Community på Sveriges dataportal
-
OT @jonass snyggt med kommuner
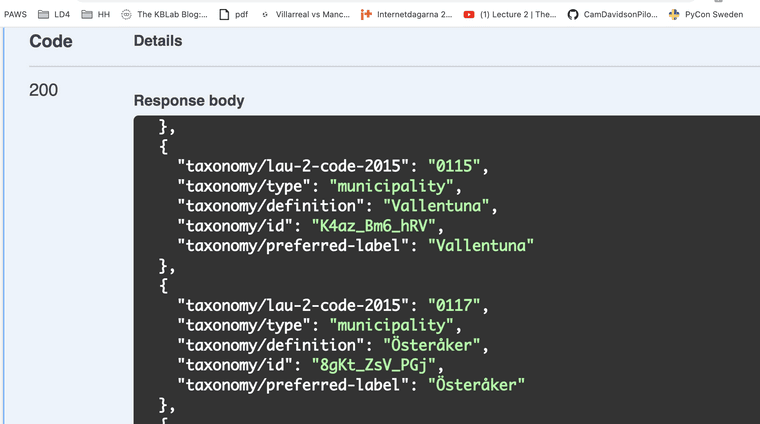
Finns det en tanke med hur andra språk skall stödjas?
Känns även här behöver vi ETT ställe där vi har en auktoritet som handhar namnet på olika språk maskinläsbart.... idag finns detta i #Wikidata mer eller mindre bra... men tråkigt många luckor för exempel arabiska som är Sveriges andra språk...
- SPARQL https://w.wiki/4TKf
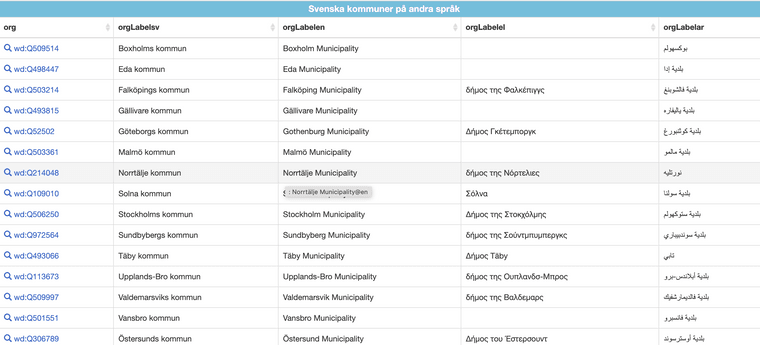
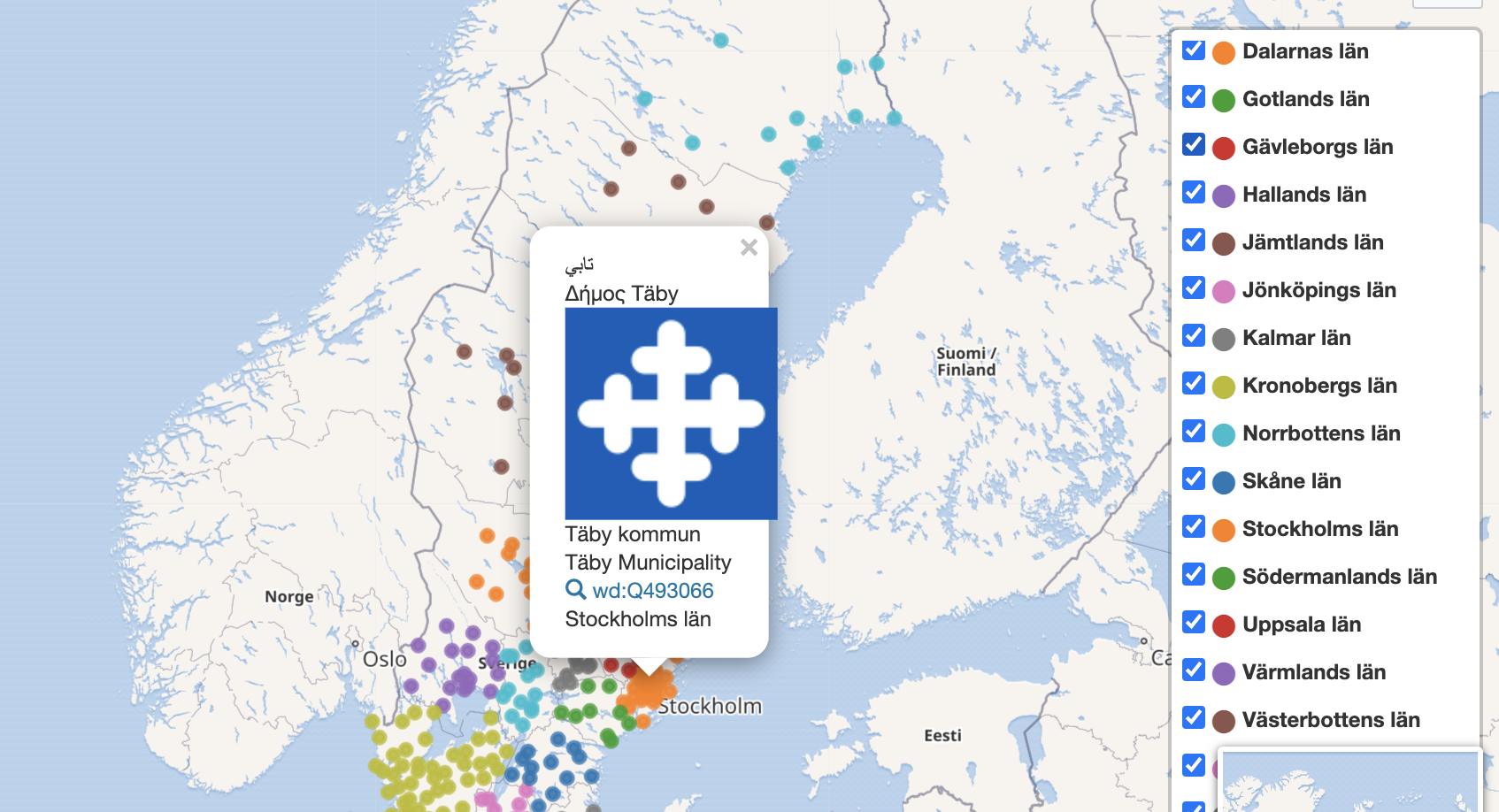
-
@salgo60-ej-aktiv Finns inte stöd för att länka till andra språk/översättningar idag. Vår värld utgår ifrån taxonomy/id ovan som identifierare, men för vissa dataset finns det säkert översättningar om ett wikidata-id kunde användas som en "foreign key". Ska dubbelkolla med taxonomy-teamet om det finns några tankar/planer.
-
@jonass @salgo60-ej-aktiv Åtminstone när det kommer till yrken och kompetenser så har ju ESCO översättningar till många språk. I och med att vi mappat de svenska yrkesbenämningarna (och arbetar med att mappa kompetenserna) så bör man i bästa fall kunna plocka in översättningar därifrån.
Problemet är kanske att de ”bästa fallen” bara utgör runt 40 % av de svenska yrkesbenämningarna (den andel som har en exact matchning mot ett ESCO-yrke), för vilka man borde kunna hitta okej översättningar till alla officiella EU-språk + arabiska. I övriga fall rör det sig om inexakta mappningar (broad match, narrow match, close match) och där blir allting lite mer diffust.
Gjorde en snabbkoll och om man begränsar urvalet till de 100 mest förekommande yrkesbenämningarna i annonser (där arbetsgivaren valt yrkesbenämning), för det första halvåret av 2021 så har runt 70 % av dem exact match till ett ESCO-yrke. Kanske en godtycklig avgränsning, men åtminstone kan den fungera som en indikation på att det går att hitta rätt bra översättningar (till många språk) för merparten av de av arbetsgivare mest använda yrkesbenämningarna. Vet dock inte hur straight forward det är att hämta ut översättningarna i dagsläget, men jag gissar att man borde kunna slå upp dem med hjälp av de esco-uri:er vi har i Taxonomy.
Ursäktar om jag kanske kom in på ett annat spår här. Men när det kommer till saker som kommuner, län och dylikt så känns det som en bra idé att inkludera externa idn. Vi har faktiskt inte resonerat så mycket kring det för annat än yrken men vi får fundera en vända.
-
@davidnorman som icke domän expert så har jag kollat kort på ESCO och det känns intressant tror vi måste börja beskriva yrken, kompetenser på nya sätt så att det fungerar för alla matchnings algoritmer som börjar finnas och där dom stora vinsterna troligen kan skapas....
Wikidata tror man kan plocka russinen ur kakan men man bör ha WIkidata som är en öppen kunskapsgraf på ett "armlängds avstånd" och inte se det som en sanning...
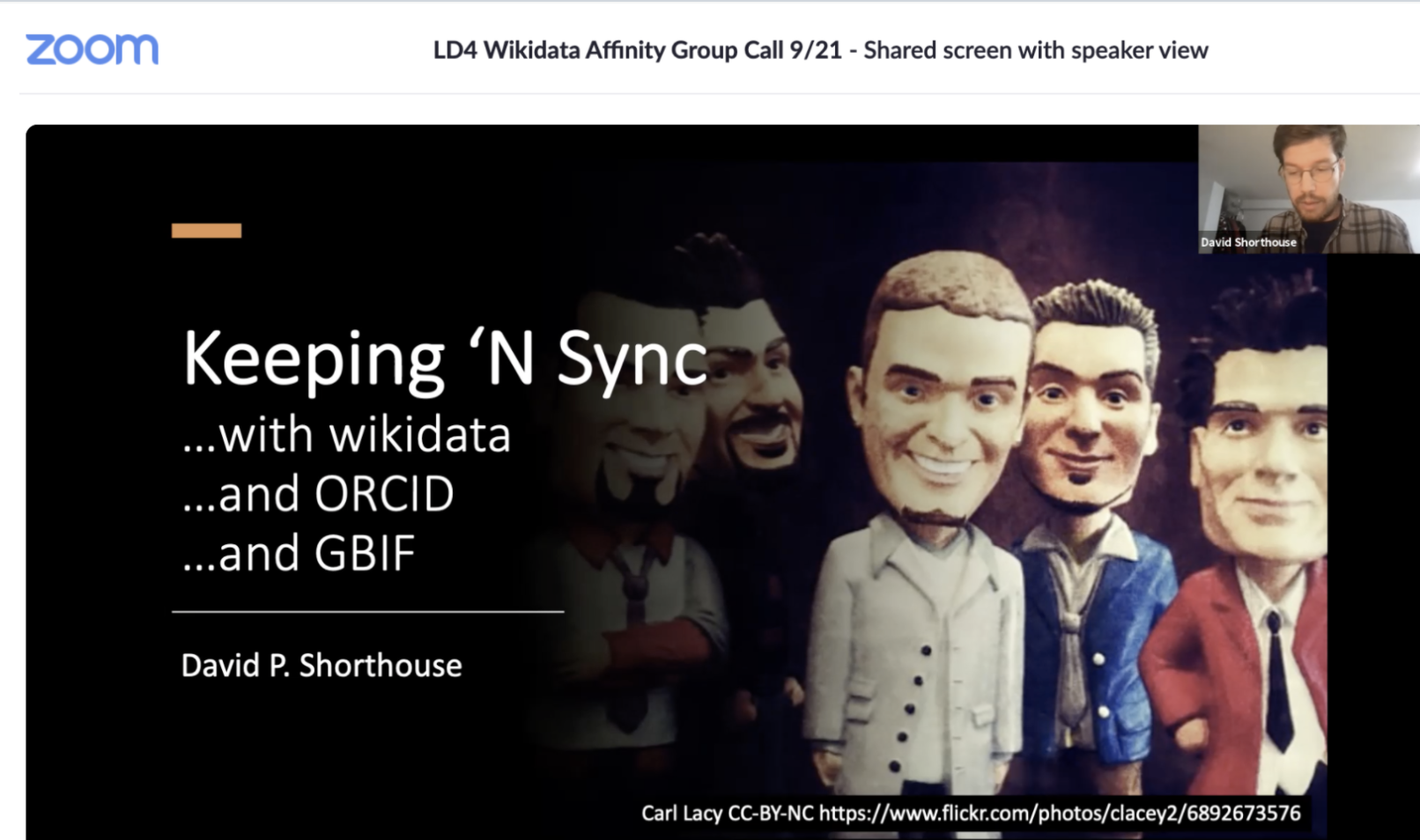
Hur andra jobbar med Wikidata
Bra presentation hur en applikation Bionomia som håller reda på personer som dokumenterat växter.... synkar med Wikidata, ORCID (levande personer) och GBIF (biodiversity data)- LD4 - video presentation startar vid 05:00 Keepin 'N Sync... with wikidata ... and ORCID...and GBIF - slides av David Shorthouse
- slide 20 - vid 23:00 hantera merge i Wikidata (troligen inget problem med kommuner)
- han lyfter fram en "checklista" jag skapat the Magnus list vid 27:00
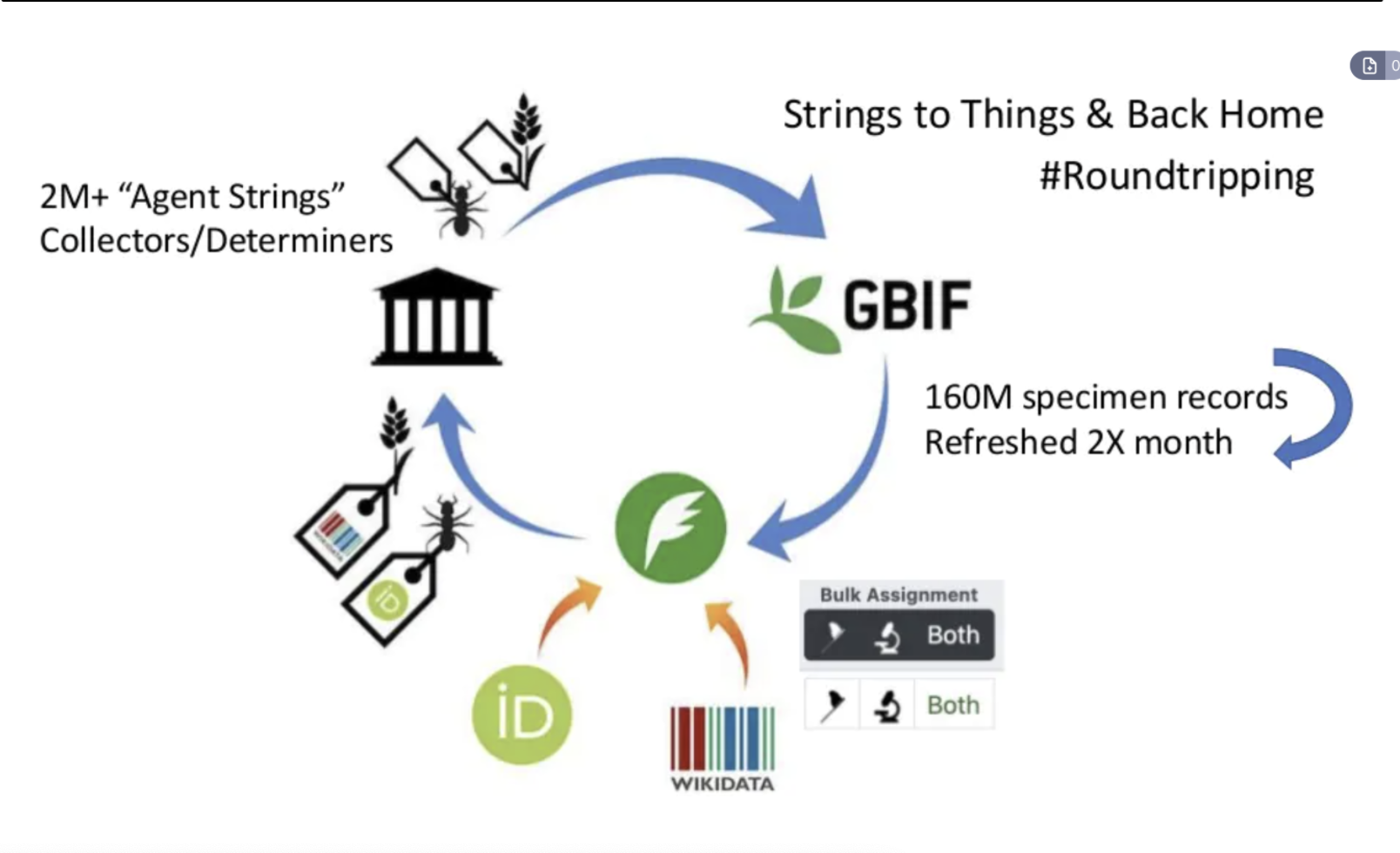


-
@salgo60-ej-aktiv Bra att det finns transkript i videon, men lite konstig sökfunktion, den verkar bara träffa på hela ord. Innehållet går lite över huvudet på mig, innebär authoritativeness att något är en förstahandskälla, eller att man bemyndigats eller på något sätt utsetts att vara det? Och myten innebär att detta inte nödvändigtvis korrelerar med kvaliteten på datan? Hans förslag är då att Bionomia antar rollen som en egen auktoritet genom att införa Bionomia ID.
-
@jonor sa i Taxonomi API:
authoritativeness
Han som pratar på videon är extremt ödmjuk och galet snabb att koda men min tolkning blandat med min erfarenhet nedan
- authoritativeness
- traditionellt var "gamla auktoriteter" = sanningen
- Kungliga Biblioteket (KB) lever i den tron fortfarande och senast jag fråga ansåg dom inte att dom behöver källor på deras påstående eftersom dom är Sveriges nationalbibliotek - Samhällets minne
- traditionellt var "gamla auktoriteter" = sanningen
- det som händer är att "gamla stötar" som Kungliga biblioteket inte hänger med och inte uppfyller saker på "min" lista --> de håller på att "utrota" sig själva om du frågar mig... eftersom de ofta/alltid är bidragsstyrd verksamhet så är det en långsam process...
- vad som har hänt sedan KB skapades är
- kortkatalogen är elektroniska
- 2012 startade man LIBRISXL som skulle skapa en Linked data katalog men min tolkning är att KB organisationen är inte lärande --> enormt tamt resultat
- man söker idag via Google oftast, KBs sökning idag är lite "udda"
- Google kör projekt där man scannar in alla böcker --> att dom kan även fritextsöka i boken och visa upp i sin Google sökning
- eftersom Google har min sökhistorik "vet dom" vad jag brukar söka på och gissar jag har en kunskapsgraf med mina preferenser
- Google vet vad ML är och gissar jag har helt andra kompetenser på att extrahera ut vad böckerna handlar om --> du kan söka med både högre recall/precision än vad KB erbjuder... plus att KB bara stödjer svenska
- kortkatalogen är elektroniska
- nästa problem som börjar synas är att även dessa "gamla auktoriteter" behöver ha kunskap om ny teknologi så är min tolkning att eftersom man inte "hänger på" så blir man mindre och mindre attraktiv som arbetsgivare PLUS att man konkurrerar med dom stora jättarna om samma kunskap som att kunna #ML/kunskapsgrafer se tweet om detta problem --> att många utlysningar aldrig tillsätts... även fast jag känner att man sänker kraven till löjligt låg nivå för tjänster inom kulturarvet....
- vad som har hänt sedan KB skapades är
Japp jag drar samma slutsats som du att informationssamhället håller på att omformas och en site som Bionomia kanske har större trovärdighet.... jag har funderat lite över detta och även frågat Denny som skapade Wikidata om hur han ser på trovärdighet/trust se video / mina tankar där jag vill ha "trust" i maskinläsbar form....
- authoritativeness
-
 M Maria_Dalhage moved this topic from Tipsa och fråga on
M Maria_Dalhage moved this topic from Tipsa och fråga on