Community på Sveriges dataportal
Fastighetsdatalabb Lunchseminarie Datastory - 10 år med öppna data och datavisualisering
-
Fastighetsdatalabb Lunchseminarie Datastory - 10 år med öppna data och datavisualisering
When Wed 2021-04-21 12:00 – 13:00 CET - Stockholm
Joining info
Join with Google Meet meet.google.com/jgz-gvez-odgVarmt välkomna till ett lunchseminarie tillsammans med Fastighetsdatalabbet och Datastory.
Daniel Lapidus bjuder på en timme med spännande och visuellt intressanta exempel medan ni mumsar på era matlådor hemma vid köksbordet. Så, starta mikrovågsugnarna och var redo att koppla upp er kl 12.00 den 21 april till meet.google.com/jgz-gvez-odg
Datastory är en organisation som gör data och kunskap tillgängligt i form av interaktiva verktyg och datadrivet berättande. Datastory samarbetar med olika organisationer, myndigheter och företag för att omsätta data till interaktiva applikationer.
Daniel Lapidus grundare av Datastory började sin datadrivna bana på Gapminder och med Hans Rosling som mentor så kan vi inte annat än förvänta oss stora ting från denna man.
Agenda
- Inspiration, bakgrund (10 min)
- Data / öppna data (10 min)
Här tittar vi närmare på lösningar för att lagra och dela information och statistik.
Nyckelord som ontologier, länkad data, öppna data etc. - Visualisering för webben (15 min)
Vilka lösningar finns idag, vilken kombination av lösningar passar er verksamhet? - Storytelling och impact (10 min)
Hur kan vi mäta resultat av arbete med datavisualisering? - Öppen Mic, frågor och diskussioner (15 min)
-
@salgo60 Låter intressant. Behöver man anmäla sig nånstans, eller är det bara att ansluta via länken?
-
Ingen anmälan krävs, klicka på länken när det är dags.
Dock så rekommenderas det jobb Fastighetslabbet gör att följa dom. Dom har workshops där alla är välkomna och pratar länkade data och kör Jupyter Notebook för att visa olika lösningar.... Min tro att det är så Öppen Data skall drivas med konkreta problem och branschkunniga som diskuterar...
Rekommenderar alla att titta på föredraget Daniel höll ovan
-
vid 19 min där Daniel Lapidus har som mål att hämta data från Riksdagens Öppna data för att bättre förstå vad våra Riksdagsmän vill
-
i Wikidata har vi börjat titta på om detta kan göras på Europa nivå men även för kommunerna se projekt Wikidata:WikiProject_Sweden/Municipal_commissioner_in_Sweden tyvärr finns ingen att kommunicera med hur vi driver detta vidare tycker projekt som ÖDIS borde vara dom man har dialog med (cc: @jonas-nordqvist) tyvärr känns just ÖDIS svåra att kommunicera med och osynliga vad dom levererar eller var diskussionen förs..... jag tror många projekt skulle vinna p synlighet och installera en egen wiki eller som Naturvårdsverket ha en yta på GITHUB https://greentechdev.github.io/
-
vid 22 min pratas det som Cityblock tror det är www.cityblock.com / twitter cityblockhealth
om Datastory "Datastory partners with research organizations, academia, public institutions and media to educate at scale."
-
-
@salgo60 Håller absolut med dig om att det är bra att kunniga branschaktörer driver frågor och utveckling, då blir det lättare att uppnå tex konsensus kring bla specifikationer...
-
@salgo60 ÖDIS-projektet är avslutat, vilket troligen är anledningen till att du tycker att det kan uppfattas svårt att kommunicera med projektet.
Jag har uppdraget att driva öppna datasamverkan vidare för Stockholms läns kommuners räkning. Vill du veta mer om mitt uppdrag och vad jag ämnar leverera så är du välkommen att kontakta mig.
-
Här är några länkar från seminariemötet:
Samlar publikationer
https://distill.pub/University of Washington Interactive Data Lab
https://idl.cs.washington.edu/Nivåer för öppna data
5stardata.infoNivå 4
data.riksdagen.seNivå 5
https://query.wikidata.org/
Ardalan Shekarabi Wikidata
https://www.wikidata.org/wiki/Q4787806Manhattan buildings 3D
https://tbaldw.in/nyc-buildings/GitHub users visualisering 3D
http://ekisto.sq.ro/Transporter, Svenska fartyg i Finska Viken?
https://www.vesselfinder.com/https://www.electricitymap.org/map
Mapping the climate impact of electricityhttp://waqi.info/
World's Air PollutionChatt:
Ardalan Shekarabi Wikidata https://www.wikidata.org/wiki/Q4787806
samma på kinesiska
https://www.wikidata.org/wiki/Q4787806?uselang=zhÖppen data <> tillförlitlig data
https://www.svd.se/forsvaret-oroas-av-falska-fartygsrutterDet finns en intressant "standard" eller EU-praxis som säger att man bara ska behöva rapportera information till myndigheter till ETT ställe EN gång - den s.k. Tallindeklarationen.
https://digital-strategy.ec.europa.eu/en/news/ministerial-declaration-egovernment-tallinn-declaration
https://www.wikidata.org/wiki/Q106581243https://archive.nytimes.com/www.nytimes.com/interactive/2012/02/13/us/politics/2013-budget-proposal-graphic.html
Four Ways to Slice Obama’s 2013 Budget Proposal -
Några länkar till.
AI lär sig kurragömma gradvis; jaga, blockera öppningar, använda ramp ...
https://openai.com/blog/emergent-tool-use/
Emergent Tool Use from Multi-Agent InteractionBefolkningsmängd och förändring, 3D
E.g. tillväxt i Stockholm, avfolkning i östländer.
https://pudding.cool/2018/10/city_3d/
Human Terrain -
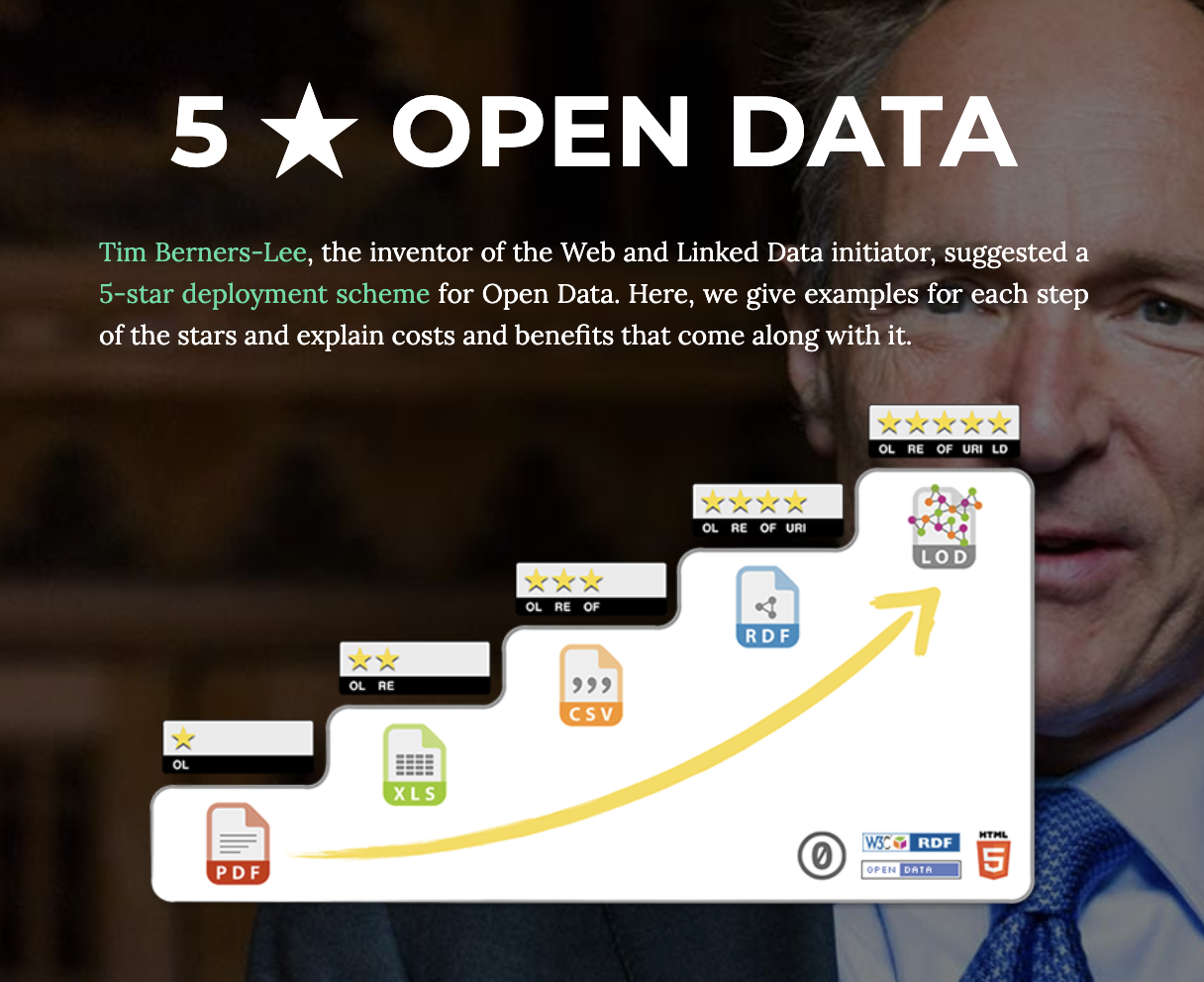
@jonor intressant att han tryckte på hur stort steget är att gå från nivå 4 till 5 LOD i pyramiden
jag har kopplat ihop 10-15 svenska organisationer med Wikidata och gjort > 800 000 Wikidata redigeringar och ser inte den mognad/kompetens som skulle behövas med Öppen data hos IT organisationer
På den tiden jag gick till ett jobb för att tjäna pengar flyttade jag metadata mellan internationella banker och där fanns ett mycket bättre user case att datat man flyttar skall vara samma som dvs. det var 0 tolerans att pengar som skulle till Anders Andersson kom fram till fel Anders Andersson och att man inte hade en hittepå valuta....
Svenska kulturarvet startade bra på 1700 talet med att ha dessa samma som för runstenar se min dataroundtrip artikel men idag har man förfallit till att ha text strängar och inte prata med varandra exempel hur man gissar att alla Carl Larsson är samma person.
Dagens öppen data med textsträngar på svenska lägger över massa mer eller mindre omöjligt jobb på den som konsumerar datat blir lite som vi skulle ha ett vattenreningsverk vid varje handfat istället för att rena vid källan fast 100 ggr värre...
Lösningen: DIGG skapa en kunskapsgraf för Öppen Data som alla refererar till som @Dennis_Priskorn predikar om....
-
@salgo60 Jag tyckte också det var intressant hur han beskrev att tröskeln till nivå 4 och 5 var mycket högre än för de föregående stegen, och att stegen i illustrationen snarare borde förhålla sig exponentiellt än som jämnhöga.
Sedan uppskattade jag att han tog upp exempel på nivå 4 och nivå 5 i form av data.riksdagen.se (om jag minns rätt) och Wikidata. Det blev lite mer konkret när han nämnde att det handlade om att tilldela URI:er för publik referens, och i nästa steg att etablera standarder för att kunna referera till data mellan olika "ägare" eller förvaltare.
CSV som bara är textfiler med tabelldata är lätt att få grepp om, men stegen ovanför kan kännas mer abstrakta. Jag har tittat lite på Wikidata men har inte riktigt kommit fram till hur man ska komma igång med det eller hittat någon "ingång" liknande forum som detta t.ex.
Om man kunde hitta något enklare exempel på hur man steg för steg kunde ta sin datamängd, skapa URI:er och länka till någon existerande data skulle det kanske vara till hjälp för att få en mer konkret förståelse och känsla för vad de högre nivåerna innebär. Hur börjar jag t.ex. med att skapa URI:er och publicera en datamängd? Vad ska jag sedan tänka på för att använda gemensamma referenser och begrepp?
Artikeln om runstenar låter intressant, men jag slås av att det är många förkortningar och begrepp redan i rubriken som är främmande för mig i nuläget. Vad en kunskapsgraf innebär är jag heller inte bekant med, så området framstår helt klart som ganska tekniskt avancerat ur en nybörjares perspektiv.
-
@jonor det är bara att höra av dig till mig kan jag vi köra en session där vi delar skärm 0705937570.... eller ännu bättre om du har konkret data....
- det här är en helt ny värld och det vi pratar om är att vara semantisk expert / knowledge engineer dvs, att kunna beskriva olika kunskapsdomäner semantiskt och sedan koppla ihop dom med andra kunskapsgrafer. Dom som kommit längst på detta är Google, Apple, Amazon ....
- jag har inte ens sett detta i Sverige.... vi har en del att lära.... eller kanske en del misstag har gjorts och kommer att göras igen tills vi inser utmaningen...
kollar jag på dom som håller på med Wikidata och gör verklig skillnad på Wikidata så är det folk som doktorerat inom Teknisk fysik och är några av dom smartaste människor jag mött och då är jag själv Teknisk fysiker så detta är inte trivialt.
- Lätt video vad Wikidata är "An introduction to Wikidata"
- längre video där han som skapa internet Tim Berners Lee pratar om att ha data som data - the next web
- det är även han som kommit på detta med #Linkeddata
- det är som sagt inte helt trivialt och vi har sett kultur Sverige försökt ta steget sedan 2012 men inget händer mycket för att man inte inser att detta kräver nya kompetenser min blogpost om detta elände...

Enklare exempel på skillnad
- Sverige
- text sträng = Sverige
- text sträng med språkkod = Sverige - lang sv
- text sträng med språkkod = Sweden - lang en
- text sträng med språkkod = 瑞典 - lang zh
- text sträng = Sverige
- Wikidata: Sverige = Q34 ==> lista egenskaper 222 egenskaper
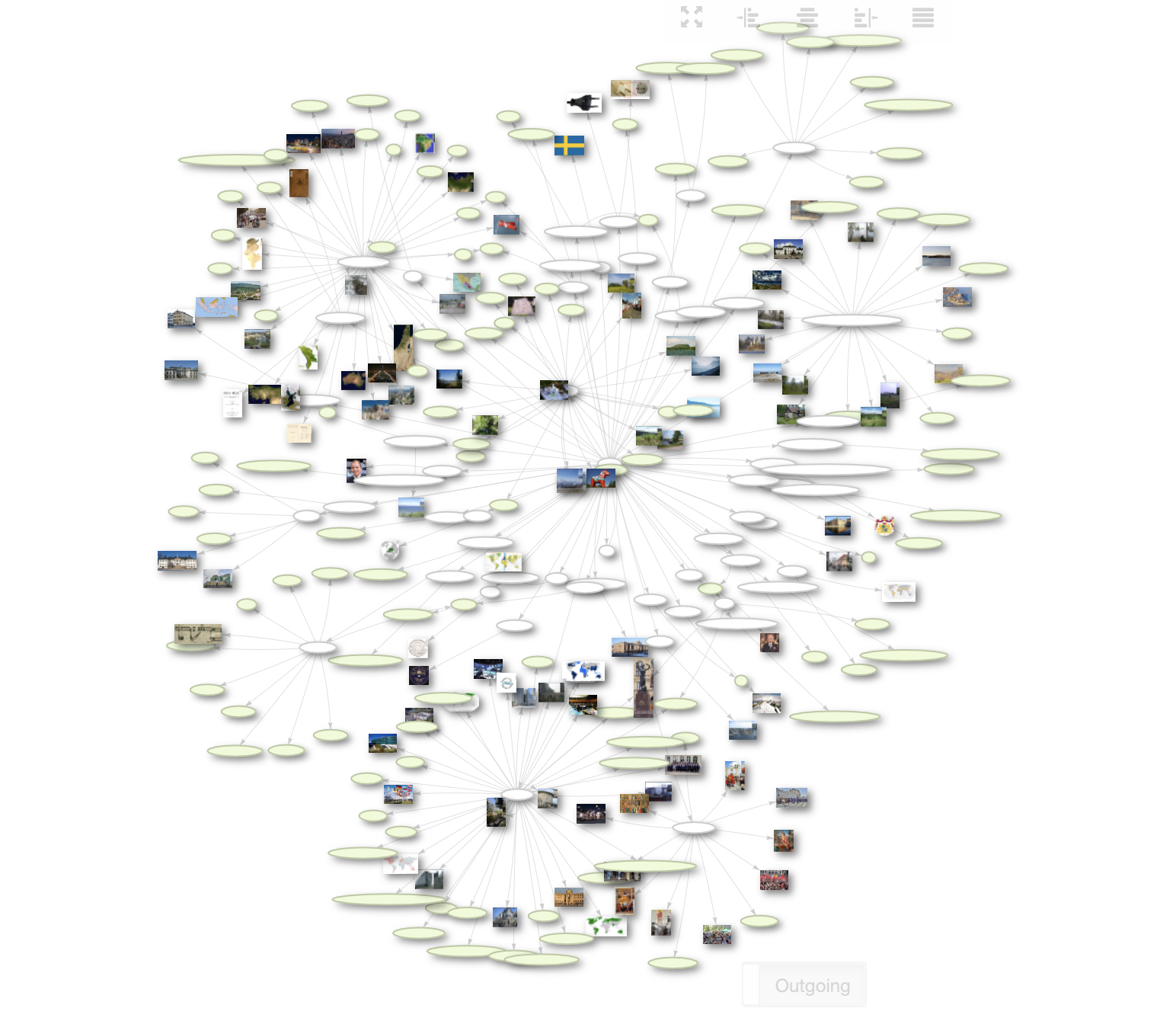
Kollar vi på Riksdagens data
- min erfarenhet med detta data
- jobbade på Paralog som var svensk fritextsökning på 90 talet och var inblandad som konsult hos Riksdagen
- träffade Riksdagen 2019 och beskrev Wikidata för att se vad vi kan göra med varandra länk
* skapade en egenskap för svenska Riksdagsledamöter Property:P8388
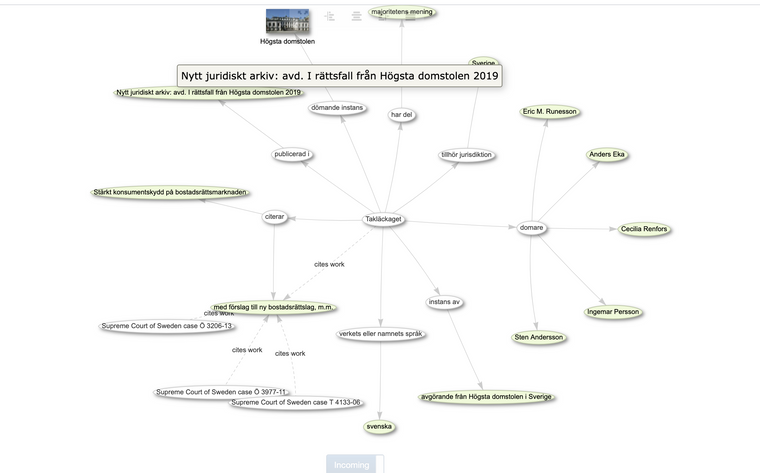
* en annan för Riksdagens dokument Property:P8433 - andra har gjort ett magiskt jobb att lyfta in > 100 000 dokument i Wikidata se bra video vid 21:20 minuter beskriver Daniel (enormt skärpt) hur han importerat Högsta domstolens domar, ledamöter och skapar sedan kopplingar till Riksdagens dokument som varit som underlag till detta ex. NJA 2019 s. 1013 - Takläckaget jämför hur HD har detta bara som ett textdokument i pdf utan kopplingar....
* för att kunna beskriva hela världens alla riksdagar (projekt Wikidata:WikiProject_every_politician) och deras ledamöter så har andra tagit fram en ShEx beskrivning se EntitySchema:E134 dvs. ett schema för datat så att vi får konsistensinte helt trivialt men Tim Bernes Lee hade rätt om internet när han tog fram det 1989 och det känns även som han förstår hur data skall kopplas till data semantiskt...
")
- det här är en helt ny värld och det vi pratar om är att vara semantisk expert / knowledge engineer dvs, att kunna beskriva olika kunskapsdomäner semantiskt och sedan koppla ihop dom med andra kunskapsgrafer. Dom som kommit längst på detta är Google, Apple, Amazon ....
-
Mer från fastighetslab det känns verkligen som dom har en vision och tänker digitalt
Välkommen till hackaton i Fastighetsdatalabbets arbetsgrupp
”Digital Tvilling - Testbädd - Tät Stad”
Torsdag 27 maj klockan 9 -12ABB vill tillsammans med oss och på våra plattformar visualisera energiflödet i en stadsdel. Vi vill undersöka och visa på vad som är problemet med energidistributionen ur ett miljöperspektiv. Tillsammans vill vi hämta data ifrån befintliga databaser och kanske sätta in fler mätare i elnät och fjärrvärmenät och visualisera dessa data. Företrädesvis gör man detta med realtidsdata med hög noggrannhet.
ABB har mätare, kommunikationsutrustning och säkra dataplattformar för att hantera data. När data finns visualiserat så finns det massor med möjligheter för andra att göra analyser och komma med förbättringsförslag.
På samma sätt kommer vi att arbeta i de övriga grupperna nedan, med aktörer som har anmält sitt intresse för att bidra med teknik och kompetens.Målet är att visa upp en 3D-bild av stadens struktur och flöden — och visa på vad som behöver hända för att leva upp till Klimatkontraktet.
Program
09:00 Bakgrund, Klimatneutrala städer/CIM/datalabbet och sammanfattning av det senaste seminariet.
09:15 Presentation av grupperna och indelning i utbrutna zoomrum
Spara energi i bostäder, digitalisering och sensorer
Samla in matavfall
Mobilitetshubb
Testbädd - Stockholm, Göteborg m fl
Utveckla digitala verktyg
Medborgardialog
11:45 Sammanfattning och nästa steg
12:00 Lunchpaus
12:30 Efterhack - De som vill fortsätter
14:30 Diskussion
15:00 Tack för idag