Community på Sveriges dataportal
Förslag till nationell API-profil på Utvecklarportalen
-
Nu är den första versionen av Utvecklarportalen publicerad!
Utvecklarportalen innehåller ett förslag på en nationell REST API-profil och information som stöd för framförallt offentliga organisationers arbete med API:er. Hoppas att du får nytta och stöd av Utvecklarportalen och sprider information om den i dina nätverk.
Klicka på denna länk för att komma till UtvecklarportalenDela gärna med dig i forumet om du har några tips eller goda exempel på API-strategier, API-utveckling eller API- förvaltning.
Innan Myndigheten för digital förvaltning (DIGG) fastställer profilen som en rekommendation i sin första version inhämtar vi synpunkter fram till den 10 februari. För att vi ska kunna ta omhand synpunkter på ett strukturerat sätt hänvisar vi till en enkät. Läs på denna länk hur du lämnar synpunkter. DIGG kommer att beakta alla inkomna synpunkter och förbättringsförslag men vi kommer inte att kunna skicka ut svar på alla inlägg.
-
@kristine_ Vad menas med användande av händelser och motsvarande händelsenamn i detta stycke? Det känns lite taget ur sitt sammanhang, så det vore bra med något exempel. Jag kan inte hitta namnen i den lista från IANA som refereras?
https://dev.dataportal.se/sv/rest-api--profil/hypermedia/#link_relation_type
Vid användande av olika typer av händelser, ska motsvarande händelsenamn användas som Link Relation Type ( t.ex. activate , cancel , send , …).
-
@salgo60-ej-aktiv Jag tror att en dokumenterad profil faktiskt behövs för att kunna fungera som en rekommendation. Nästa steg är att ta in återkoppling om själva profilen (den här tråden etc). Med det sagt så behövs en referensimplementation och/eller några exempel så fort som möjligt. Tror dock det är orimligt att DIGG ska tillhandahålla alla dessa exempel. Det är inte klart, men bättre vore om flera förvaltningsmyndigheter kan implementera profilen för några öppna API:er.
-
@jonor Håller nog med dig Jonor om att ett exempel vore på sin plats. Tanken är att profilen inte ska begränsa i de fall det finns domänspecifika händelser, dock borde nog de allra flesta API:er bara använda de typer som är listade ovan på länken som du angav.
-
@salgo60-ej-aktiv Tyck till om denna artikel https://dev.dataportal.se/sv/api-playbook/audit-trail/. Den föreslår att det bör finnas ett unikt id vid loggning som du föreslår.
-
@jonor Det går nog att uttrycka sig bättre i denna mening, men det vi avser är att när man uttrycker mer komplexa operationer (som inte ingår i IANA listan) så ska man beskriva dem avseende den händelse som avses. De exempel som anges är tre exempel på detta, där vi anser att de ska återspegla vad som kommer ske vid anrop.
-
@jonass det problem jag ser var att samma dataset publiceras i flera portaler utan en unik identifierare som exempelvis DOI, vet inte om det är tillämpbart med det ni beskriver med ert dokument för API:er... dataportal.se, European data portal plus en egen dataportal hade dataset som antydde det var samma data men bristen på unikt DOI och version gjorde att man måste gissa...
dvs. det som beskrivs i "Building Google Dataset Search and Fostering an Open Data Ecosystem" - It is very common for a dataset, in particular a popular one, to be present in more than one repository.

som sagt ge oss lite exempel implementationer... dom få "dataset" som vi/jag hämtar via API:er är väldigt statiska ex. Litteraturbanken, Nobelprize.org, SKBL där är det overkill med transaktionsid och spårbarhet utan är mer statitiskt data och ett API som gör det enklare att maskinläsa datat och som gör att vi slipper webscrapa massa websidor... och i Nobelprize.org fallet har man även med "samma som" Wikidata --> vi har 5stardata och vet vad dom syftar på direkt...
men men tror att det är svårt att torrsimma och täcka in alla användarfall...
-
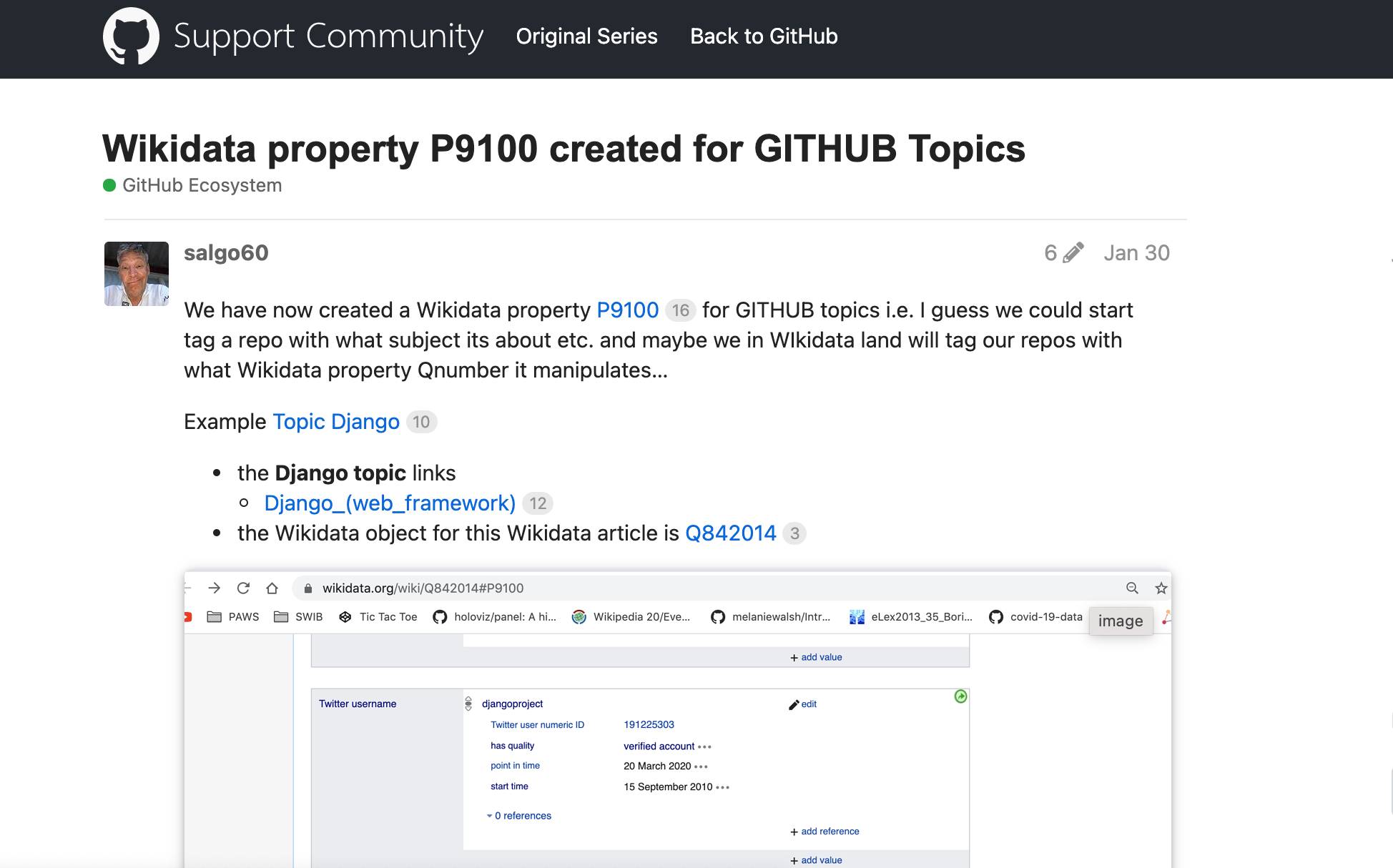
@jonass annan vag tanke med DOI för dataset var att man skulle kunna ha dom som GITHUB subject (Wikidata egenskap P9100 - video tankar) för att göra lösningar med ett visst dataset mer findable
dvs. det skall vara enklare att hitta lösningar som skapats med visst dataset... känns lite som om du också varit inne på detta att det vore inte helt fel att tänka på samma sätt med olika API:er att man hittar en "konvention" kanske med GITHUB ämne så man enkelt hittar vilka lösningar som skapats med ett API.... så att andra kommer igång snabbt... leker en del på Kaggle och där är det självklart att koppla kod med dataset
Skrev lite om det på GITHUB community forum.... idag är det ofta forskare som är duktiga på att ange DOI för sina vetenskapliga papper och tillhörande dataset...
-
@vesstrom Jag förstod utan större problem det övriga innehållet på sidan om hypermedia fram till det sista stycket. Där introduceras plötsligt begreppet "händelser" utan någon särskild motivering när man tidigare pratat om transaktioner, länkrelationer och typer.
Jag gick direkt in på sidan om hypermedia, så jag vet inte om man möjligen refererar underförstått till något som tas upp i andra delar av API-handledningen. Eller handlar det om att överföra befintliga RPC-liknande API:er till ett hypermedia-baserat gränssnitt?
De exempel som förekommer på sidan handlar om organisationer och kontotransaktioner, och där det gäller egna relationstyper anges svenska uttryck som "insättning" och "uttag" (är det realistiska exempel?).
Varför inte i så fall nämna "insättning, uttag och överföring" som exempel på domänspecifika typer då de redan tagits upp i ett sammanhang. Om nu detta också utgör ett exempel på vad man vill kalla "händelser" så kanske det uttrycket kan nämnas redan där det finns en kontext, t.ex. koppla det till ordet "transaktioner" som annars verkar användas för exemplen med "insättning", "uttag", "överföring", "edit", "replace", "delete".
"Olika typer av händelser" skulle kanske tydligare beskrivas av "representera domänspecifika händelseorienterade operationer som relationstyper/transaktioner" eller något liknande, och samtidigt referera till exemplen med kontotransaktioner (domänspecifika) och organisationer (standard).
Något som också är oklart är varför det är asterisker i relationstyperna, är det kanske ursprungligen märkspråk för fetstil i exemplet?
Inklistrat som vanlig inläggstext:
{"rel": " insättning", "href":"/konton/12345/insattning"},
{"rel": " uttag", "href":"/konton/12345/uttag"},
{"rel": " överföring", "href":"/konton/12345/overforing"}{ "kontonummer":"12345", "balans": 100.00, "_links":[ {"rel": " **insättning**", "href":"/konton/12345/insattning"}, {"rel": " **uttag**", "href":"/konton/12345/uttag"}, {"rel": " **överföring**", "href":"/konton/12345/overforing"} ] } { "kontonummer":"12345", "balans": -25.00, "_links":[{ "rel": "insättning", "href":"/konton/12345/insattning" }] } -
@jonor Uppskattar att du är engagerad och intresserad av vad vi tagit fram. Som sagt så finns det utrymme för förbättringar och delar som behöver förtydligas i texten. Dina åsikter är relevanta och vi ser gärna att du använder vår enkät som vi har för att mer formellt samla in feedback på REST API profilen.
Läs mer om detta här, https://www.digg.se/publicerat/remisser-och-yttranden/remisser-fran-digg/2020/lamna-synpunkter-pa-nationell-rest-api-profilTack
-
@salgo60-ej-aktiv För en handling, ett dokument, eller en forskningsartikel känns det naturligt att ha en unik global identifierare. Spontant tänker jag dock att ett DOI/sameAs attribut som i googles exempel gäller hela datasetet (en samling dokument, handlingar, forskningsartiklar), och kanske är en mer fråga för https://docs.dataportal.se/dcat/sv/. Dvs att objektet "datamängd" borde ha en identifierare. Hoppas att en expert på DCAT-AP-Se läser och tycker till.
Exempel från arbetsmarknaden när det är svårt att få dataproducenter att tagga sitt innehåll med en unik identifierare (jobbannonser förekommer ofta på många sajter).
Dubbletthantering: https://gitlab.com/arbetsformedlingen/joblinks/job_ad_hash/-/tree/develop
Tjänst: https://arbetsformedlingen.se/platsbanken/annonser?s=2
https://en.wikipedia.org/wiki/Jaccard_index och https://en.wikipedia.org/wiki/MinHash används för att identifiera informationsmängder som har stort överlapp.
Konsekvensen av att inte använda bra identifierare blir ju precis som du säger att det är svårt att i efterhand sortera upp informationen rätt.
-
@jonass sa i Förslag till nationell API-profil på Utvecklarportalen:
Exempel från arbetsmarknaden när det är svårt att få dataproducenter att tagga sitt innehåll med en unik identifierare (jobbannonser förekommer ofta på många sajter).
jag känner mig inte förvånad.
")
Dubbletthantering: https://gitlab.com/arbetsformedlingen/joblinks/job_ad_hash/-/tree/develop
Tjänst: https://arbetsformedlingen.se/platsbanken/annonser?s=2
https://en.wikipedia.org/wiki/Jaccard_index och https://en.wikipedia.org/wiki/MinHash används för att identifiera informationsmängder som har stort överlapp.
Intressant
Konsekvensen av att inte använda bra identifierare blir ju precis som du säger att det är svårt att i efterhand sortera upp informationen rätt.
Exakt och det är jobbigt för alla inblandade. Ett jobbuppslag är en historisk unik händelse. Den berättar mycket om vår samtid och om organisationen. Det är en värdefull datapunkt men behandlas att döma efter vad du skriver ovan styvmoderligt av alla inblandade...
Sparar riksarkivet alla annonser? Kan jag lätt kolla upp alla annonser SJ/Banverket hade ute i 1936? Är de bra kvalitet så jag kan köra NLP topic classification på dem? Kanske visualisera elektrifieringen av järnvägen med jobbannonserna som prism?
För att detta ska kunna göras så MÅSTE vi ha bra data med unika identifierare i grunden och gärna även grafdata som beskriver rollen de söker (tex backendutvecklare Q110245834 != frontendutvecklare Q54568999 != webbutvecklare Q6859454). För att detta ska funka måste vi ha in rollerna i en graf som vi kan peka på. Här har jag angett Wikidata QID men AF eller nån annan skulle lika väl kunna ha sin egen graf som beskriver varenda typ av jobb som förekommer eller har förekommit någonsin på svenska arbetsmarknaden.
Om ni vill ha hjälp att skapa en sådan graf så hojta till
Era samarbetspartners och resten av världen kommer älska er! Inget har gjort det öppet än (@salgo60-ej-aktiv gissar att LinkedIn redan gör detta, men de håller korten tät till kroppen så det har inget allmänt värde för samhället utan syftar till vinstmaximering hos dem)Jag skrev just riksarkivet
"Hej
Jag undrar om ni sparat jobbannonser från 1900-talet? Tex från banverket så jag kan se hur elektrifieringen påverkade jobbannonserna över tid?Är de digitaliserade? Om inte, är det planerad? Vad är ETA på det arbetet i så fall?"
-
@dennis_priskorn https://data.arbetsformedlingen.se/annonser/historiska här kan annonser för åren 2006-2021 laddas ner.
-
@kristine_ ni säger att ni vill ta emot synpunkter på ett strukturerat sätt. Men ändå vill ni ha en enkät med fritext. Varför publicerar ni inte API-profilen som ett gäng markdown-filer i ett publikt repo på exvis github eller gitlab så att kommentarer kan göras i kontext?
”Tala till de lärde på de lärdes vis och till apor på apors vis”.
Jag vill passa på att berömma att ni öppnar upp för feedback i en såpass tidig fas ändå!
 🤩
🤩 -
@stefan-wallin
Bra input, just idag använde vi inte Markdown men vi tar med oss frågan för hur vi långsiktigt ska arbeta med profilen och playbooken.Hälsningar, Kristine
-
Finns det en möjlighet att följa arbetet med API-profilen eller annars någon tidplan alternativt uppskattning av hur stora förändringar som förväntas som man kan ta del av?
Jordbruksverket är i ett läge där vi arbetar med att låta API:er ta en mer central roll i både applikations- och integrationsutveckling, vilket gör att behovet av förutsägbarhet kring API-profilen ökar då vi önskar utgå från den.
-
@peter_bengtsson Vad kul att ni är intresserade och vill följa arbetet!
REST API-profilen har varit ute på remiss där personer som jobbar med utveckling av API:er har fått möjlighet att lämnar synpunkter. De inkomna synpunkterna hanteras och bearbetas nu av DIGG tillsammans med arbetsgruppen kring utvecklingen av REST API-profilen.
Vår plan är att releasa (publicera) och fastställa version 1.0 av REST-API Profilen inom ramen för Q2. På grund av att vi genomför en migrering av CMS (Content Management System) har vi svårt att lova någon specifik tidsplan och det gör det svårt att följa arbetet.Om ni har mer specifika frågor kopplat till något specifikt område i profilen kontakta info@digg.se. Jordbruksverket har lämnat synpunkter på profilen, så det har vi med oss.
Läs mer om profilen på vår webbplats Utvecklarportalen, https://dev.dataportal.se/sv/rest-api--profil/.Läs mer om synpunktsarbetet på vår webbplats, https://www.digg.se/publicerat/remisser-och-yttranden/remisser-fran-digg/2020/lamna-synpunkter-pa-nationell-rest-api-profil.
Observera att det inte längre går att skicka in synpunkter.
-
Tackar för svaret! Q2 är ändå någonting att förhålla sig till.
Jag är en av de som var med och tog fram synpunkterna för Jordbruksverkets räkning, så skulle det uppstå några frågor är det bara att höra av sig.