Community på Sveriges dataportal
Här kommer höstens NOSAD- workshops!
-
Agendan är i skrivandets stund endast satt för september vilket innebär att det finns en stor möjlighet att påverka innehållet för övriga tillfällen.
Höstens workshoptillfällen
7 september kl 10-12: Samarbete kring gemensamma och öppna resurser inom Trafik- och mobilitetssektorn
5 oktober kl 10-12: (innehåll spikas närmaste veckorna, se lista nedan)
2 november kl 10-12: (innehåll spikas närmaste veckorna, se lista nedan)
7 december kl 10-12: (innehåll spikas närmaste veckorna, se lista nedan)Lista på workshopsämnen.
(Rösta eller lägg till eget förslag.)
• Feedbackworkshop på DIGG:s API-byggblock/ Playbook
• eArkiv Open Source
• IT-säkerhet och open source
• AI och öppna algoritmer.Det är deltagarna som gör forumet. Där innehållet ej är satt finns möjligheter att även påverka workshoptemat. Bokning av eventen kommer att kunna ske under nästa vecka.
NOSAD (Network Open Source and Data) är ett nätverk för oss som arbetar med eller använder sig av myndigheternas öppna data. Höstens digitala workshops sker första tisdagen varje månad mellan kl. 10-12.
-
@maria_dalhage Hur/var röstar vi?
-
@lfvjimisola Min tanke var att i forumet skriva vad man helst vill se så att det blir en diskussion.
")
-
@maria_dalhage sa i Här kommer höstens NOSAD- workshops!:
Lista på workshopsämnen.
(Rösta eller lägg till eget förslag.)
• Feedbackworkshop på DIGG:s API-byggblock/ Playbook
> • eArkiv Open Source
• IT-säkerhet och open source
• AI och öppna algoritmer.Röstar på de fetstilta. Tänker att diskussion om API-byggblock / playbook kan ha en tråd här på forumet.
-
Nu finns bokningslänkar till höstens alla NOSAD-workshops!
För mer information gå in på http://nosad.se
Endast september och oktobers ämnen är spikade så det finns alla möjligheter att påverka innehållet.
🧨 7 september: https://lnkd.in/dB4hhyEs
🧨12 okt: https://lnkd.in/dCyt-4YG
🧨2 nov: https://lnkd.in/duBGtPgS
🧨7 dec: https://lnkd.in/dnr_JYEz
-
@maria_dalhage tackar
var kan man läsa mer om DIGG API-byggblock/ Playbook vad tanken är? Testa det dom levererat?
Det jag ser med kommuner och Öppna data är att inget händer se lista med kommuner som lyckats skapa en PSIData katalog där 90% verkar bara peka vidare på Kolada data dvs. princip skapar inget Öppna data... just nu har vi lyckats hitta 129 stycken kommuner jämfört med 3 nov 2020 var det 116 stycken
Karta med 156 kommuner som inte ens kan peka på Kolada datat för kommunen.... eller peka på Wikipedia som förklarar vad Öppna data är
")
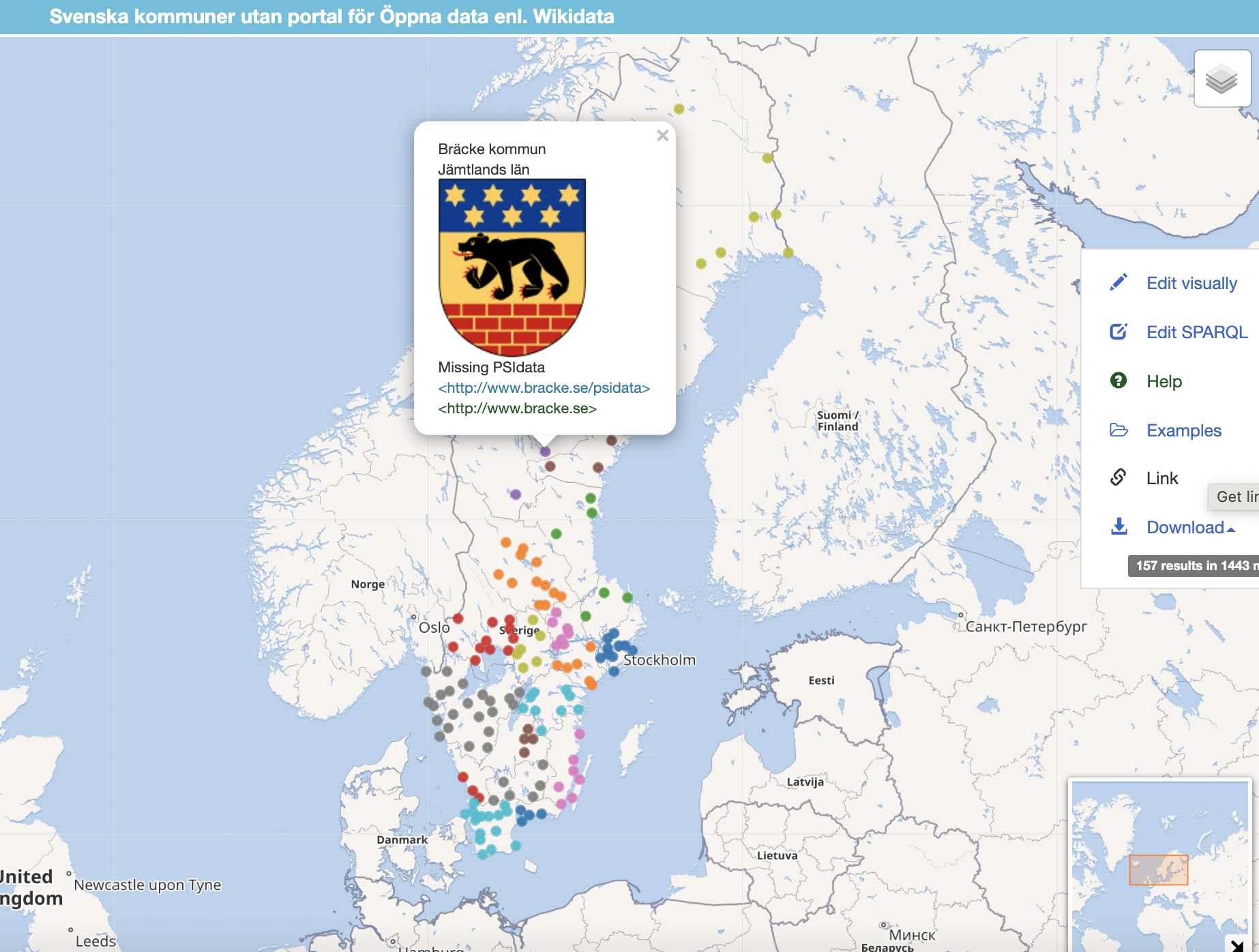
Frågan är om det är ett API byggblock som är det stora problemet eller hur går tankarna hos dom som tar ansvar för att detta skall lyckas... det jag ser från utsidan så känns det som det saknas någon som styr upp detta och driver på.... känns som en root cause analysis behövs ... tanken att Sverige skall bli bäst i världen verkar ha fått en reality check och sakta drabbats av scope creep
-
@salgo60 Läs mer om DIGG:s uppdrag för API-hantering här: https://www.digg.se/4907ac/globalassets/dokument/utveckling-av-digital-forvaltning/digital-infrastruktur/informationsutbyte_byggblocksbeskrivning_apihantering_20210129.pdf
Workshopen är en möjlighet att återkoppla till arbetsgruppen om de utmaningar och behov som respektive organisation har med att dela sin data via API:er.
-
@maria_dalhage Är det konsultbyråer som skriver rapporterna? Det ser ut att vara mycket management-terminologi och maskinöversatt engelska i texten tycker jag.
-
@jonor håller med dig väldigt flummigt hela grejen med detta med Öppna data känns idag målgrupp powerpoint administratörer och inte doers. Vi får se om DIGG eller öppna data projekt vinner bästa API priset
@Maria_Dalhage finns det något att testa innan er workshop?
Jag ser idag att det behövs enormt mycket stöd dels hur saker designas men även då man upphandlar konsulttjänster för att designa saker. Saker blir löjligt dåliga med klipp och klistra i Word specar sedan skickar man en faktura på 16 miljoner och en svag uppdragsgivare tror dom köpt något som egentligen är 10 minuters jobb...
Lite off topic hur snyggt dagens Nobelpris släpps i ett API där personen har id 1003 med samma som Wikidata Q5237001
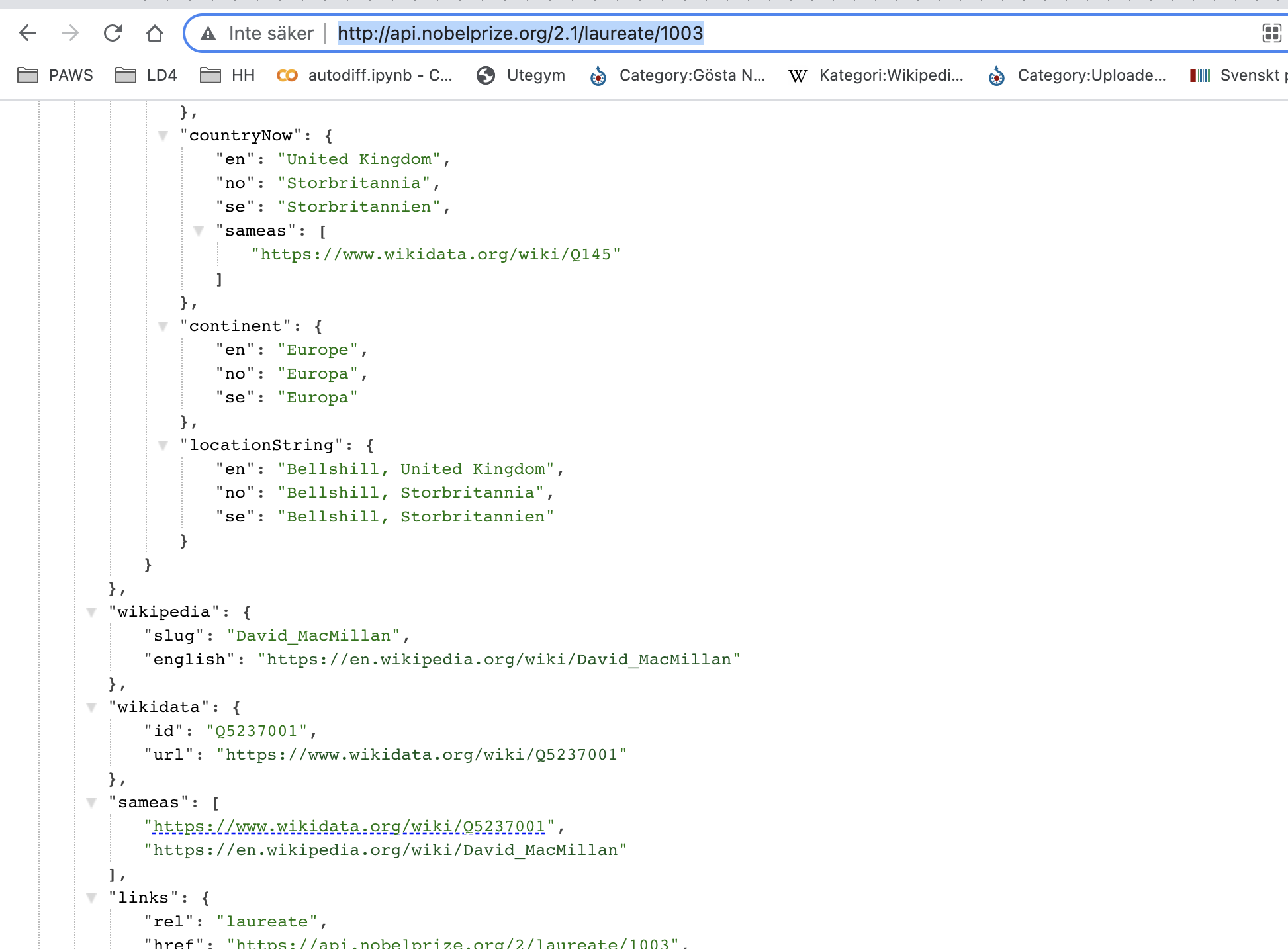
--> att vi i WIkivärlden som har bara på engelsk WIkipedia > 452 tusen dagliga visningar av Nobelpristagare (125 milj/år) kan nu matcha detta automatiskt och sedan har vi många av hans senast publicerade dokument och visar upp det i Scholia som är ett lager på Wikidata --> länk scholia Q5237001 eftersom api.nobelprize.org API:et är nivå 5 se 5stardata.info/ och inte strings utan things blir detta möjligt med ex. co-authors se SPARQL fråga
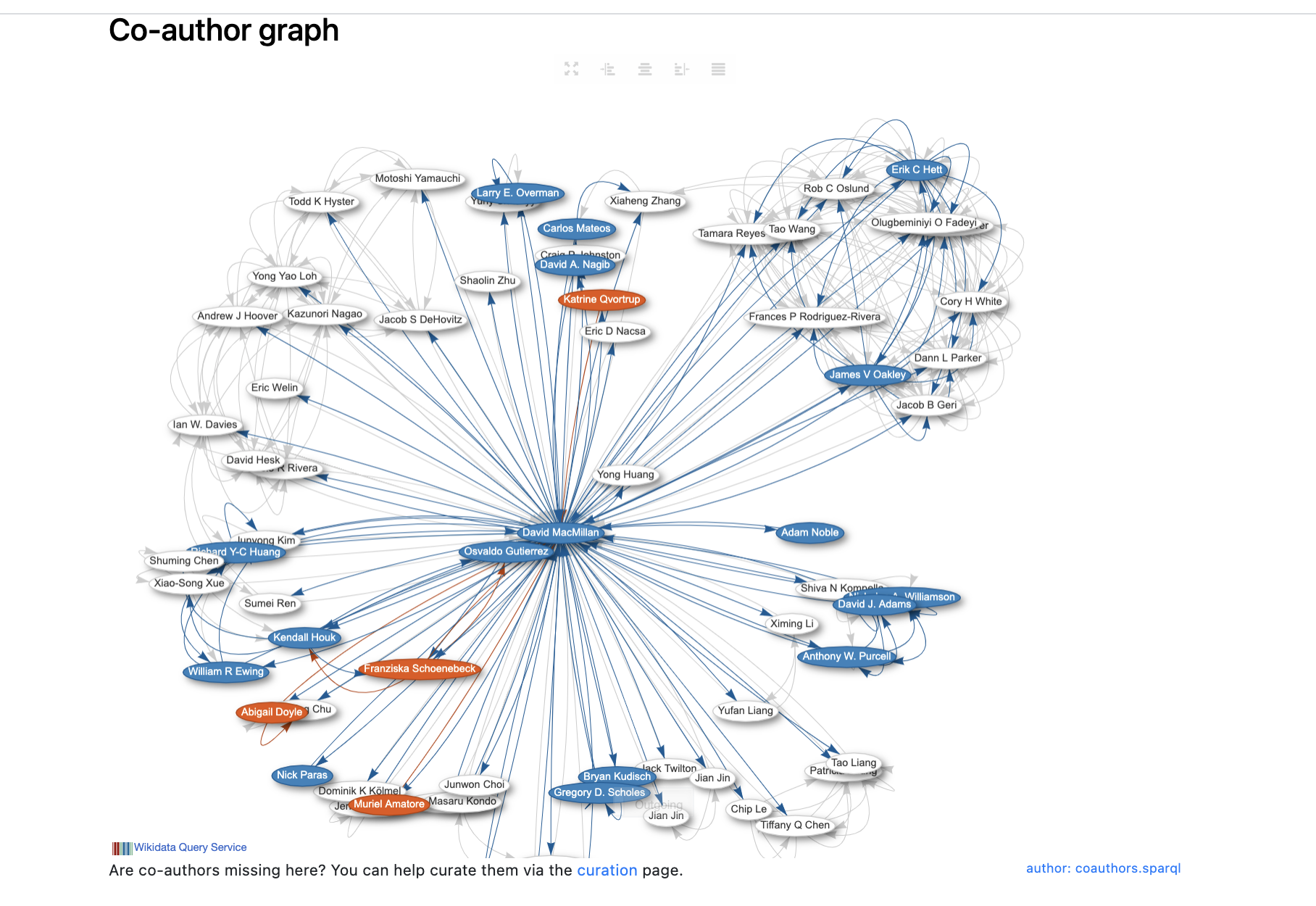
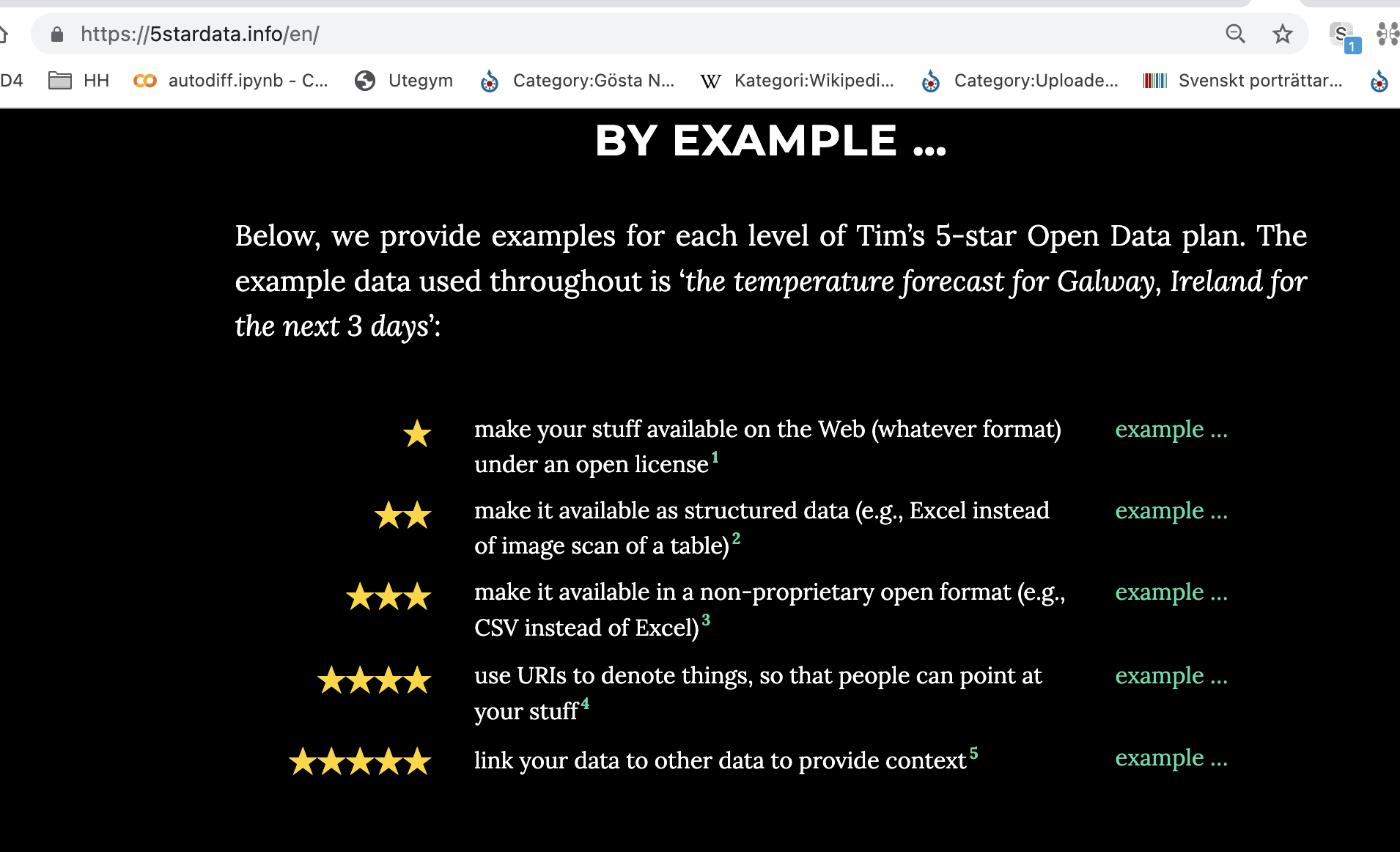
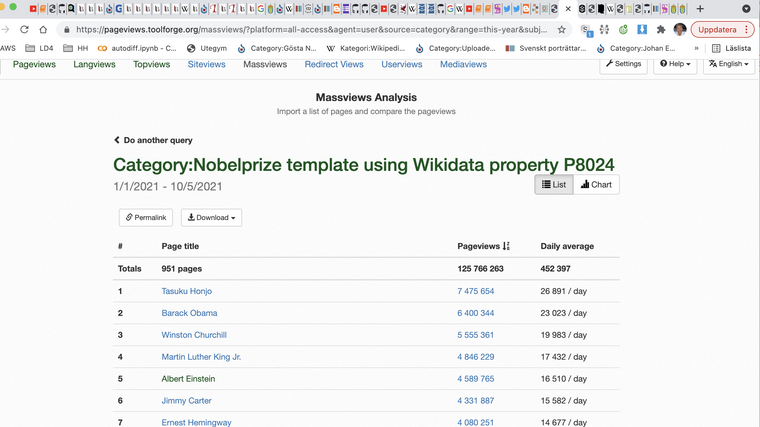
Bygger vi en API design där vi levererar data som things och inte strings skulle vi kunna koppla ihop lika snyggt alla kommuners info om medborgarförslag, eller förslag som jag vill rösta upp, nya utegym nära mig, vad olika kommungubbar tycker om miljöfrågor som jag bryr mig och enkelt skala det till hela världen, när det planeras mat som mitt barn är allergiskt mot etc....
att 2021 köra textsträngar och inte kunskapsgrafer är inte ok.
-
Dagens Nobelpris hade samma som Wikidata
-
Wikidata hade publicerade vetenskapliga papper kopplade till personerna --> citation graphs kan skapas
-
@Dennis_Priskorn kopplar nu på ämnesord på alla vetenskapliga publicerade papper med sitt nya verktyg ItemSubjector --> att datat blir ännu mera värdefullt dvs. vi vet vilka vetenskapliga papper som publicerats senast inom olika ämnen eller vilka som det senaste året är mest citerade inom ett ämne....
- Wikidata status - tool of the week

Varför ser vi Öppna data API:er designas med textsträngar där konsumenten av API:et skall göra jobbet med att koppla det till things känns som rollen API designers måste kombineras med verksamhetskunskap och grundläggande kunskaper av kunskapsgrafer.... nu känns det lite 70-tal med csv filer, textsträngar och inga backloggar...
våga ställ krav är min önskan. Höj statusen på API designers !!!
Ps. morgondagens Nobelpristagare i litteratur blir 1004
-
-
@salgo60 Håller med dig i mycket Magnus. En sak som Arbetsförmedlingen och DIGG konkret har utvecklat är en mjukvara för att underlätta/automatisera publiceringen av API:er på dataportalen.se. Källkod och issues kommer öppnas så att alla kan bidra.
Arbetsförmedlingens lista över sin öppna data uttryckt enligt dcat är skapad med denna mjukvaran. https://data.jobtechdev.se/dcat/
Kunskapsgrafer är bra och kan såklart tillämpas när det är lämpligt. Jag personligen tycker dock att CSV och enkla APi:er är underskattade. En gammal hederlig fil med bestående identifierare för informationsobjekten och ett känd metod för att hämta ytterligare information från andra API:er kommer man långt med.
-
@salgo60 sa i Här kommer höstens NOSAD- workshops!:
Jag ser idag att det behövs enormt mycket stöd dels hur saker designas men även då man upphandlar konsulttjänster för att designa saker. Saker blir löjligt dåliga med klipp och klistra i Word specar sedan skickar man en faktura på 16 miljoner och en svag uppdragsgivare tror dom köpt något som egentligen är 10 minuters jobb...
Har också fått intryck att saker ofta är slarvigt specificerade i Word-dokument med inklistrade skärmbilder av tabeller/listor och liknande, men det finns säkert goda exempel med.
Varför ser vi Öppna data API:er designas med textsträngar där konsumenten av API:et skall göra jobbet med att koppla det till things känns som rollen API designers måste kombineras med verksamhetskunskap och grundläggande kunskaper av kunskapsgrafer.... nu känns det lite 70-tal med csv filer, textsträngar och inga backloggar...
Min fetning av något som jag tycker sätter fingret på ett viktigt mätvärde för nyttan med ett API eller dataset. Hur mycket jobb behöver konsumenten lägga på att tillföra mening, konsistens och fungerande referenser till relaterad data, och som rimligen kunde funnits med när datasetet skapades?
Kunskapsgrafer är bra och kan såklart tillämpas när det är lämpligt. Jag personligen tycker dock att CSV och enkla APi:er är underskattade. En gammal hederlig fil med bestående identifierare för informationsobjekten och ett känd metod för att hämta ytterligare information från andra API:er kommer man långt med.
Ett problem med CSV verkar vara att variationer i formatet ofta kräver analys från konsumenten, vilket ger minuspoäng enligt resonemanget ovan om att belasta konsumenten med tolkningsarbete. Anses det rimligt att CSV publiceras med Win-1252 teckenkodning, semikolon-avgränsare och kommasepararerade talvärden t.ex. utan att metadata specificerar detta? Finns det standardiserade protokoll för att analysera sådana variationer i formatet automatiskt, eller krävs manuell besiktning och konfiguration för att tolka datan korrekt?
-
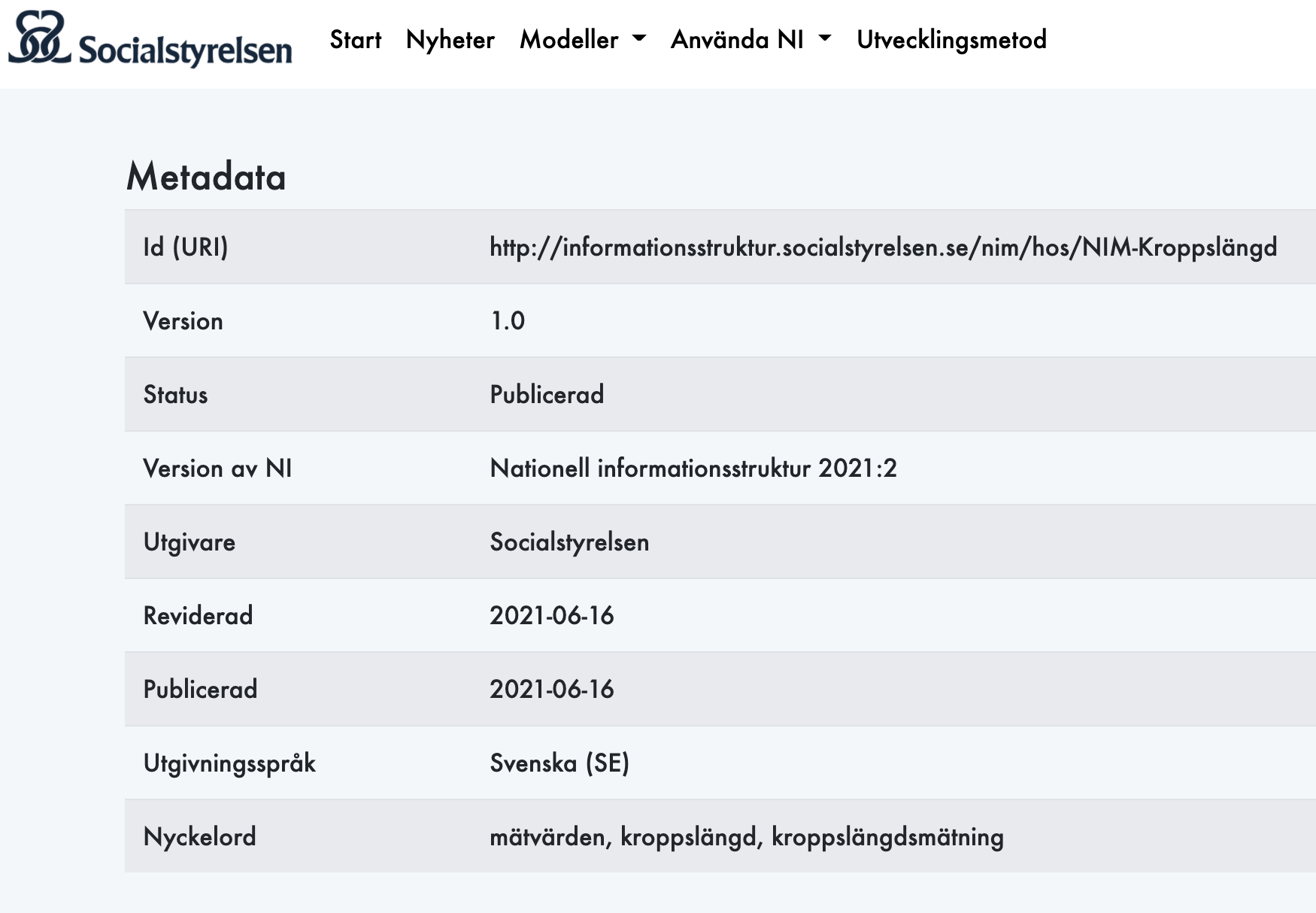
@jonor tycker Socialstyrelsen specar vettigt utan att jag är domänkunnig ex. nim/hos/NIM-Kroppslängd sedan kan man fundera varför det bara verkar vara på svenska...
-
@jonass sa i Här kommer höstens NOSAD- workshops!:
Kunskapsgrafer är bra och kan såklart tillämpas när det är lämpligt. Jag personligen tycker dock att CSV och enkla APi:er är underskattade. En gammal hederlig fil med bestående identifierare för informationsobjekten och ett känd metod för att hämta ytterligare information från andra API:er kommer man långt med.
Kunde vara intressant för övrigt att höra mer om vilka metoder för att hämta ytterligare information från andra API:er du tänker på, och hur de eventuellt liknar eller skiljer sig från kunskapsgrafer.
-
@salgo60 : Ser att Jonas redan svarat.

Som oftast inför en workshop eller liknande fixas det med underlag och agendor i sista minuten. Gäller även här… -
@salgo60 Föredömligt av öppna skolplattformen!
Gällande NOSAD -workshops har vi en utmaning i att producera intressanta och aktuella ämnen med relevanta och kunniga talare från flera olika organisationer. Det är en lyx att vi har en attention som gör att organisationer - privata som offentliga - vill presentera sina resultat och erfarenheter på våra workshops. För att skapa framförhållning så har vi publicerat "place holders" tidigt, men innehållet arbetas fram löpande. Det innebär att för vissa workshops finns ganska lite planeringstid. Jag tänker att detta är ok, eftersom alternativet skulle vara betydligt färre workshops. Jag tror att dessa workshops är bra och skapar en viktig yta att diskutera på. En plats där de som tar fram API:er och öppna data och de som använder dessa kan förstå varandras synsätt och behov.
Jag är övertygad om att flertalet verksamheter (även offentliga) arbetar med sprintar och via agila metoder. Det du slår huvudet på spiken med handlar nog egentligen inte om avsaknad av agila metoder utan avsaknad av transparens. Alltså en kulturfråga. Internt finns mkt framtaget, men det är inget man släpper externt. Det vore kostnadseffektivt om vi kunde hitta sätt att arbeta mer transparent på!
-
@maria_dalhage ni skall ha all kredit.... kanske en rädsla att få feedback.... det är inte kul när @Dennis_Priskorn säger det är skitdata.... vi ser inom kultursektorn att man kan producera "skit data" i massa år eftersom ingen "kritiserar någon annan" - kulturproblem....
det jag tycker mig se är att sitta och utreda i 2 år utan feedback eller utan del leveranser brukar vara mindre bra... vill dock säga att bara för att man har en agil metod så är det ett bra team som är det viktiga....
Att bli bäst i världen på Digitalisering betyder även att man är noga hur man tar ut laget
-
En före detta användarereplied to En före detta användare on Senaste redigerad av En före detta användare
@salgo60 nu kom Nobelslitteraturpristagare id = 1004 samma som Wikidata Q317877
-->
- ryska Wikipedia direkt länkar Nobel pga att dom är datadrivna se Гурна,_Абдулразак


Tänk om
- öppna data om jobb hade samma som för
** platser
** skills
** yrken - öppna data om kommuners beslut hade samma som för
** Corona
** miljöbeslut
** ...
vi skulle öka tillgänligheten 1000 ggr och kunna leverera på 300 språk precis som nobelprize.org och wikidata gör....
-
@jonass sa i Här kommer höstens NOSAD- workshops!:
Kunskapsgrafer är bra och kan såklart tillämpas när det är lämpligt. Jag personligen tycker dock att CSV och enkla APi:er är underskattade. En gammal hederlig fil med bestående identifierare för informationsobjekten och ett känd metod för att hämta ytterligare information från andra API:er kommer man långt med.
+1 Jag håller helt med. CSV är bra. Lätt att läsa (likt valid JSON) och arbeta med. Dock måste API:erna versioneras! Om ni tex. lägger till fält så behåll den gamla API versionen ett tag och gör en ny med ny endpoint. Se tex www.sello.io som är på version 5 (ägs av Ebay, och verkar ha skarpa folk anställt som snabbt svarar om man har frågor).
Beständiga unika identifierare kan man inte få för många av. Jag tänker att mycket av det data som svenska myndigheter sitter på skulle kunna beskrivas (inte publiceras) i en kunskapsgraf.
Ett exempel är typen av leder som naturvårdsverket har i sitt data här, se tabell 5 i denna pdf. Denna data delas inte bäst i en PDF, utan när jag vill maskinläsa datan, så önskar jag att lederna istället pekar på en "thing" som jag kan begripa mig på.
Tex skulle denna tabell kunna göras om så att en statlig led beskrivs som:
- led som sköts av Naturvårdsverket direkt
där Naturvårdsverket är en "thing" som tex pekar på http://www.wikidata.org/entity/Q2976522
I den bästa av världar så skulle Naturvårdsverket ta sitt uppdrag med leder så seriöst att de för varje led har en "thing" i en grafdatabas där de beskriver leden:
- typ av led ->"thing"
- start punkt (koordinat)
- slut punkt (koordinat)
- har del-> "thing" om den har faciliteter längs vägen eller består av flera del-leder.
- datum för senaste underhåll
- klassning av kvalitet-> "thing" <- kan användas internt för att höja kvaliteten överlag på lederna som administreras
- klassning av framkomlighet för rullstol->"thing"
- peka på leden i WD om den finns där-> sameAs->QID
- ....
Alternativt kan de publicera det ovanför som CSV, men min gissning är att det bliver svårare att administrera. Bättre att ta steget in i en grafdatabas direkt. Se https://wikibase.consulting/ där det finns proffs som kan hjälpa med modellering, hosting, etc. En POC kan nog göras på 2 veckor om man bara vill...
- led som sköts av Naturvårdsverket direkt
-
@maria_dalhage sa i Här kommer höstens NOSAD- workshops!:
Jag är övertygad om att flertalet verksamheter (även offentliga) arbetar med sprintar och via agila metoder. Det du slår huvudet på spiken med handlar nog egentligen inte om avsaknad av agila metoder utan avsaknad av transparens. Alltså en kulturfråga. Internt finns mkt framtaget, men det är inget man släpper externt. Det vore kostnadseffektivt om vi kunde hitta sätt att arbeta mer transparent på!
+1 jag förordar radikal transparens likt Audrey Tang. Det kan vi bara få om ledningskulturen (i detta fall Regeringen) inbäddar det och visar vägen framåt. Det skulle innebära en ordentlig kulturförändring. Vissa medarbetare kanske får gå för de klarar inte omställningen. Nya IT-system och rutiner kanske behövs för de som används i dagsläget klarar nog inte av säkerhetskraven för de är byggt för att köra bakom en firewall i en källare med endast interna användare.
Dvs. detta är en mycket stor förändring. Min gissning är att den bara kan ske om den ges i form av direktiv från regeringen till varje svensk myndighet (se mitt exempel med försvarets skyddsområden nedan). Tänk om -> skapa en ny bild av hur en effektiv och öppen myndighet ser ut och eftersträva den.
Jag försökte för 2 veckor sedan hitta remisserna som maskinläsbar data från Regeringen.se men det finns inte. Inte heller regeringens dagsärenden finns som maskinläsbar data, bara kryptiska PDF med punkter och inga länkar.
I praksis tas många beslut i kansliet på varje ministerium, men offentligheten får inte veta vem som berett ett ärende, vem som beslutat, under vilken ministers (in)direkta överseende det beslutats, etc. Det här betyder det att vi har en massa beslut i en massa ärenden och ministrarna har kanske inte ens själv överblick över alla. Är det bra för demokratin? Är det öppet?
Exempel på nytta av öppen data i maskinläsbart format:
Jag frågade för några månader sen försvaret om de skulle vilja publicera koordinaterna för deras övningsområden (som de idag endast publicerar i PDF format som rasterpolygoner på bildkartor utan precisa koordinater) som maskinläsbar data. De utredde saken med inspark från MUST, m.m.
De kom fram till att uppgifterna skulle kunna publiceras, men de var i dagsläget nöjda med att bara göra det i PDF form. Även deras tillträdesförbud publiceras i PDF vilket betyder att jag som kanske skulle vilja göra en bra app eller inbädda information i OsmAnd som visar tillträdesförbud för ett markerat skyddsområde MÅSTE parsa både HTML och PDF från försvarets hemsida-> det är kass öppen data.
Detta ska ses i lyset av att försvaret har PROBLEM med ökade tillbud i deras skyddsområden, se https://www.forsvarsmakten.se/sv/aktuellt/2021/04/antalet-livsfarliga-incidenter-okar-pa-forsvarsmaktens-ovningsfalt/
Med bra data skulle jag enkelt även kunna göra en app som via gps och försvarets öppna API varnar för att man just passerat in på område med tillträdesförbud oberoende av vilken väg man kommit in på området. -
@dennis_priskorn sa i Här kommer höstens NOSAD- workshops!:
+1 Jag håller helt med. CSV är bra.
Hur hanterar du flerspråkighet snyggt dvs. 1 fält med många språk.... finns det bra mönster i csv? att skapa nya kolumner för varje språk känns galet.... i Måltidsinformation verkar man skapa om hela filen för varje språk vilket känns bäddat för att skapa fel och inkonsistens.... plus erfarenhetsmässigt är det enklare att ha datat i samma fil och sedan välja visa multispråk fältet på det språk man förstår jmf zh, ar och sv allt data i Q317877 men visar fälten och term namnen på valt språk med fallback en....

Kollar du på projektioner så är har man valt nya fält för varje projektion se Måltidsinformation
Läser vi hos LM "en framtid kommer således all information att vara lägesbestämd i SWEREF 99. Läget kan dock redovisas i tretton olika plana koordinatsystem"
Hur ska det specas csv... med 13 nya fält? En fil för varje projektion....

Tänker jag fel?