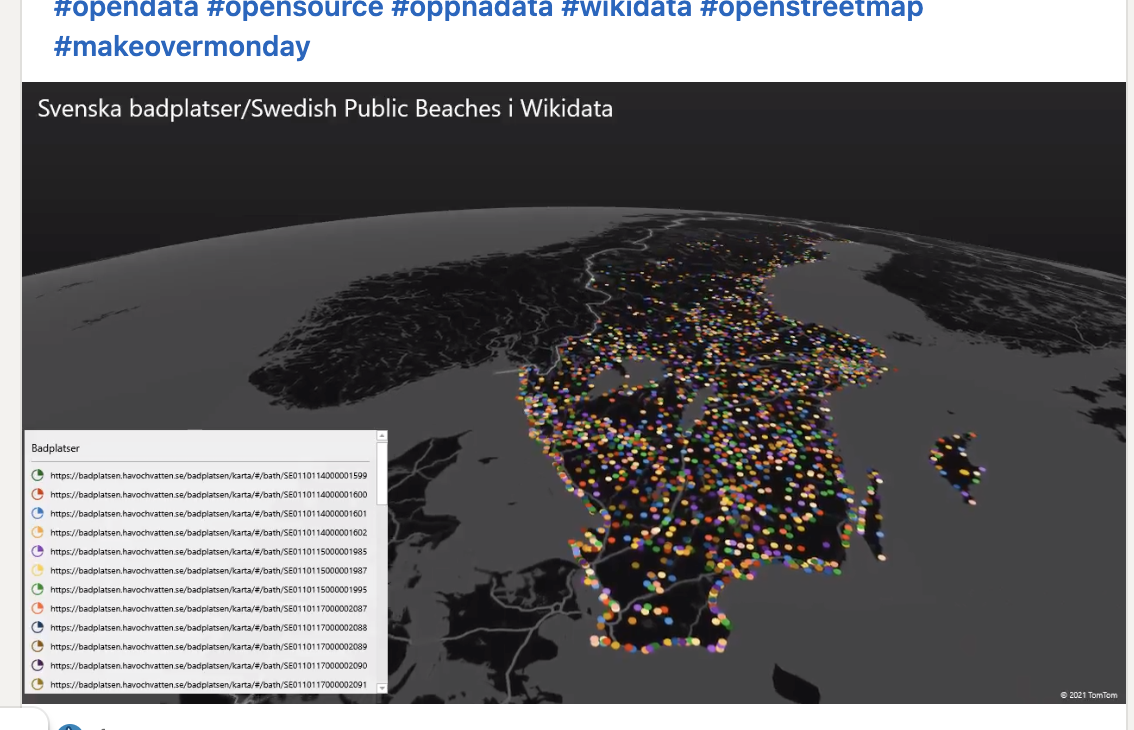
OT exempel hur datat hämtats av andra är att nu har data från WIkidata om svenska badplatser hämtats av en A Elias och visualiserats snyggt
-
@salgo60 sa i Identifierare och relationer:
@jonor det var ett infall jag hade.... jag hade kollat på data.europa.eu (EDP) se min Jupyter Notebook och dit skickar svenska dataportalen text strängar med språkkod vilket är helt fel 2021

Fick inget svar av dom varför dom gör så fel.... ställde senare en fråga på en workshop se video om att Google Dataset Search Engine har kunskapsgraf min fråga vid 54 min om att EDP springer åt fel håll som skickar textsträngar. Särskilt när det är Europiska dataset med massor med olika språk.... gissar att ordet kommuner inte är självklart i hela Europea utan bättre kommunicera med en graf
Jag har försökt lyfta detta på GITHUB DIGGSweden/DCAT-AP-SE/issues/84 men får en sur bismak att den specen drivs för att passa Metasolutions produkt plus att DIGG känns för svaga på kunskapsgrafer och att förstå länkade data så dom kan inte driva detta mot EDP.... känns som Open Data har svårt att lämna startblocken....
/med hopp att jag har fel
@salgo60
Metadataspecifikationen är en anpassning av W3C DCAT - EU:s DCAT-AP. Den svenska anpassningen och tolkningar har gjorts i samarbete i en referensgrupp av experter, som även står omnämnda i specen. Sen är den informationsmodell inte "perfekt", men där är Sveriges linje att i första hand följa och bidra till utvecklingen på EU-nivå snarare än att uppfinna något själva.Det finns säkerligen mycket outforskat gällande hantering och användning av nyckelord. Det kommer från W3C-specen. Det får isåfall utvecklas i kommande versioner av W3C och i takt med utvecklingen inom EU-kommissionen.
Den issue du hänvisar till på github gäller frågeställningar som relaterar till att tillgodose lagkrav i lagen om digital offentlig service. För detta ska organisationer som publicerar metadata även uppge språkangivelse på metadatan. Annars kommer språkuppläsningsverktyg inte fungera på ett bra sätt. Det är lagkrav och något som vi och andra som publicerar till dataportalen ska förhålla sig till. Propertyn language kommer från W3C DCAT så återigen det är inte heller någon som DIGG har hittat på själva.
Vänliga hälsningar,
Kristine -
@Kristine_ @salgo60 Hej, jag är inte helt med i vad det här exemplet med fältnamn på svenska i EU-dataportalen gäller. Är fältnamnen värden för något annat metadata-fält? Går det att förtydliga eller konkretisera var och hur problemet uppstår, t.ex. vad som skickas från dataportalen.se och var det hamnar i EU-datan, om det nu fortfarande är aktuellt?
@salgo60 sa i Identifierare och relationer:
@jonor det var ett infall jag hade.... jag hade kollat på data.europa.eu (EDP) se min Jupyter Notebook och dit skickar svenska dataportalen text strängar med språkkod vilket är helt fel 2021
Källan till exemplet från EU:s dataportal verkar inte fungera.
https://www.europeandataportal.eu/data/api/datasets/https-catalog-skl-se-store-1-resource-38.jsonld?useNormalizedId=true&locale=en=> Parameter catalogue and useNormalizedID are both missing. Please set one of them.
@kristine_ sa i Identifierare och relationer:
. Det är lagkrav och något som vi och andra som publicerar till dataportalen ska förhålla sig till. Propertyn language kommer från W3C DCAT så återigen det är inte heller någon som DIGG har hittat på själva.
Propertyn language som refereras gäller för "Catalogued Resource", men det exemplifieras i definitionen med värden för titel eller beskrivning, inte för fältnamn.
https://www.w3.org/TR/vocab-dcat-2/#Property:resource_language
Definition: A language of the item. This refers to the natural language used for textual metadata (i.e. titles, descriptions, etc) of a cataloged resource (i.e. dataset or service) or the textual values of a dataset distribution
-
Jag tolkar det som att det som @salgo60 refererar till är huruvida det är lämpligt att ha fritextfält som "nyckelord" . Vi tycker att det skulle vara positivt om man skulle inkludera fler standardiserade vokabulärer och djupare kategorisering än vad som idag erbjuds. Sedan är det en balansgång då DCAT är tänkt att vara domänövergripande, och är därmed inte framtagen att täcka in alla domäner på en detaljerad nivå. Som ni har varit inne på tidigare så drivs utvecklingen framåt både vad gäller standarder, identifierare och vokabulärer inom EU vilket är positivt.
Propertyn Language används vid fritextfälten. Vår rekommendation är att man ska översätta fritextfält (som t.ex titel och beskrivning) till åtminstone engelska. Men det finns även andra fritextfält. För de fält där man väljer mellan färdiga värden, t.ex. kategorier i form av URI:er, så finns redan översättningar till olika många språk.
Just att de säger "catalogued resource" handlar om att datamängder och tjänster är katalogiserade. Enligt DCAT är det katalogen är det som "omsluter" alla resurser som delas. Varje "nivå" i katalogen beskriver man enligt den gemensamma specifikationen. Logiken är att i katalogen beskriver man sina resurser i form av datamängder och datatjänster (API:er) . Datamängderna kan i sin tur ha en distribution som pekar ut vart/hur man får åtkomst till datan, t.ex via en fil, ett API, en webblänk etc.
Lite osäker på vilken källa din länken hänvisar till så förtydliga gärna det så kan jag kolla på det. Har upptäckt att det är lite olika saker som vi behöver adressera med europeiska dataportalen, så vi uppskattar era konkreta exempel som vi kan felsöka. Tack för er återkoppling.
För mer info; till de som publicerar metadata till Sveriges dataportal finns följande rekommendation om språk och språkangivelse:
https://docs.dataportal.se/dcat/docs/recommendations/#2-oversatt-fritextfalt-till-andra-sprak
https://docs.dataportal.se/dcat/docs/recommendations/#12-sprakangivelseVänliga hälsningar,
Kristine -
@kristine_ Ok, det är väl de här mojängerna i metadatan som hämtas in då, jag hade inte förstått att det handlade om nyckelord just. Istället för att rada upp översättningar av ämnesorden skulle man då kunna använda eller komplettera med identifierare som lät dataportalen söka och koppla nyckelord mer effektivt, oavsett de språk de angetts bokstavligt i.
<dcat:keyword>Myndigheten för digital förvaltning</dcat:keyword> <dcat:keyword xml:lang="sv">Inköp</dcat:keyword> <dcat:keyword xml:lang="en">Purchase</dcat:keyword> <dcat:keyword xml:lang="sv">Leverantörsfaktura</dcat:keyword> <dcat:keyword xml:lang="en">Supplier invoice</dcat:keyword> <dcat:keyword xml:lang="sv">Anskaffning</dcat:keyword> <dcat:keyword xml:lang="sv">Procurement</dcat:keyword> -
@jonor Det ser ut att finnas en egenskap i DCAT för koncept-referenser till skillnad från bokstavliga värden, men jag vet inte hur den används i praktiken, man ska gå via ett tillgängligt skos:ConceptScheme?
https://www.w3.org/TR/vocab-dcat-2/#Property:resource_theme
RDF Property: dcat:theme
Definition: A main category of the resource. A resource can have multiple themes.
Range: skos:Concept
Usage note: The set of skos:Concepts used to categorize the resources are organized in a skos:ConceptScheme describing all the categories and their relations in the catalog.https://github.com/w3c/dxwg/issues/121#issuecomment-375074957
dcat:theme would always be preferred if a suitable SKOS ConceptScheme is available because you can more precisely test if different datasets are classified with the same skos:Concept, while dcat:keywords would involve text comparisons. But people still need to enter keywords as free text sometimes. Yes - more textual guidance is always helpful.
-
@jonor
Precis. Det finns en standardiserad kategorisering inrymd i den europeiska applikationsprofilen av DCAT via Theme/ sv Kategorier. Det är denna som ligger till grund för de olika kategorierna på startsidan samt filtret i sökfunktionen. Theme/Kategori är alltså en Proporty vars värde är ett begrepp (skos:concept).Det är rekommenderat att ange ett eller flera teman för varje datamängd. Dessa teman är framtagna för att kunna skapa en första grov indelning. De teman som etablerats syftar till att vara lättförståeliga, hänga samman ämnesmässigt samt också skapar en någorlunda jämn fördelning av datamängder. Tyvärr räcker dessa 13 teman inte särskilt långt för att kategorisera datamängder, t.ex. det är helt klart att det finns många olika subkategorier inom t.ex trafik eller miljö som skulle kunna användas för att filtrera fram relevanta datamängder. På sikt kan man fundera på hur vilket sätt som fler eller djupare ämneskategoriseringar kan stödjas i Sverige. Det är något som vi har berört i olika sammanhang men har ännu inte något skarpt case. Allra helst vill vi såklart att EU driver detta så att man får alla medlemsländerna att gå åt samma håll.
-
@kristine_ Ja 13 kategorier låter kanske torftigt, kan inte dataleverantörer länka in begrepp från etablerade vokabulärer inom sina egna verksamhetsområden?
-
Min bild är att DCAT-AP idag inte stödjer fler vokabulärer än vad som uttryckligen står i specen. Om vi skulle stödja fler vokabulärer eller skapa något fält som fungerar som key words, men som är t.ex länkar istället för fritext, skulle det vara en nationell utvidgning av specen.
Jag tar med mig frågan genom att skapa ett issue på DCAT-AP github yta här: https://github.com/DIGGSweden/DCAT-AP-SE/issues/86.
På så vis när specen står inför en uppdatering nästa gång tar vi med och behandlar den frågan.Vänliga hälsningar,
Kristine -
@kristine_ I en annan tråd nämns vikten av att skapa interoperabla data.
DIGG seminarium: Öppna data för nybörjare:
Vi har satt ganska stort fokus på vikten av att skapa interoperabla data men inte gått ner exakt på hur man gör det eftersom inte alla kommer att vara inblandade på den tekniska nivån, och detta står också i våra vägledningar (även om det kan bli mer utförligt). Vi ser inte att alla som kommer att vara inblandade i arbetet med öppna data behöver vara på Github, därför har vi inte med det i den här översikten av öppna data.
API-dokumentationen ger ett exempel på datamängder per organisation (det enda någorlunda enkla exemplet på API-anrop jag hittade, de flesta andra verkar bestå av komplicerade sökuttryck som ger indirekta resultat).
Jag antar att "values" i resultatet representerar de URI:er som registrerats för respektive organisation eller utgivare. Vissa utgivare ser ut att ha organisationsnummer enligt någon auktoritet (t.ex. id.kb.se/orgnr för SCB och Huddinge kommun), medan andra refererar till utgivarens webbplats eller någon resurs under denna, och återigen andra har applikations-relaterade URI:er under dataportal.se eller andra instanser av någon dataportal med liknande programvara (Nobel Media har en URI som ligger under dcat-editor.com/store/17/resource/1).
https://docs.dataportal.se/registry/api/#skordningsstatus
Den som är nyfiken över hur många datamängder det finns per organisation kan göra följande anrop: https://admin.dataportal.se/charts/orgData.json
"labels": [ "Statistikmyndigheten SCB - Statistiska centralbyrån", "Pensionsmyndigheten", "Umeå Energi", "Naturvårdsverket", "SMHI - Öppna Data", "Stockholms stad", "Trafikverket", "Huddinge kommun", ... "Tomelilla kommun", "Länsstyrelsen i Norrbottens län", "Sounds of Changes", "Nobel Media", "Sörmlands museum", "Falbygdens museum", "Hemsö fästning" ],"values": [ "http://id.kb.se/organisations/SE2021000837", "https://pensionsmyndigheten.se/publisher1", "https://admin.dataportal.se/store/43/resource/fd2584866d01e4eaee64e3ffcfe40e02", "https://admin.dataportal.se/store/635/resource/9de761c624866bdca2f2e6ccdeba9815", "https://www.smhi.se/data/utforskaren-oppna-data", "https://admin.dataportal.se/store/733/resource/d73b9d8c4334e31634836a2610ef4ff7", "https://resources.geodata.se/metadata#foaf/Trafikverket/", "http://dataportal.se/organisation/SE2120000068", ... "https://data.tomelilla.se/store/1/resource/6", "https://admin.dataportal.se/store/635/resource/3b8d0533349a7311f7f47efa0767f468", "http://www.soundsofchanges.eu/", "https://dcat-editor.com/store/17/resource/1", "https://www.sormlandsmuseum.se/", "http://www.falkoping.se/museet", "http://www.hemsofastning.se/" ], "datasetCount": 7243, "publisherCount": 162Jag stötte på ett formulärbibliotek med namnet RDForms som verkar relaterat till EntryScape. Om det är så att RDForms används för att registrera datamängder på dataportalen enligt DCAT-formatet, så kanske det kan finnas ledtrådar i konfigurationen av dessa formulär att metadatan ser ut som den gör. Åtminstone i det exempel jag stötte på nedan ser det inte ut att finnas någon stödfunktion för att ange referenser.
https://rdforms.com/editors/dcat/
Finns det några tankar kring vidareutveckling av interoperabilitet för metadatan och samordning av detta?
Som @salgo60 var inne på tidigare i tråden så blir det väl inte mycket till länkad data om alla hittar på egna referenser huller om buller.
-
@jonor sa i Identifierare och relationer:
Finns det några tankar kring vidareutveckling av interoperabilitet för metadatan och samordning av detta?
Om jag ska försöka förtydliga mig så har flera förfrågningar har gjorts i forumet efter kopplingar mellan datamängd och organisation, och det har även påpekats att det behövs någon som tar ansvar för förvaltningen av unika identifierare.
Kan DIGG bidra med något i frågan om hur referenser för organisationer i metadatan ska se ut? Jag har svårt att förstå hur de ska användas för detta i sin nuvarande form.
Mer allmänt, hur ser ansvarsbilden ut idag för att publicerad data uppfyller kvalitetsnivåer gällande identifierare och användbarhet?
-
När jag läser tillbaka i tråden ser jag att svar redan getts delvis, men jag hade nog inte formulerat frågeställningen för mig själv vid det laget.
Som en följdfråga, pågår det någon aktivitet i nuläget med vägledning för och samsyn kring tillämpning av identifierare? Finns det kanske konkreta exempel på hur identifierare används hos de refererade institutionerna?
Det skulle fortfarande vara intressant att höra hur man ser på en policy för identifierare för organisationer för dataportalen. När det gäller datan för leverantörsfakturor verkar det redan förekomma etablerade identifierare t.ex., medan det är ett frågetecken gällande registret över datamängder.
@josefinlassi sa i Identifierare och relationer:
I dagsläget har vi tyvärr inga konkreta exempel eller mer information än det som står i vägledningen.
...
Vi har sett ett behov av att ta fram en tydligare vägledning kring detta och att förankra den hos ett antal centrala aktörer i frågan. Bla Riksarkivet/Riksantikvarieämbetet, MSB och SND (Svensk nationell datatjänst, en portal för forskningsdata) har ju idag lite rekommendationer som inkluderar beständiga identifierare. Och det vore fint om vi kunde få till lite samsyn kring en rekommendation om hur man ska gå tillväga med detta:) Men vi är inte där ännu. Kanske några fler i den här tråden kan hjälpa dig vidare? -
@jonor tycker eionet gör det snyggt med identifierare se bathingWaterIdentifier där man är tydlig "Methodology for obtaining data"
Must be a valid bathing water identifier in the "WFDProtectedArea" registry
-
i mitt hobby Projekt svenska badvatten försöker vi skapa denna i Wikidata tillsammans med Naturkartan, Badkartan IN OCH RÖSTA UPP alla kan vara med och Wiki världen är duktiga på att hantera versioner av data länk exempel, diskussionssidor, enkelt prenumerera/ pinga andra - saker som behövs om löst kopplade system/ personer/ organisationer skall kommunicera vilket TYVÄRR svenska myndigheter, kommuner verkar vara..:
-
personlig fundering badplatser varför låter man kommuner skicka in koordinater som finns på land och varför finns ingen kvalitetssäkring med Lantmäteriet och varför skickas dålig data till EU. Och varför ställs inte krav på Lantmäteriet att för badplatser ha id = bathingWaterIdentifier
- saker vi hittat när man kollar på datat
- fel loggade med just koordinater vi inte tror på
- felet är även spårbart på objekt i Wikidata se SPARQL som hittar objekt för badplatser vi satt lägre rang på för att vi som lekmän inser att här vill vi inte bada
- alla dessa fel skickas sedan utan kvalitetssäkring till EU som inte heller kvalitetssäkrar sakerna känns mer och mer som DN artikeln är allt för sann
- saker vi hittat när man kollar på datat

-
-
J jonor referenced this topic on
-
 M Maria_Dalhage moved this topic from Tipsa och fråga on
M Maria_Dalhage moved this topic from Tipsa och fråga on