Community på Sveriges dataportal
-
Hej, jag tittade på leverantörsfakturor.csv från DIGG.
https://www.dataportal.se/sv/datasets/760_1544/leverantorsfakturor
Det verkar som textfilen har en systemspecifik kodning (Windows-1252 eller ISO-8859-1?).

I metadatan står att formatet är text/csv, men jag hittar inte någon information om teckenkodningen.
Webbadress för åtkomst
https://catalog.digg.se/store/1/resource/33
Format
Vanliga mediatyper
CSV (.csv)Borde inte teckenkodningen vara UTF-8 eller anges uttryckligen i metadatan så att konsumenten kan avkoda innehållet korrekt?
Lade märke till också att frågan om en standardteckenkodning togs upp i utkastet till specifikation för badplatser som refererades i en annan tråd:
6 . CSV-formatet
Det enklaste formatet att stödja är CSV formatet enligt RFC4180.
Utöver det som sägs i RFC4180 krävs alltid att informationen är uttryckt med teckenkodning UTF-8. -
@kristine_ Ok, innehållet kanske borde ses över lite i en del andra avseenden också.
En del fakturanummer verkar ha formaterats som talvärden med vetenskaplig notation.
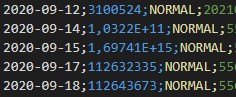
Här en icke kredit-faktura med negativt belopp? Jag vet inte om sånt händer, men det var ett udda fall i posterna.

I samband med det undrar jag också om talformatet för kolumner finns angivna i metadatan, eller hur vet man vid maskin-inläsning om komma eller punkt används som decimalavgränsare?
-
@kristine_ Hej, hur har det gått med detta dataset?
Om datan ska vara maskinläsbar behöver det finnas metadata för teckenkodning och talformat som används.
Är teckenkodningen Windows-1252, UTF-8, UTF-8 BOM?
Vilken separator används som fältavgränsare?
Vilken decimalseparator och tusentalavgränsare används för fält med talformat?Har DIGG några rekommendationer angående detta?
Hur gör jag som läsare av det publicerade datasetet för att tolka innehållet korrekt?
-
@jonor Hej,
Jag vill be om ursäkt för att det har tagit tid att besvara din fråga. Ser även att jag missade att återkoppla till dig i somras. Jag behöver ta frågan vidare med min kollega och ber om att få återkomma.Vänliga hälsningar,
Kristine -
@kristine_ WOW! Har kollat på dataset, verkligen föredömligt att öppna upp leverantörsfakturor. Lite förvånad att det inte har fått mer uppmärksamhet, finns en stor potential om svensk statsförvaltning följer i DIGG:s fotspår. @jonor antar att UTF-8 är ett rimligt val för encoding.
-
@jonass sa i Teckenkodning för CSV-data?:
@jonor antar att UTF-8 är ett rimligt val för encoding.
@jonor Det finns en specifikation för leverantörsreskontra på Dataportal.se. Flera arbetar med att börja följa den och vissa har ännu inte angett på Dataportal att de följer den.
@jonass Du har rätt om att UTF-8 är rimligt val. I specifikationen så rekommenderas just UTF-8: https://lankadedata.se/spec/leverantorsreskontra/#csv.
-
@mattias Tack, då kan man förstås fundera över varför DIGG inte verkar ha känt till den specifikationen.
Jag är osäker på om schemalänken fanns på sidan för datasetet förut, men den säger hur som helst ingenting om teckenkodning, separatortecken eller datatyper, det är som synes bara en lista över kolumnnamn.
https://lankadedata.se/spec/leverantorsreskontra/schema.json
Det är bra att det finns en manuell specifikation för leverantörsreskontra som beskriver fältvärden och sådant, men den svarar inte heller inte på de frågor jag ställde angående CSV-formatet. Hur ska jag veta som datakonsument hur jag ska avkoda filen?
I specifikationens punkt 3 om CSV-formatet står det:
För den här specifikationen innebär det att implementatörer rekommenderas även stödja semikolonseparerade filer.
För att särskilja data som är semikolonseparerade från kommaseparerade måste första raden se ut som:
kopare_id;kopare;verifikationsnummer;leverantor;leverantor_id;konto_nr;konto_text;belopp;datum;forvaltning;faktura_nr;grund;avtal;kommun_id,s_kod_nr(Här har det dessutom smugit sig in en felskrivning där sista separatorn är ett kommatecken.)
Jag tycker det verkar märkligt. Är det jag som datakonsument som ska vara "implementatören" och stödja andra format än det standardiserade?
Det framgår inte tydligt hur jag ska lösa det från konsumentsidan.
Det står "för att särskilja data måste första raden se ut som ...", men ingen hänvisning till hur detta stöds eller implementeras i bibliotek eller programvaror. Ni verkar här uppmuntra dataleverantörer att lägga ut variationer som avviker från standardformatet och lämnar till konsumenten att tolka detta utifrån filinnehållet istället för att deklarera formatet i metadata.
Sedan blir det ju en motsägelse då man bryter mot specifikationen om man lägger ut en svenskspråkig Excel-export med semikolonavskiljare för fält och kommatecken för decimaltal?
Denna specifikation kräver dock att man använder punkt i decimaltal (se 2.1).
Antingen bör ni väl hålla er till standardiserad CSV enligt RFC eller deklarera i metadata all information om avvikelser som behövs för automatisk inläsning?
Så vitt jag kan se beskrivs det faktiskt i dokumentationen ni hänvisar till hur detta ska göras:
https://www.w3.org/TR/tabular-metadata/#dialect-descriptions
https://www.w3.org/TR/tabular-data-primer/#dialects
6.5 What about CSV that isn't standard CSV?
A lot of what's called "CSV" that's published on the web isn't actually CSV. It might use something other than commas (such as tabs or semi-colons) as separators between values, or might have multiple header lines.The metadata that's described here can be used with files that contain tabular data but that aren't CSV. You can provide guidance to processors that are trying to parse those files through the dialect property on a table description.
EXAMPLE 126
{ "@context": "http://www.w3.org/ns/csvw", "url": "http://example.org/data/unemployment.tsv", "dialect": { "delimiter": "\t", "headerRowCount": 3 } }I datasetet på dataportalen så talar ni dock bara om att jag ska ignorera blanktecken runt fältvärden:
"dialect": {"trim": true}, -
@jonor sa i Teckenkodning för CSV-data?:
@mattias Tack, då kan man förstås fundera över varför DIGG inte verkar ha känt till den specifikationen.
Det kan finnas flera olika anledningar men en generell anledning är att specifikationen inte har kommunicerats särskilt mycket externt. Denna spec som vidareutvecklades av NSÖD lyfts t.ex. inte inför workshop kring just Specifikationer idag 2021-10-14. Istället länkas det till en specifikation om leverantörsreskontra från utlandet som ingen i Sverige använder så vitt jag vet.
Hur ska jag veta som datakonsument hur jag ska avkoda filen?
..."dialect": {"trim": true},Tack @jonor jag har lagt upp dina synpunkter på Gitlab-projektet så gott jag kan. Du är varmt välkommen att bidra om just denna spec där.
-
 K Kristine_ moved this topic from Efterfråga data och API:er on
K Kristine_ moved this topic from Efterfråga data och API:er on