Community på Sveriges dataportal
Hjälp folk att bada i sommar med Öppna Data! (Tips och hjälp behövs)
-
En före detta användarereplied to En före detta användare on Senaste redigerad av En före detta användare
Det vi saknar är att nyhetsmedia vaknar till liv och kommunerna så att vi kan se
- SVT anger metadata TVinslag om samma som bad = SE0441278000000137
- Att DN och andra tidningar etc. har artiklar med ämne samma som SE0441278000000137
- idag har vi följande nyhetsrelaterade egenskaper ca 30 stycken
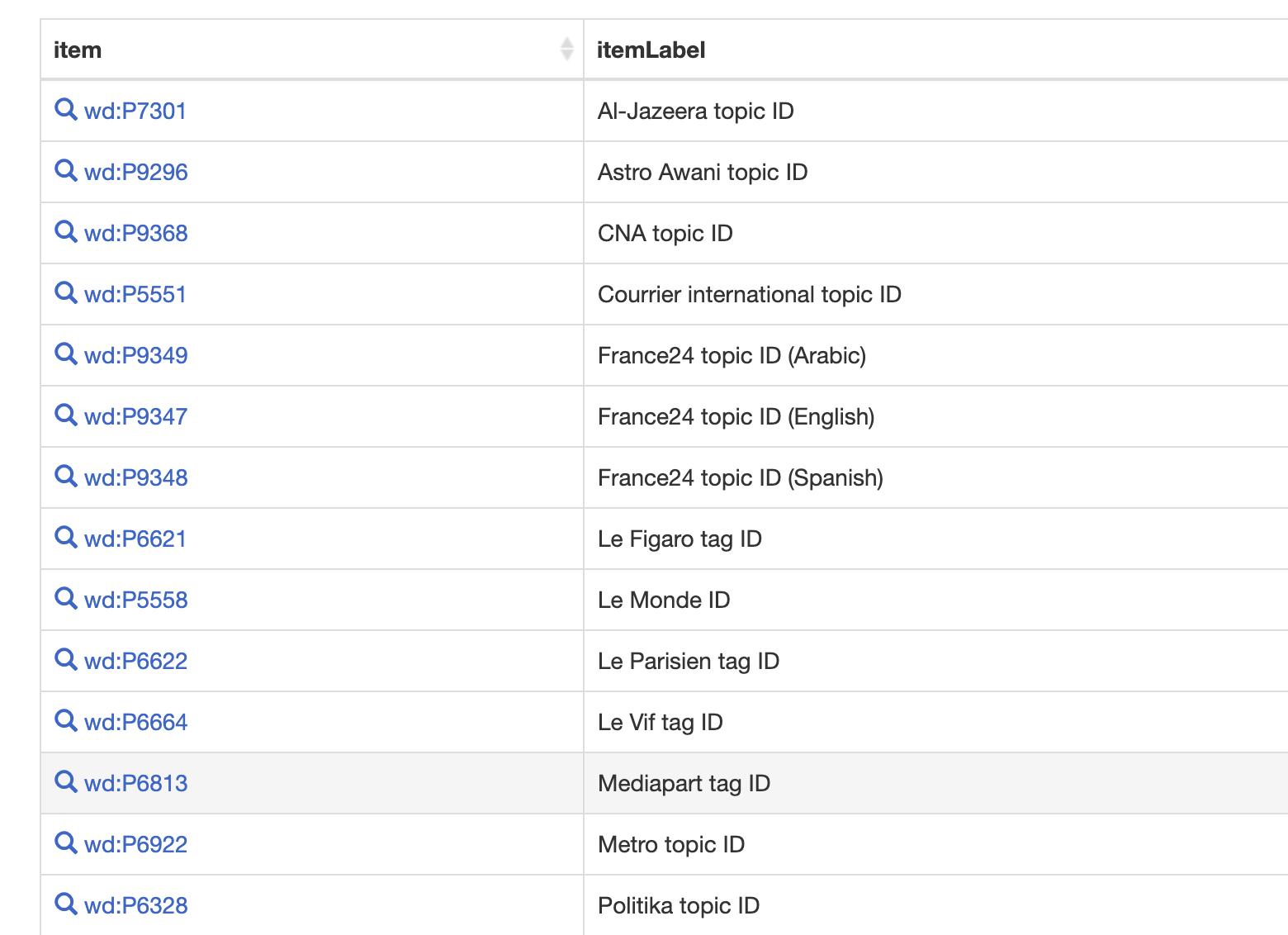
- idag har vi följande nyhetsrelaterade egenskaper ca 30 stycken
- att en kommun som tar ett beslut om ett bad säger ämne samma som SE0441278000000137
- idag finns denna info och möjliga källor för problem lite halvhjärtat i Havs API contaminationSources / plannedMeasure men som textsträngar ex Kaanan badet SE0110180000001837

-
@stefan-wallin Hej och tack, det där var en fin funktion, jag har börjat bygga en egen liknande applikation, dock hårdkodad efter specifikationens format, inte baserat på schema.
-
@tomasmonsen kul hur går tankarna att detta data skall konsumeras och att ni skapar en kunskapsgraf? Dagens "lösning" jag ser med dataset som skall laddas upp för 290 kommuner på dataportalen.se skalar inte och är i princip omöjlig att konsumera, hitta saker på osv.... känns inte som någon tänkt till. Min tro är att vi måste tidigt och tydligt i ett projekt för kommuner peka på bra mönster så att vi inte får 290 kockar som skapar sin egen soppa...
- krav man bör ha är bl.a.
- enkelt att konsumera datat
- enkelt att kommunicera med varandra/felrapportera - inte email utan riktigt system med helpdeskid
- det skall i datat finnas var man felrapporterar jmf hur Wikidata beskrivs i Wikidata
") där bugghanteringssystem anges Q2013
där bugghanteringssystem anges Q2013
- det skall i datat finnas var man felrapporterar jmf hur Wikidata beskrivs i Wikidata
- enkelt att se status på datakvaliten se exempel det projekt jag satte upp för Europeiska badplatser med Eionet bathingWaterIdentifier se Wikidata:WikiProject European Bath Waters
- kunna konsumera datat på andra språk än svenska
- API
- versionshantering av data och API
- tydlig datakatalog med ägare för olika termer jmf eionet-data-dictionary
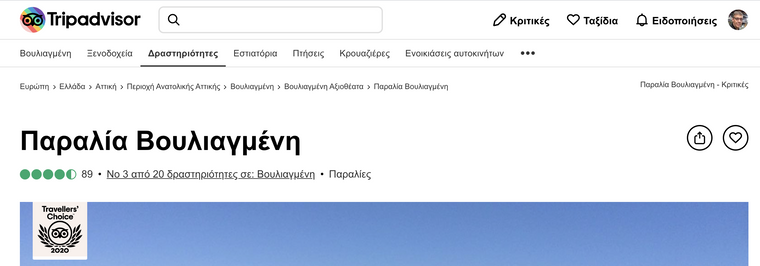
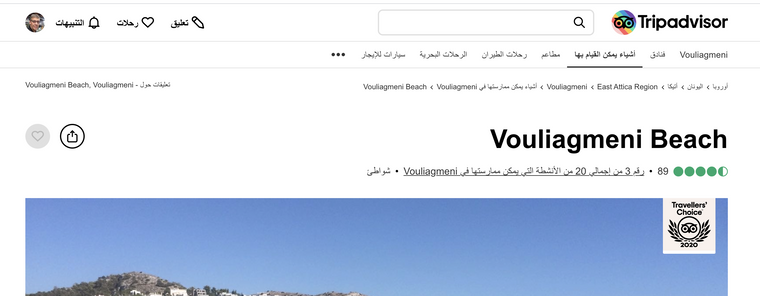
Bra exempel hur andra jobbar är Trip Advisor Vouliagmeni Beach samma som Wikidata Q107099269 där vi har egenskap Property:P3134 "TripAdvisor-ID" = 12828542
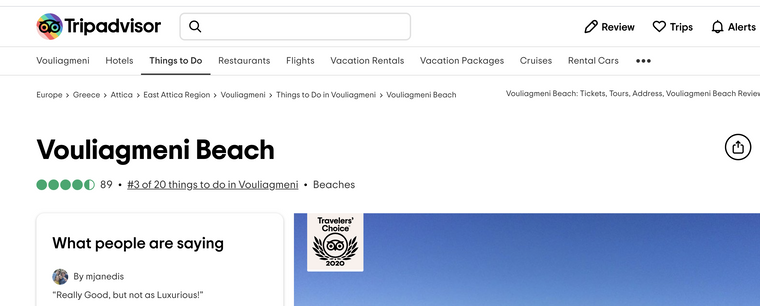
Verkar som TripAdvisory har en egen kunskapsgraf där dessa saker kopplas in --> att man kan leverera saker kopplade till denna punkt för badplatsen på flera språk etc....
- engelska https://www.tripadvisor.com/12828542
- grekiska https://www.tripadvisor.com.gr/12828542
- tyska https://www.tripadvisor.de/12828542
- arabiska https://ar.tripadvisor.com/12828542
- krav man bör ha är bl.a.
-
Hjälpa folk att hitta is dvs. prediktera när vaken upphör
-
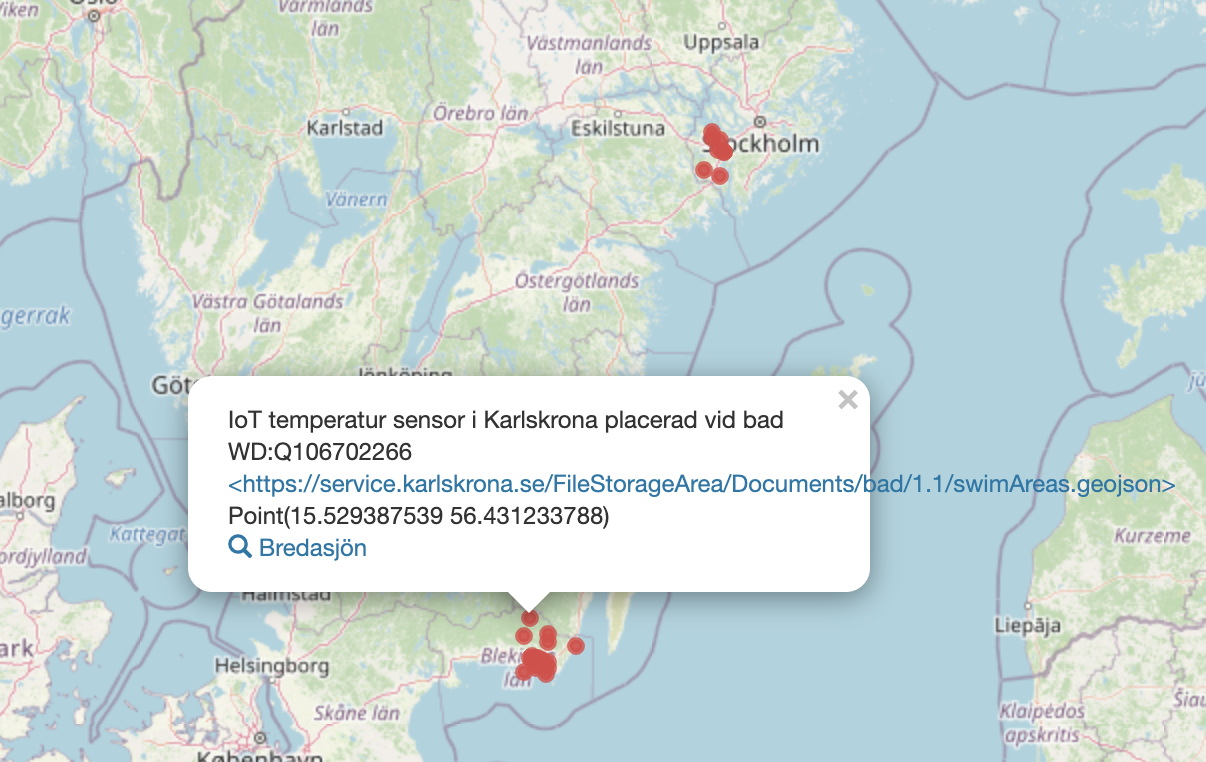
satte upp en Wikibase sandbox med de IoT jag hittat som mäter vattentemperaturer vid badplatser - iot-device.wiki.opencura.com
-
säg till om det finns flera eller lägg upp era jag hittade bara API för Södertälje och Karlskrona som har API
-
vad skall ett bra IoT API ha för data/dokumentation?
-
hur gör vi så saker blir enkla att "konsumera"? ramlar detta under några pågående projekt om ja var hittar vi vad dom gör eller inte gör
-
-
-
@tomasmonsen Hej allesamman, då är vi klara med version 1 av vår Badplatsspecifikation!
[https://lankadedata.se/spec/badplatser/](link url)Jag hoppas att ni tycker den är god nog att användas för att publicera data med, och jag hoppas att vi kommer att kunna släppa en uppdaterad version inför nästa säsong - Vi har en gedigen lista med punkter som kan göras bättre - vilket inte ska hindra dig från att leverera data redan nu!
Tack alla för hjälpen så här långt, det kommer komma fler frågor när jag börjar med version 2
")
-
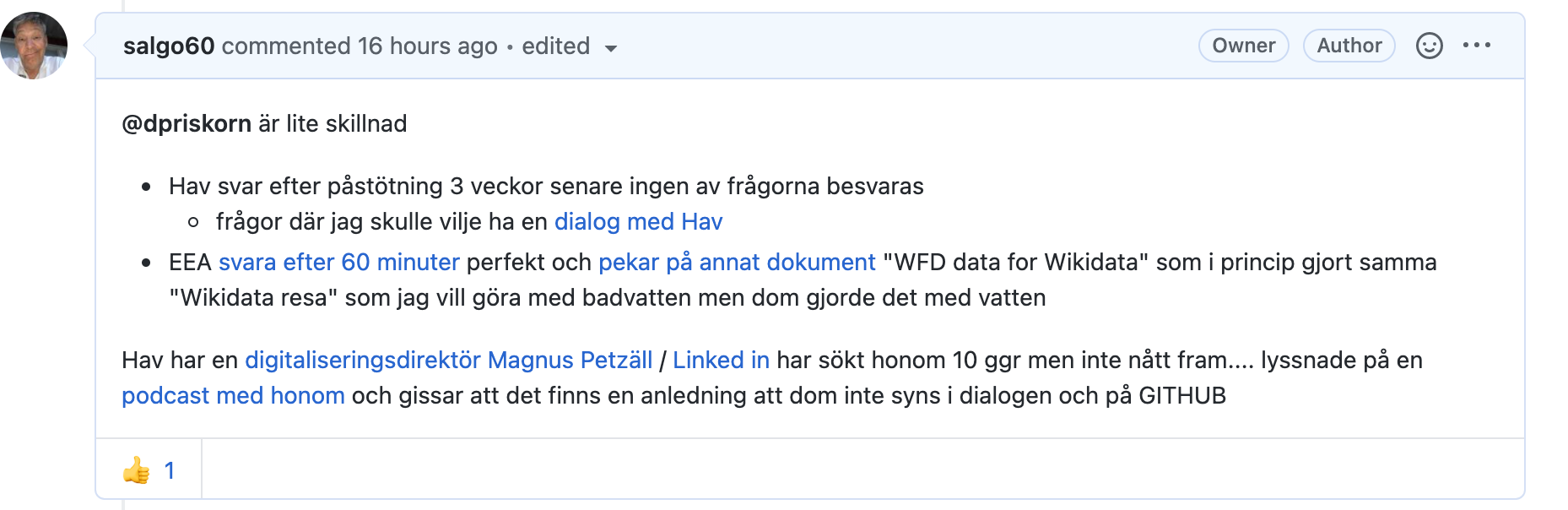
@tomasmonsen fick svar 14:50 från Hav idag se email
Ställde dessa frågor
- Har ni motsvarade Eionet Data Dictionary era termer beskrivna med ägare och hur den skapas
- Delar ni vår uppfattning att eran term NUTSKOD är illa vald för en badplats och bör ändras ? era planer?
- Var ställer vi frågor som detta? finns ni på GITHUB?
jag uppfattar att dom inte svara på någon
Öppen data då det är som bäst.... deras svar tog 17 dagar och jag skickade ny fråga om varför inget svar
- jämför detta med EU EEA 60 minuter och perfekt svar se email
-
@salgo60 Ja kvarnhjulen kanske mal långsamt ibland.
Vore ju bra om vi genom en korrekt påverkan kan få till ändringar som gör deras data bättre!Vi har lagt upp specifikationen för badplatser på Github oxå, ska se om jag hittar dit igen.. hoppas kunna bedriva arbetet där framöver med version 2 och tillika den standard jag funderar på kring temperaturer i vatten, vad hette det ObserverdQuality - vi kanske kan skala/ärva lite från modeller som finns och komplettera med fält som gör att vi kan länka datat med entries på Wikidata och i Havs lösning?
-
@tomasmonsen tackar
En fundering hur ser man koppling dataset och spec som används? Det är i specen många saker förklaras
- dataset datasets/391_2066 "Badplatser i Lidköpings kommun"
- min task Svenskabadplatser/issues/158
Denna spec gissar jag har ovan nämda kravspec som grund men hämtar jag datat från www.dataportal.se så måste jag gissa vad fältet hov_ref betyder eller har jag missat något.
Fråga: Borde det inte finnas en koppling mellan datat och den spec som använda
- dataset datasets/391_2066 "Badplatser i Lidköpings kommun"
-
@salgo60 Jo det finns det, en tanke iaf - den som publicerar datat ska i DCAT-AP nyttja attributet ConformsTo: https://www.w3.org/TR/vocab-dcat-2/#Property:resource_conforms_to
Gör man inte på det viset får man på annat sätt på distributionspunkten peka ut vilken spec man nyttjar. Så är vår tanke.
Vi har förklarat i specen att vi önskar att man gör på detta vis för att länka tillbaka till beskrivningen.
Jag noterar att vi kanske på annat sätt måste ta höjd för publicister som inte har metadata-taggat sin data på detta vis - kanske ett fält i själva datamängden som beskriver var specifikationen finns? -
@tomasmonsen coolt hittade under csv på datasets/83_2065
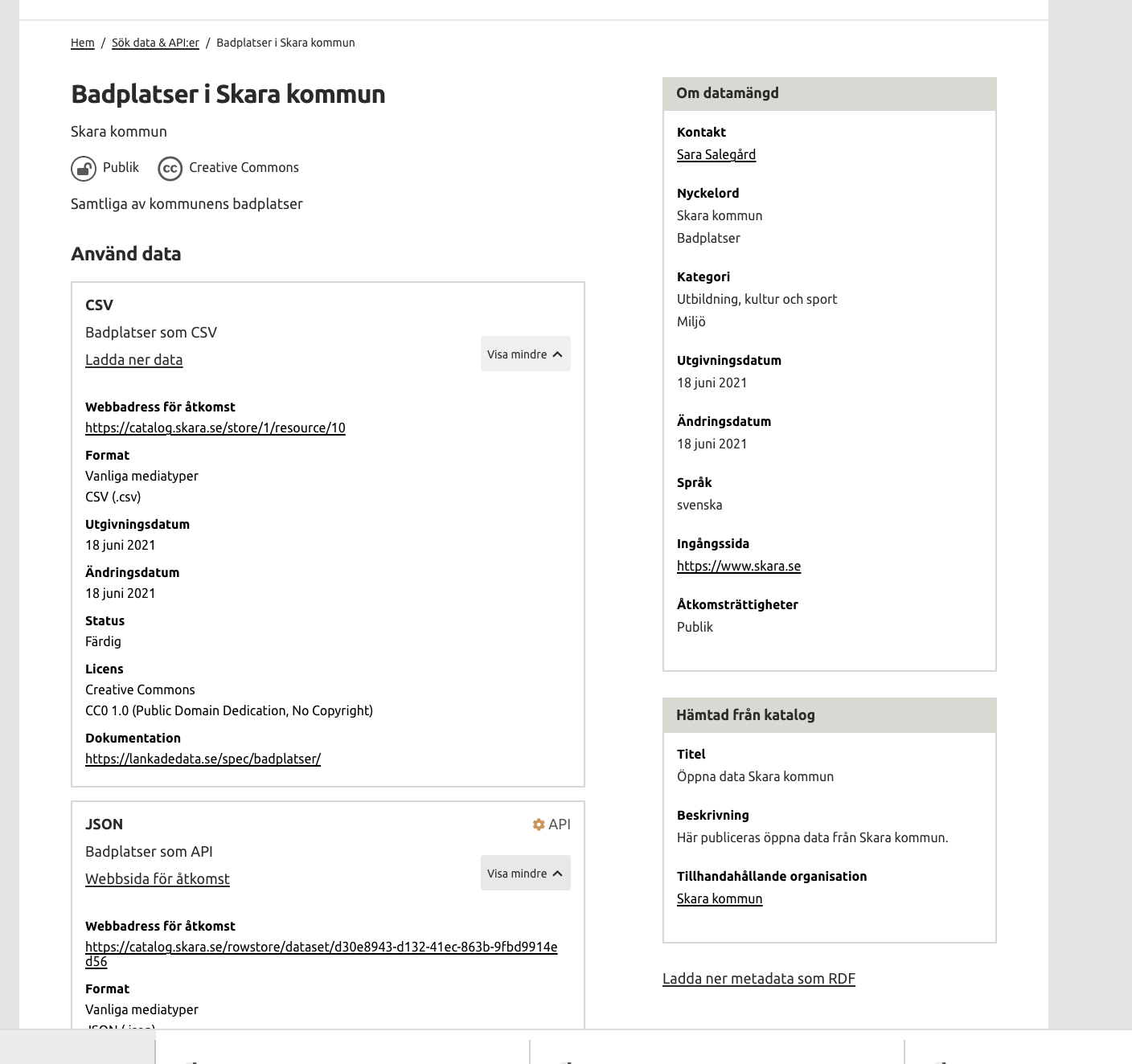
Känns som det borde visas i högerspalten... kanske och inte under ett av formaten...
- kollar i hur det ser ut nere i Europa så verkar det vara försvunnit....
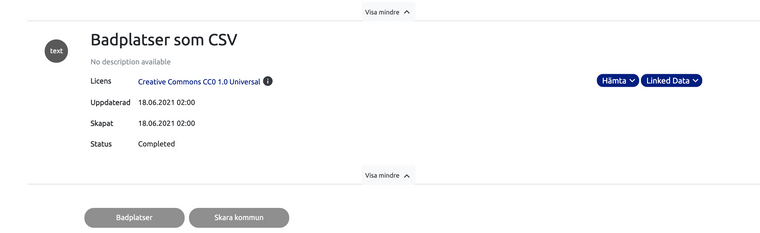
Av det jag sett av svenska portalen för dataset och Europeiska så tycker jag det vore bra att kunna peka på en GITHUB yta där det kan finns kodexempel, möjlighet att ställa frågor, se en backlog....
-
En före detta användarereplied to En före detta användare on Senaste redigerad av En före detta användare
Nu dök länk dokumentation upp
- som "Sidor"
https://lankadedata.se/spec/badplatser/ om man kör locale=sv - "Pages" om locale=en
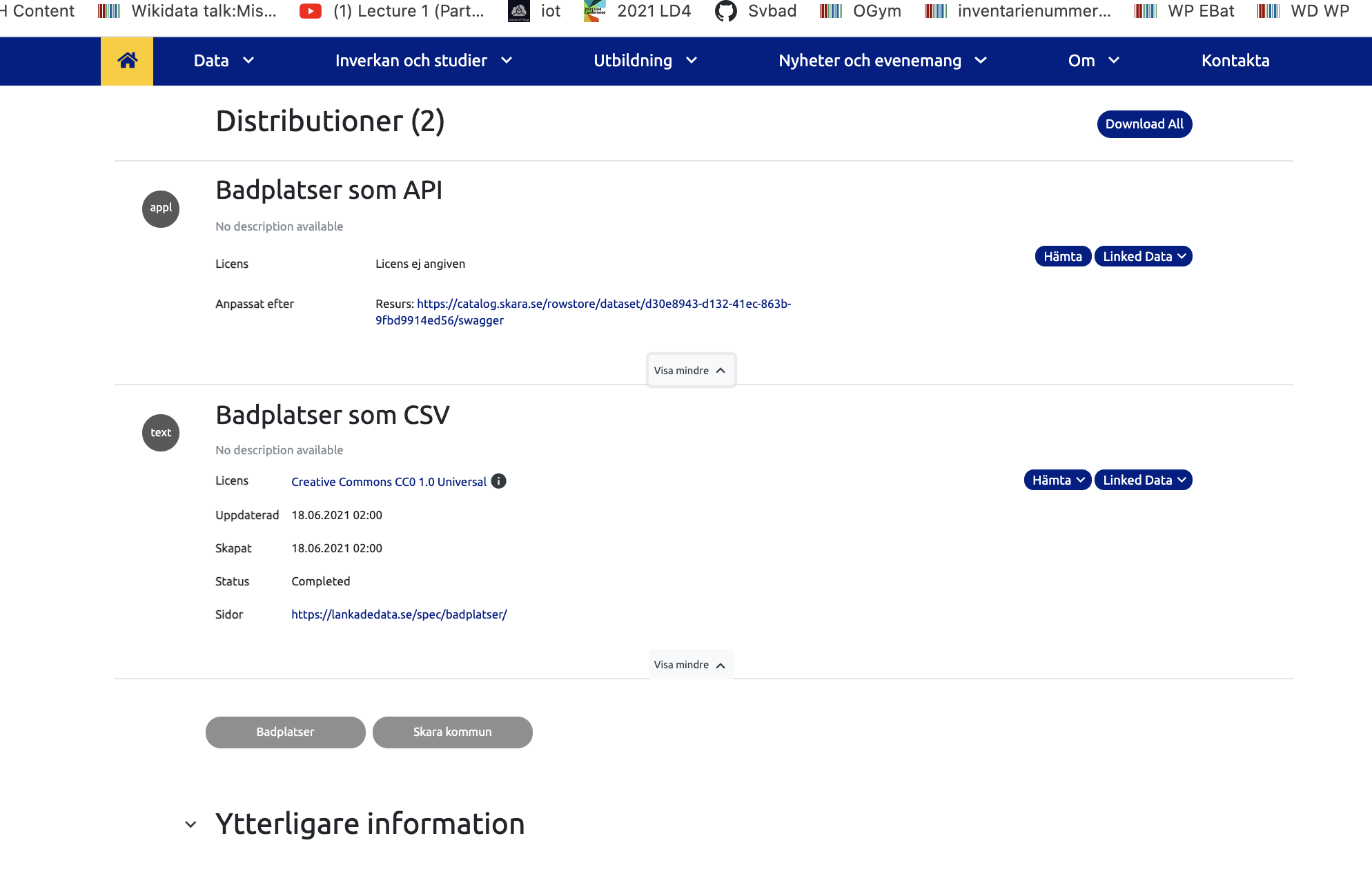
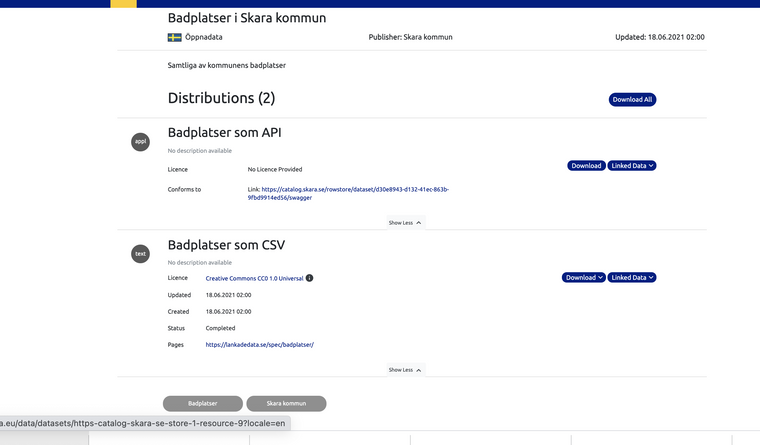
Udda saker
- nyckelord visas på svenska oberoende av språkinställning
1-1) kanske borde skicka med bathing waters som EEA kallar detta om inte data.europa.eu har språkstöd
1-2) vi tjatade lite tidigare att alla textfält borde ha språkstöd tar ni det steget så bör det lira ihop med data.europa.eu
1-3) här borde det om jag kör engelska locale=en pekas på specen på engelska med fallback svenska specen
- Badplatser som API säger licens ej angiven medans CSV har Licence Creative Commons CC0 1.0 Universal
känns som denna process med metadata behöver lite omsorg. Gissar både i användargränssnittet och för den som matar in metadata och gärna att "någon som bryr sig" specar hur det borde fungera och stämmer av med alla intressenter....
- som "Sidor"
-
Hej! @salgo60 @tomasmonsen
Specifikationen finns som sagt här: https://lankadedata.se/spec/badplatser/
Källkod finns på GitLab: https://gitlab.com/lankadedata/spec/badplatser
Ärenden: https://gitlab.com/lankadedata/spec/badplatser/-/issues
Ändringslogg: https://gitlab.com/lankadedata/spec/badplatser/-/blob/master/CHANGELOG.md -
@mattiashej tackar
min grej är att det borde sitta ihop med datat och hänga med ner till Europa dataportalen och då gärna skall datat, nyckelord, spec finnas på ett språk som folk förstår....
Jag har redan lyft in 2821 bad i Wikidata och markerat 530 badplatser på Open Street Map men hoppas att flera enkelt kan använda data och att vi får bättre data se feedback
https://www.wikidata.org/wiki/Wikidata:WikiProject_Sweden/Svenska_badplatser/Coverage2
-
@ mattias ok nu fattar jag projektet har en yta bra.!!!..
Återkommer men det känns som man borde nog ta sig en funderare om det är massa csv filer som skall göra Sverige bäst i världen på Öppen data eller om vi skall gå tillbaka till ritbordet och ifrågasätta dagens svenska dataportal och att skicka dataset till Europeiska dataportalen data.europa.eu ...
Det lilla jag ser av Öppen data så har inte DIGG vuxit och kan underhålla tekniska lösningar (tänker på att det saknas styrning, felrapportering, se senast först verkar fortfarande vara skakigt, sökningen skulle man komma tillbaka med osv...) och samma känns med Europeiska dataportalen dom känns som samma andas barn att det är mer flashiga PDF:er och tweets än riktig verkstad....
Skall data konsumera 2021 i hela Europa så måste vi
-
enkelt ha stöd för flera språk
-
nyckelord för ett badvatten data skall i möjligaste mån också finnas i en kunskapsgraf eller liknande så man kan hämta datat på sitt språk med kopplingar/relationer... skicka fält som heter kommunkod till EU gör det nog inte helt enkelt för en italienare att förstå...
-
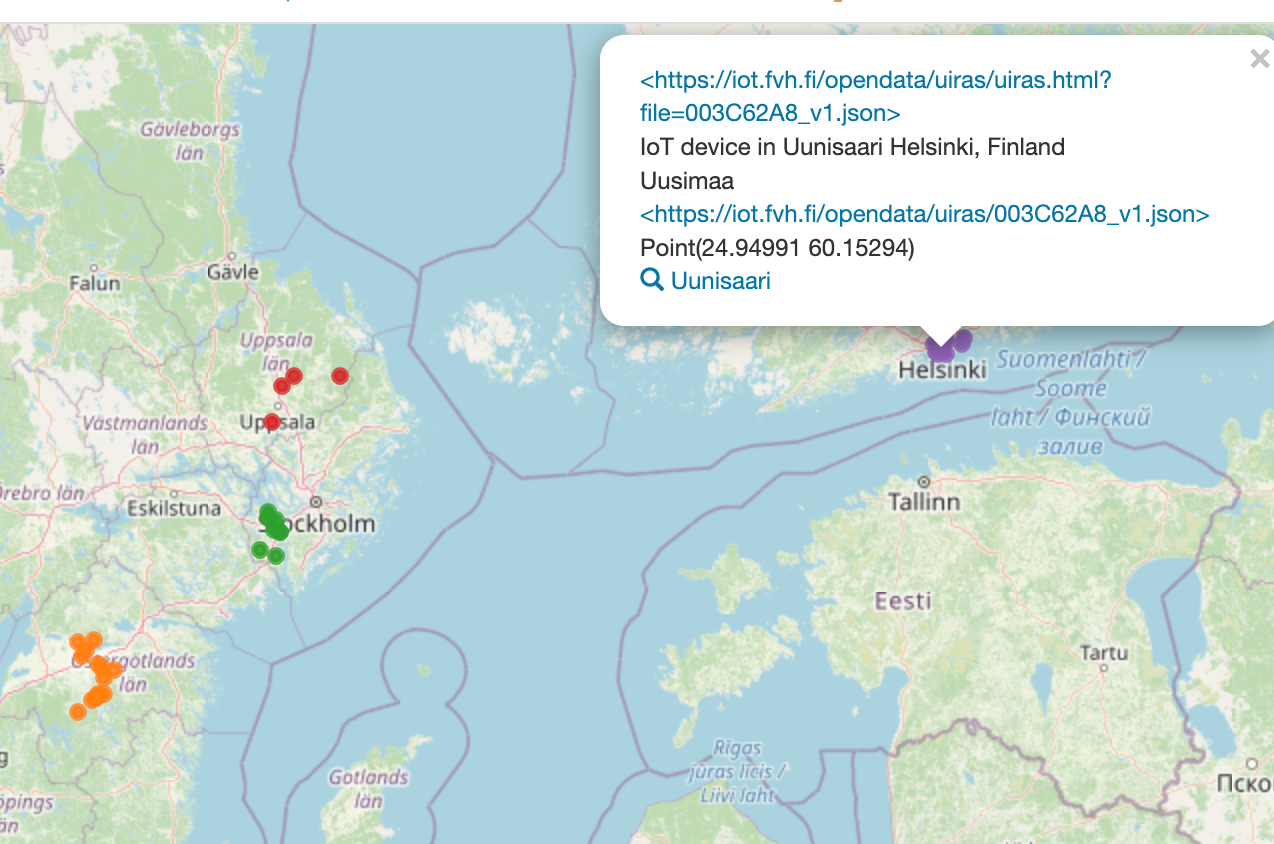
tror min lilla test med IoT device visar att det blir vildvuxet och vi måste pröva oss fram till bättre lösningar där kanske en karta över alla badvatten IoT är ett litet steg att förenkla...
-
även kommunikationen mellan aktörer måste mogna (bra att ni har en yta), jag har i veckan slagit mig blodig mot Havsmyndigheten och blivit smått deprimerad av att se hur bra det skulle kunna vara efter att ha kommunicerat med Havs motsvarighet på Europa nivå EEA och fått svar på 60 minuter där dom även pekar på liknande projekt --> detta spar veckor av dödsdömda försök
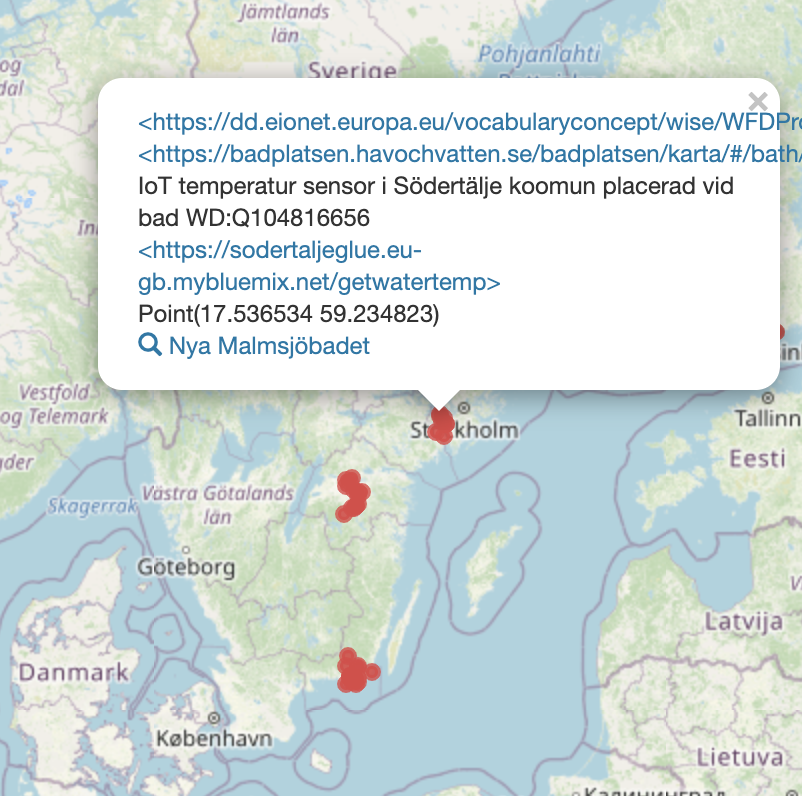
Min erfarenhet att flytta metadata iform av penningtransaktioner där så visste alla vad vi flyttade och varför och saker hade specats i årtionden.... i ett öppet och "löst kopplat" landskap är detta 100 ggr svårare och skall sedan datat kunna hämtas av folk i hela Europa eller "galningar" som vill mäta vattentemperaturen för att se när isen kommer... så behövs mycket med tålamod och kommunikation
-
-
Apropå denna tråd och https://community.dataportal.se/topic/270/badplatser-open-api
https://sverigesradio.se/artikel/badplatsen-dar-du-far-veta-vattentemperatur-innan-du-kommit-dit
P4 Stockholm
Mattias Rindefors står i förgrunden av bilden, bakom honom ser man en brygga och vatten.Mattias Rindefors är innovationssamordnare inom digitalisering och IT på Upplands-Bro kommun. Foto: Björn Lindberg/Sveriges Radio
SMART BADPLATS
Badplatsen där du får veta vattentemperatur – innan du kommit dit
1:14 min
Publicerat igår kl 14.01Smarta telefoner, smarta högtalare, smarta TV-apparater och nu – en smart badplats.
Det är Lillsjöns badplats i Upplands-Bro som numera kallas för just en smart badplats.
Här kan man se folkmängd, parkeringsplatser och vattentemperatur, redan innan du kommit dit. -
@jonor sa i Hjälp folk att bada i sommar med Öppna Data! (Tips och hjälp behövs):
https://sverigesradio.se/artikel/badplatsen-dar-du-far-veta-vattentemperatur-innan-du-kommit-dit
badvatten är ganska tröga system så är det 25 grader idag så är det inte is imorgon ... jag har försökt att kolla om man kan sammanställa badvattentemoeraturer för skridskoåkare som letar nyis... nyis som knastrar är magiskt jag 2010 video uppe vid Högbo...-
IoT sensorer för att mäta badvatten temp och prediktera isläggning Issue 156
-
Jag testade skapa en wikibase för IoT och vattentemperatur
Finns snygg web hos Havs och vattenmyndigheten där exempelvis Stockholms stad uppdaterar sitt data bra...
- Lillsjön
- EU persistent identifierare SE0110139000001714
- API svenska badplatsen.havochvatten.se api/testlocationprofile/SE0110139000001714
- API svenska badplatsen.havochvatten.se api/testlocationprofile/SE0110139000001714
hade man varit lite mera digital mogen så hade det varit Linked data och levererats på flera språk som somaliska arabiska... senast då jag prata med handläggaren så var inte temperaturer aktuellt...
- badkartan 047735
- naturkartan
- instagram plats id 514474412353683
- Open Street Map way/135106888
- WIkidata Q56641316
- EU persistent identifierare SE0110139000001714
FEL hos Havsmyndigheten man knyter även snyggt problem till baden föroreningskällor men det är textsträngar inte publika identifierare som pekar in på kommunens egna beslut / åtgärdslista... eller organisationensid / byggnadens id next level
-
-
@tomasmonsen snyggt! Värdefull sammanfattning. Ser ut att finnas en hel del att göra. Ser fram emot att följa ert arbete.