Community på Sveriges dataportal
Hjälp folk att bada i sommar med Öppna Data! (Tips och hjälp behövs)
-
-
Detta inlägg är raderat!
-
Skapat ett förslag i Wikidata för EU identifieraren bathingWaterIdentifier
- se Wikidata:Property_proposal/bathingWaterIdentifier
- alla kan rösta som har ett wiki konto (går även utan konot tror jag men rekommenderas ej)
** Wikipedia skapa ett användarkonto
syntax för positiv röst:
-
{{S}} - ~~~~
-
mer om Svenska Badstränder jag lyfter in på GITHUB
-
@jonor Man får ett URI av Metasolutions katalogtjänst, för hela datamängden. Möjligt att den skulle kunna användas, men detta URI kan man även ändra på, vilket gör att det finns risk att det redigeras bort eller ändras över datats tid, då skulle URI vara en sak för hela datamängden/distributionen och inte ha koppling till IDt per rad/entitet. Jag förstår tanken och tycker det hade varit snyggt, men jag tror tyvärr inte det är stabilt nog. Det hade ju så klart varit önskvärt om katalogtjänsten hade ett centralt register som kunde provisionera ut nummer/identiteter via centralt register som garanterar unika värden. Detta finns ej i produkten men kanske kunde vara en förbättringsförslag. Man tar ju på sig ett stort ansvar med ett sånt register och frågan är om man vill ha det - jag frågar leverantören/pitchar idén.
Nu lutar det åt att jag får sätta samman ett namn av kommunkod och badplatsens namn.
-
@salgo60 Hej jag har fått svar från Tillgänglighetsdatabasen, här finns deras API: https://td.portal.azure-api.net/
Verkar vara gratis att registrera sig, men det krävs nyckel så APIt är inte helt öppet, ska regga mig och se om vi kan läsa ut unika IDs på de olika platserna.
-
@tomasmonsen tackar jag extraherade det nesta se GIST
- min oventskapliga koll vilka som kopplar badplatser till Tillgänglighetsdatabasen så är Göteborg duktiga och länkar deras sida (dock har GBG störigt långa URL;ar
Exempel på annan fördel att ha dataseten i en Kunskapsgraf att man vet vilket data som är en badplats och vilka som länkar ett visst ställe som ex. Tillgänglighetsdatabasen. Och med en sökfrågan förstårRösta på ny Wikidata egenskap - bathingWaterIdentifier
- tycker ni föreslagna egenskapen är bra så in och rösta länk
- har ni inte konto registrera er
- ex. syntax för positiv röst är
{{S}} - ~~~~
Bilder på badstränder
Uppmuntrar er att dela bilder på era badstränder med fria licenser. Variant är att ladda upp direkt på WIkicommons** exempel hur jag kopplat ihop bilder för badplatser dvs. vi anger att en bild avbildar en badplats som finns i Wikidata
*** mer om hur bilder hanteras med strukturerad data video
-
Finns det några visionärer med pondus inom Öppen data som kan styra upp badvatten och lite till
") här finns en utlysning med drönare, naturism....
här finns en utlysning med drönare, naturism....- Användning av positioneringsdata från exempel mobiltelefoner, fordon, fartyg för att kartera friluftsliv och naturturism.
- Användning av luft- och vattendrönare vid insamling av data.
- ....
Utlysningen


-
@tomasmonsen Ok, jag tänkte att man kanske kunde få en URI under dataportal.se eller liknande namnrymd som förvaltas långsiktigt av DIGG i samband med att man registrerar en datamängd, som en form av stödtjänst, men jag är faktiskt inte riktigt klar över vad som förväntas av en registerhållare för beständiga identifierare.
-
@jonor Ja det hade varit toppen om någon myndighet kunde ta på sig det jobbet, att upprätta mängder av unika IDn som datapublicerare kan få "hämta ut". Tror inte att man vågar/vill ta på sig ett sånt jobb, så jag får "hitta på" en metod för att skapa ett unikt ID. Funderar på att skapa ett kopplat till geografiska platsen, alltså en kombination av siffror från koordinatsystemet...
Du kanske kan sätta ihop en sån förväntan och presentera för Digg
") De kanske är sugna på att upprätta en sådan databas - skulle tänka mig att det skulle vara uppskattat av många!
De kanske är sugna på att upprätta en sådan databas - skulle tänka mig att det skulle vara uppskattat av många! -
@salgo60 Jag har fått svar från Tillgänglighetsdatabasen och det verkar inte som om man har beständiga IDn för sina objekt heller. Det närmaste vi kommer är det URL som de har för varje plats, som ju delvis består av namnet på verksamheten som datamängden beskriver, så det känns inte heller helt stabilt över tid (saker kan ju byta namn..).
Tyvärr kommer jag därför att behålla attirbutet "td-url" i min specifikation för att man iaf i bästa fall kan peka ut verksamheten mha ett URL till TillgänglighetsDatabasen.
@salgo60 ang. "bathingwaterIdentifier" - är det alltså ett format som är precis samma som NUTSKOD som Havs- och vattenmyndigheten har skapat som ska lagras på det attributet, eller är det ett attribut för badvattenidentifikation där man kan skriva vad som helst?
Jag vet inte när själva IDt skapas - det blir bara ett ID om man väljer att publicera i deras datamängd och det kan nog inte vem som helst göra samt att inte alla badplatser är skapade där. Är det ett format som Havs- och vattenmyndigheten helt själva skapat och hittat på kanske det inte funkar för icke-eu-land eller eu-land som saknar samma motsvarighet till myndighet?
-
Detta inlägg är raderat!
-
@tomasmonsen nix vet ej jag samlar frågor på hög se Svenskabadplatser/labels/Havs- och vattenmyndighetens
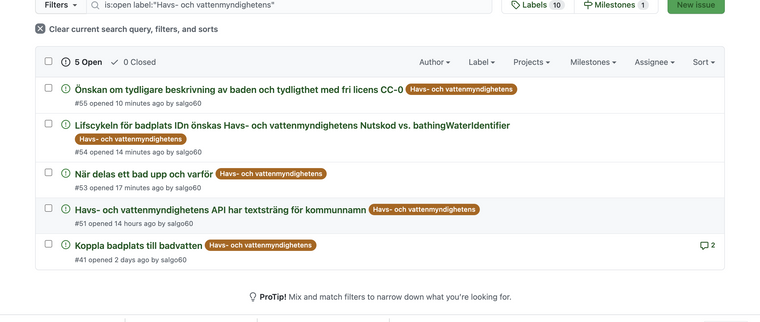
Tomas har du ett GITHUB användarid så kan jag lägga till dig i projektet...
-
@salgo60 TGBMonsen, lägg gärna till mig. Jag är ingen fantom på Github men kanske kommer att bli. Det här projektet har varit väldigt lärorikt!
-
@tomasmonsen du är tillagd testa gärna hej vilt så du får en känsla av GITHUBs fördelar/brister och möjligheter. Säg till så kan vi dela skärm så kan jag visa hur snyggt Our World in Data sammanställer > 200 länders Covid vaccineringsdata i GITHUB se min beskrivning om detta

Jag nås på telegram salgo60 , twitter salgo60 eller lite olika nummer 0735152802 0705937579
- nytt WD egenskapsförslag för Badkartan finns att rösta på
-
Hej igen allesamman, nu är det "final push" till leverans av specifikationen och några frågor kvarstår som jag behöver ha hjälp med, framför allt språk:
Språkstöd - Hur ska jag erbjuda språkstöd för fler än ett språk.
Min ide: Lägg till "lang_code" som attribut, använd ISO639-1 för att sätta en kod "EN" t.ex. och då måste resten av filen vara på engelska. Den som då har behov att dela data på fler språk än ett får skapa flera filer och använda olika spåk i dem, och berätta med lang_code vilket språk filen är på. Man får sedan i metadata med DCAT-AP markera vilket språk filen har.
Andra idéer: Skapa fler språkfält, där du valfritt kan lägga upp till 5 olika språk, fritextfälten skulle då behöva utökas med 4 till och varje sådant fält ha en språkkod kopplat:
- descripition_1 kopplas med attribut lang_code_1. Du skriver på svenska i "description_1" och sätter "SE" i lang_code_1.
- Description_2 kopplas med attribut lang_code_2. Du skriver på arabiska i "description_2" och sätter "AR" i lang_code_2.
- ...osv.
Finns det andra ideer? Tänk på att formatet är flatfil typ CSV för att underlätta för dataproducenten som troligen ofta inte har verktyg att hantera JSON-objekt med arrayer av värden...
Hilfe!
Länk till specen: https://docs.google.com/document/d/1GxNucD_E_eoHnlyJAL3tjCel-BdWvwF5TB_lYl7bs94/edit?usp=sharing
(Skriv gärna kommentarer och skapa förslag direkt i dokumentet)
-
@tomasmonsen sa i Hjälp folk att bada i sommar med Öppna Data! (Tips och hjälp behövs):
Hej igen allesamman, nu är det "final push" till leverans av specifikationen och några frågor kvarstår som jag behöver ha hjälp med, framför allt språk:
Språkstöd - Hur ska jag erbjuda språkstöd för fler än ett språk.
Min ide: Lägg till "lang_code" som attribut, använd ISO639-1 för att sätta en kod "EN" t.ex. och då måste resten av filen vara på engelska. Den som då har behov att dela data på fler språk än ett får skapa flera filer och använda olika spåk i dem, och berätta med lang_code vilket språk filen är på. Man får sedan i metadata med DCAT-AP markera vilket språk filen har.
Andra idéer: Skapa fler språkfält, där du valfritt kan lägga upp till 5 olika språk, fritextfälten skulle då behöva utökas med 4 till och varje sådant fält ha en språkkod kopplat:
- descripition_1 kopplas med attribut lang_code_1. Du skriver på svenska i "description_1" och sätter "SE" i lang_code_1.
- Description_2 kopplas med attribut lang_code_2. Du skriver på arabiska i "description_2" och sätter "AR" i lang_code_2.
- ...osv.
Finns det andra ideer? Tänk på att formatet är flatfil typ CSV för att underlätta för dataproducenten som troligen ofta inte har verktyg att hantera JSON-objekt med arrayer av värden...
Hilfe!
Länk till specen: https://docs.google.com/document/d/1GxNucD_E_eoHnlyJAL3tjCel-BdWvwF5TB_lYl7bs94/edit?usp=sharing
(Skriv gärna kommentarer och skapa förslag direkt i dokumentet)
Jag tycker som Magnus att ni ska frångå CSV och göra nestlad JSON istället. CSV är so yesterday och ganska inflexibelt. Om kommunerna inte klarar av att leverera JSON istället för CSV då är det ändå dödfött från början skulle jag säga.
Kolla själv på exemplet Magnus gjort: https://gist.github.com/salgo60/f306fa23c28e2678928b2c1e9be78689
Det formatet ligger för övrigt mycket närmare exportformatet i JSON från Wikibase som syns här https://www.wikidata.org/wiki/Special:EntityData/Q5.json.
De som byggd Wikidata har lyckats skapa ett semantiskt system som kan hantera den komplexitet som vi möter i världen. Att inspireras av dem kanske kan vara en nyckel till framgång. Många professionella inom IT-industrin jobbar redan mot Wikidatas olika API:er och använder datan på olika sätt (t.ex. Google) och det betyder att om ni använder nestlad JSON då använder ni något när en industristandard för informationsutbyte.
Se även Sello.io som har liknande nestlad JSON där språkfält också är nestlade se https://docs.sello.io/#getting-products
-
Tomas svarade i Google-diskussionen som inte arkiveras så därför får ni en kopia här för eftertiden:
"Anonym
20:54 30 apr.
•
Kommentarer av
Vald text:
description
Där det förekommer fritext vore det kansek smart att ha möjlighet att utöka med andra språk?
Dennis P
Dennis P+1 Vi lever i en värld med många språk. Alla i Sverige pratar inte bra svenska. Turister tex.
10:07 1 maj
Isak Styf
Isak StyfBra tanke, men då kanske det kan vara en idé att hellre styra det via requesten med Accept-Language eller liknande. CSV blir ganska begränsande för att hantera flera språk.
20:38 3 maj (redigerad 20:32 4 maj)
Tomas Monsén
Tomas MonsénJag gillar idén men det blir svårt att implementera i CSV då det skulle behövas flera olika fält för att tillåta översättningar av text. Hur många olika spåk ska jag isåfall skapa fält för? Jag tänker mig att det blir upp till implementatören att använda fältet så som denne vill.
I metadatat för datakällan, metadata som taggas med DCAT-AP, kommer man att kunna ange språk på datat. Där står det om det är svenska eller engelska.
I dataspecifikationen finns bara två fritextfält och det är relativt enkelt att lägga till ett fält för ett annat språk. Jag skapar ett som heter description_altlang där man kan skriva ett alternativt språk (förslagsvis engelska). Du kan där skriva vilka språk du vill och den som sedan konsumerar datat får välja vilket av fälten (description = svenska) och (description_altlang = annat språk) vilket som ska användas. Rekommendationen blir engelska men du kan skriva vilket du vill.
Kan det funka som en lösning?
11:00 6 maj
Tomas Monsén
Tomas MonsénJag har beslutat att rekommendera dataproducenten att översätta description till engelska, alternativt publicera ytterligare en engelsk version av datamängden istället.
Vad tror ni om det?
12:38 7 maj
Isak Styf
Isak StyfJag tycker att det låter bra.
13:17 7 maj
Tomas Monsén
Tomas MonsénVi behåller den, förtydligare att man kan skriva en översättning och/eller förse icke-svenskspråkiga med en variant på filen med annat språk. Engelska, franska, tyska, finska, norska osv. .
15:11 7 maj
Tomas Monsén
Tomas Monsén
Markerad som löst
15:11 7 maj
Magnus Sälgö
Magnus Sälgö
Öppnad på nytt
att inte stödja flera språk känns 1990... vi vill ha det i datat och inte några konstigheter med att ropa med olika "Accept-Language" se GIST tror det bara är att inse att turister folk i Sverige inte alla pratar svenska https://gist.github.com/salgo60/f306fa23c28e2678928b2c1e9be78689
06:15 I förrgår
Tomas Monsén
Tomas MonsénDu får gärna hjälpa mig att förklara hur jag på ett bra sätt ska kunna ha stöd för flera språk - jag tänker mig att som specifikationen ser ut nu kan du ange och skriva den på vilket språk du vill, och sedan får du i metadatat i katalogen specificera vilket av de olika språken du önskar?
Eller ska fritextfälten följas av en språkkod där du som producent av datat först skriver in fritexten och sedan i språkkoden anger vilket språk det är skrivet på typ "The beach is located... " språkkod: EN ?
Jag behöver häjlp med förslag på hur jag ska lösa det rent praktiskt annat än så jag tänkt genom metadatat i publicerande katalog.
13:56 I går
Tomas Monsén
Tomas MonsénJag har tittat på ditt förslag och det är jättesnyggt, problemet är att vi samlar data som en CSV - det är det formatet jag måste förhålla mig till eftersom jag inte tror att det finns verktyg i kommunerna för att bygga nästlade JSON med arrayer av värden för attribut. Om du kan komma på ett bra sätt att göra det i CSVn som sedan blir enkelt maskinläsbart är jag all ears, men jag vet inte hur. Det enda jag kan tänka mig nu är att jag
: Lägger till 3 ytterligare fält för allt som är fritext.
: Lägger till 4 ytterligare fält som anger vilket språk fritexten är skriven på.Då får man möjlighet att ange 4 språk per fil, och du kan välja själv vilka språk, genom att sätta språkkodningen i "kodfältet".
description_1
lang_code_1description_2
lang_code_2...
Kan det funka? Hur många sådana behövs isåfall ?
10:11 I dag
Magnus Sälgö
Magnus Sälgöskippa CSV dumt krav 2021 är mitt svar viktigare med tydliga krav som man uppfyller
12:55 I dag
Tomas Monsén
Tomas MonsénHej då kommer det inte att bli någon data publicerat tyvärr, så jag får välja en halv-mesyr där jag önskar att innehållet språkkodas mha metadata.
Det finns inga verktyg mig veterligen jag kan sätta i händerna på en "vanlig" tjänsteperson i kommunen som kan generera en sådan utfil/utdata. Datat finns inte i verksamhetssystem som kan leverera data i detta utdataformat. Det kommer, om jag byter detta utdataformat, att ta flera år att få ut någon data, om ens någonsin.
Tyvärr är vi, enligt min bedömning, i det läget i ÖppnaData-Sverige att detta är den minst dåliga vägen fram för att över huvud taget få ut någon data.
15:13 I dag
Tomas Monsén
Tomas MonsénJag blir tvungen att klippa av tråden här och rekommendera att den som behöver publicerar fler filer med språkkodning satt på dcterms:language property i DCAT-AP som vi rekommenderar att man använder för att metadatatagga sin distribution. Jag har flyttat hela frågan om språk till "Appendix D, Restlista". Kika gärna där och lägg till förslag på fler förbättringar som vi ska försöka få med till nästa version av datamodellen/Specifikationen!""
#########################
För mig verkar detta mycket intressant. Det ger ett litet inblick i hur myndighetspersoner resonerar när de designer och bygger system och lösningar.
Hur svårt är det då att skapa nestlad JSON egentligen kanske du som inte kan programmera frågar?
Svaret är att om du har ett minimum av kunskap i t.ex. Python då går det alldeles bra med 5-10 minuters arbete.
Det enda det kräver är
- basala kunskaper om JSON
- kunskap om loopar
- möjlighet att skriva ut från programspråket till disk i giltigt JSON-format.
Jämför det med CSV:
- kräver basal kunskap om tabeller och deras rader och kolumner
- kräver basala kunskaper i kalkylarksprogram
- kräver kunskap om exportfunktione ni ett kalkylarksprogram
Min bedömning är att det är marginellt svårare att exportera i JSON än i CSV och att det är väl värt mödan om ni frågar mig.
Min gissning är att en elev i gymnasiet som har en kurs i programmering skulle kunna fixa att skapa en nestlad JSON på 1 timme.
Om kommunerna inte klarar av att anställa folk med basala kunskaper om programmering, databehandling, datahantering och dataexport i standardiserade format och enligt specifikationer då är det någonting som måste åtgärdas genast.
Nog med prat nu: Såhär skapar du en nestlad JSON á la Magnus:
Ladda ner Pycharm på din dator
Skapa ett projekt
Läs https://csharpskolan.se/article/nastlade-loopar/
Klona eller kopiera denna kod och kör programmetimport json from pprint import pprint # Simple example of nestled JSON generation raw_data = [ dict( id="SE0441273000000001", en='bathing place näsholm', sv='badplats näsholm', ), dict( id="SE0441273000000002", en='bathing place kastholm', sv='badplats kastholm', ) ] # detta är vår dictionary som håller all data som ska skrivas till disk data = {} public_baths = [] languages = ["en", "sv"] for bath in raw_data: entry = {} # dictionary entry["Eionet bathingWaterIdentifier"] = bath["id"] names = {} # dictionary for language in languages: if language in bath.keys(): names[language] = {'language': language, 'value': bath[language]} entry["name"] = names public_baths.append(entry) data["public_baths"] = public_baths pprint(data) with open("sample.json", "w") as outfile: outfile.write(json.dumps(data))Output:
{'public_baths': [{'Eionet bathingWaterIdentifier': 'SE0441273000000001', 'name': {'en': {'language': 'en', 'value': 'bathing place näsholm'}, 'sv': {'language': 'sv', 'value': 'badplats näsholm'}}}, {'Eionet bathingWaterIdentifier': 'SE0441273000000002', 'name': {'en': {'language': 'en', 'value': 'bathing place kastholm'}, 'sv': {'language': 'sv', 'value': 'badplats kastholm'}}}]} -
@tomasmonsen angående CSV vs. JSON så håller jag med om att JSON vore att föredra.
Jag förstår ditt verksamhetsproblem med vart datan kommer ifrån. Om man bara vill komma igång så gör du ett JSON-Schema, klistrar in på https://www.jeremydorn.com/json-editor i "Schema"-rutan och då får du GUI högst upp.
Högst upp till höger har du en direkt-länk-skapande länk, när du matat in ditt JSON-schema så kan du länka in ditt JSON-schema i editorn och dela den länken med personalen som ska fylla i.
Process:
- Personalen laddar om länken
- Personalen fyller i formuläret
- Personalen klickar på JSON-boxen högst upp.
- Personalen kopierar JSON-koden och klistrar in i ert samlingsdokument/tabell
- Nästa badplats, börja om från steg 1.
-
@stefan-wallin snyggt !!!
- nästa problem är hur kommer detta att skala?
- skall 290 kommuner ladda upp egna JSON i DIGGs dataportal vilket känns som det skulle bli omöjligt att skala och hämta data känns som vi är tillbaka till detta med När kommer kunskapsgrafen
- nästa problem är hur kommer detta att skala?
-
Vi kopplar nu in Europeiska badvatten på Wikidata lite långsamt SPARQL
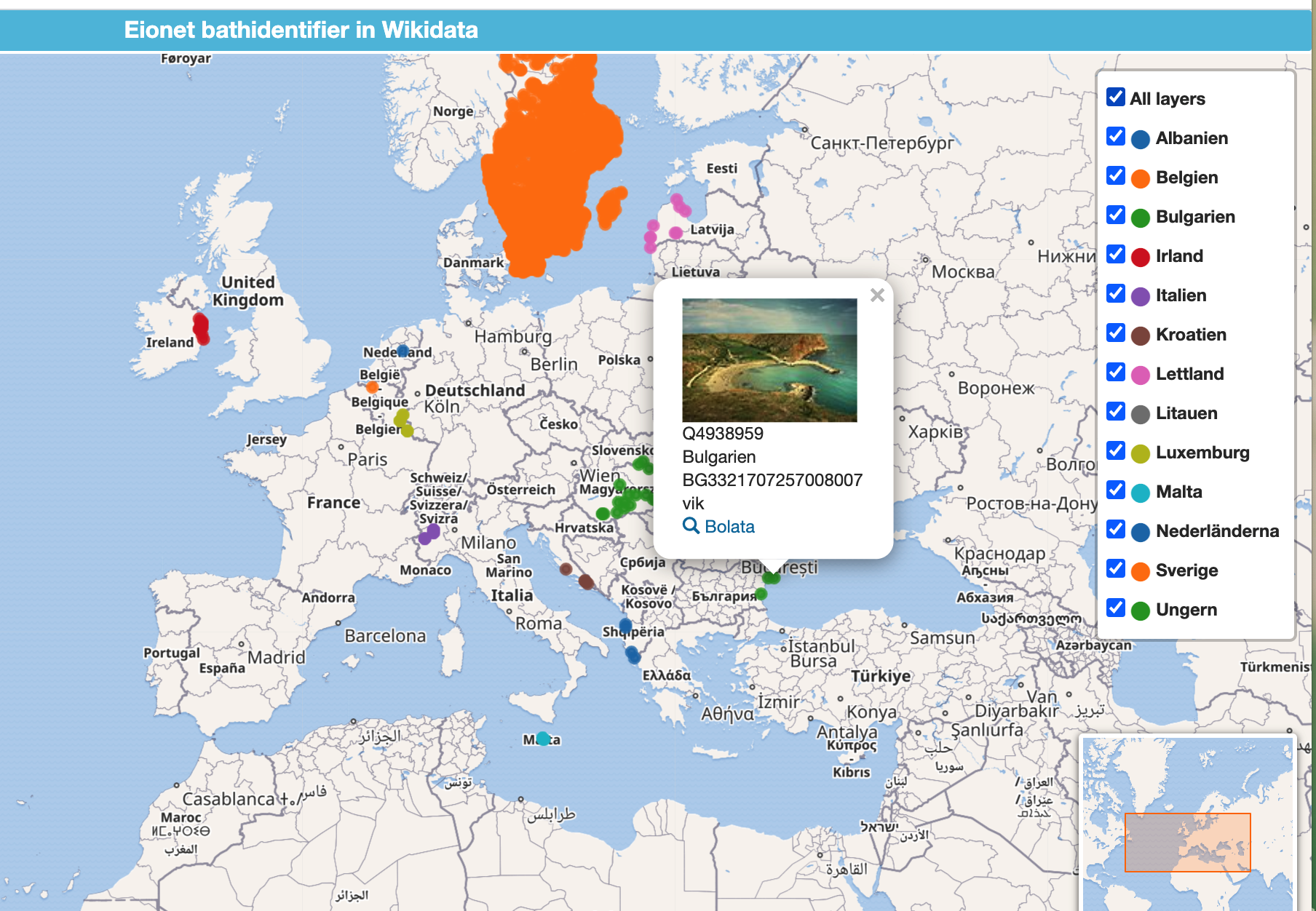
På Wikidata i vår kunskapsgraf kopplar vi in i Sverige
- badkartan.se där man kan läsa vad folk tycker om badet WD Property:P9615
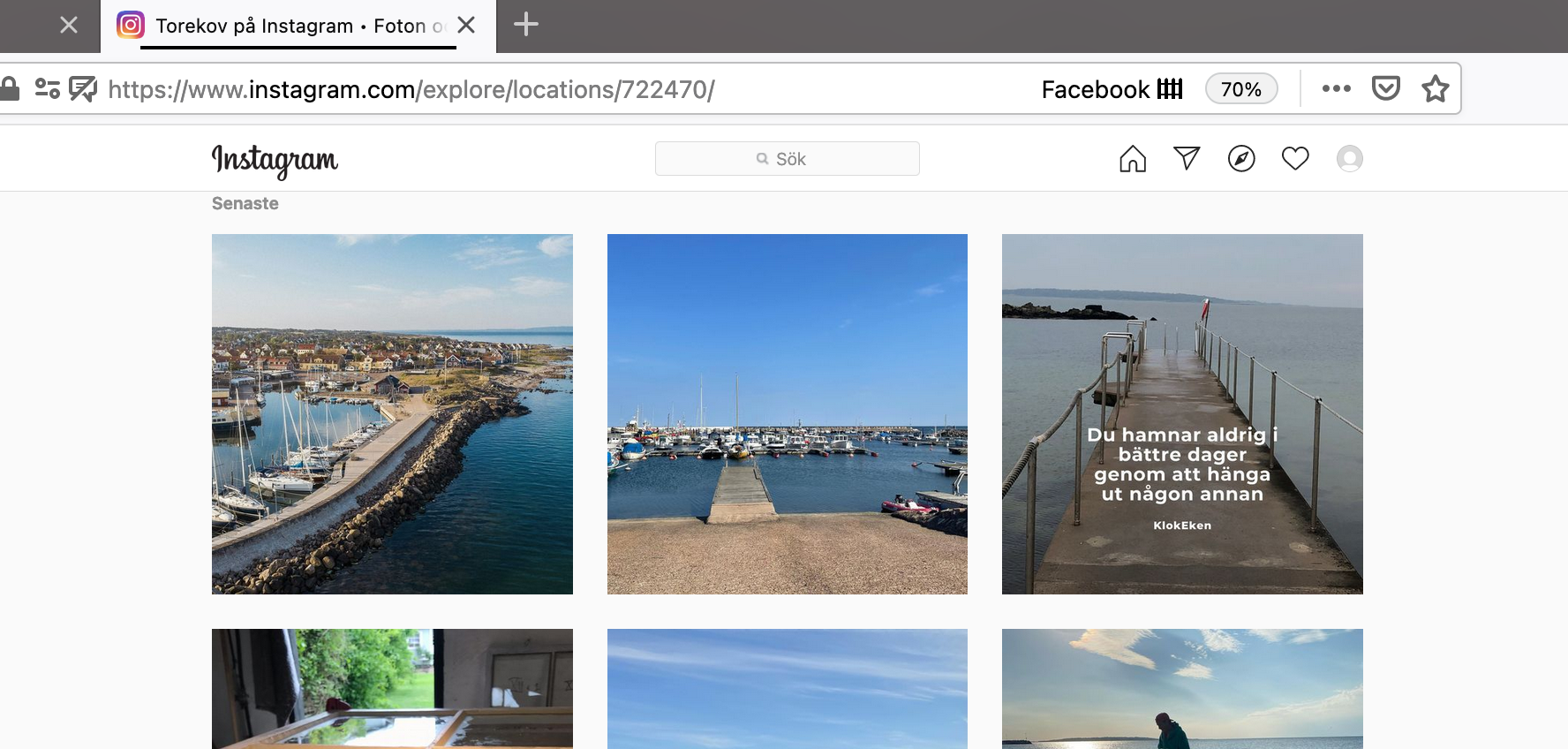
- Instagram som har identifierare för platser WD --> ve kan se biklder från badet Property:P4173 Instargram location ID
- Eionet bathingWaterIdentifier Property:P9616 som är term hos Eionet dataelements/99263 och visas upp på deras karta men även används av svenska Hav och deras karta
Fattigmans länkad data med browser plug in
-
video hur man kan hoppa mellan alla ovanstående siter pga att data i Wikidata används UTAN att saker finns kopplade/kurerade på den webplats vi är
-
plug-in Entity Explosion
-
Exempel recension Morgonbryggan
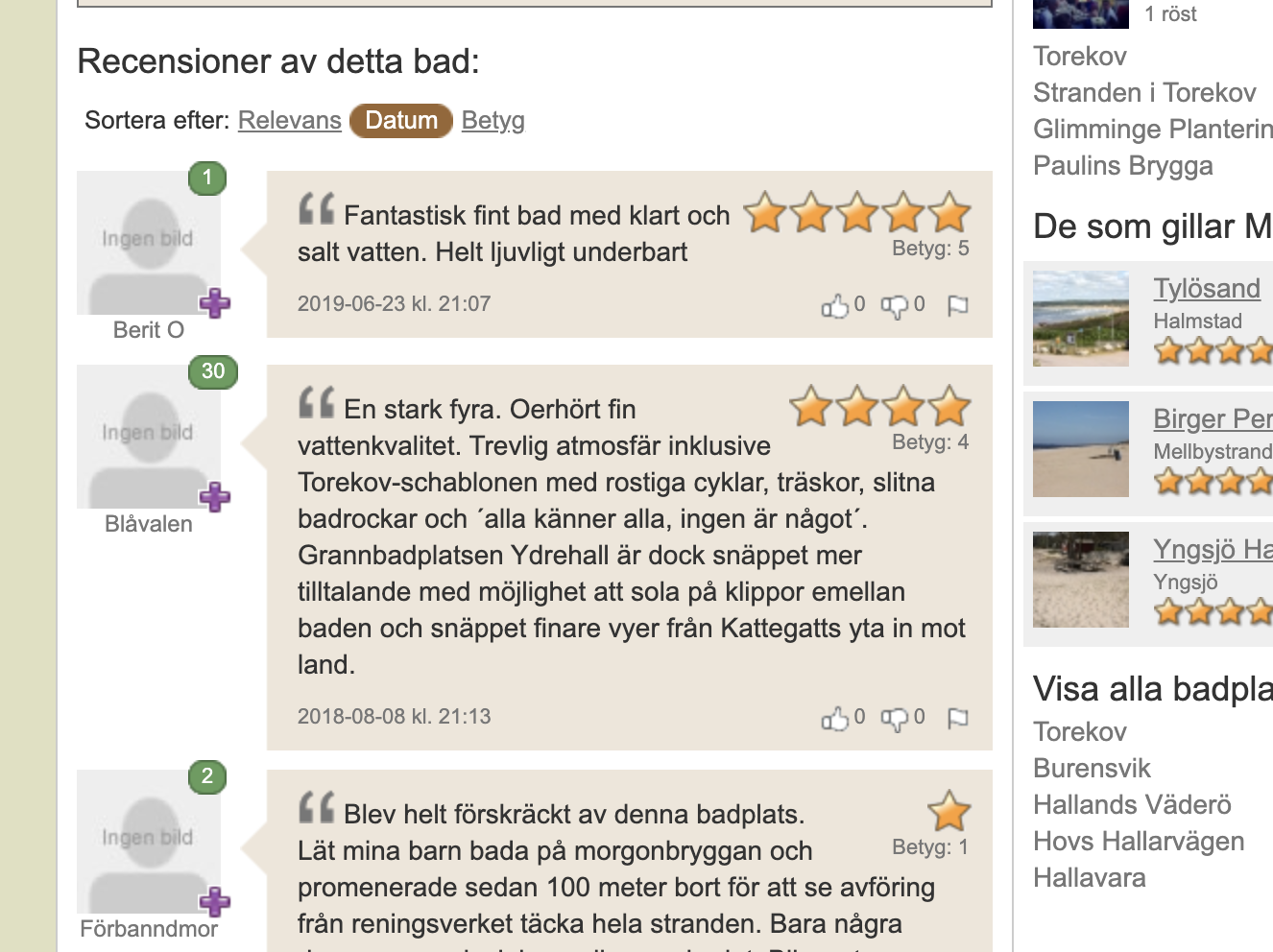
- plug-in Entity Explosion
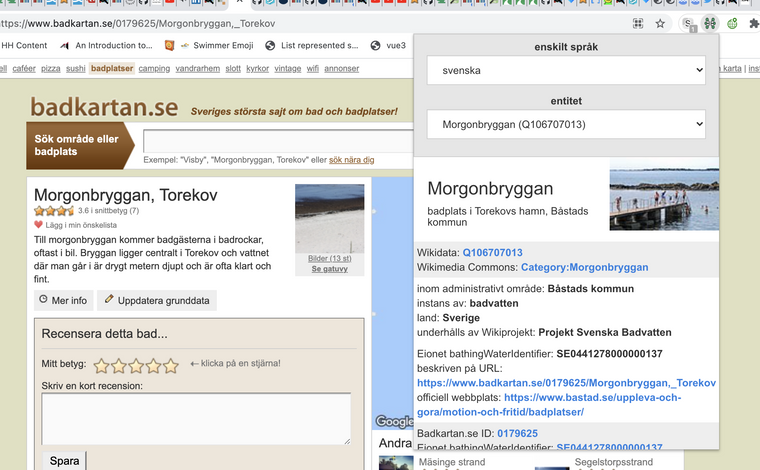
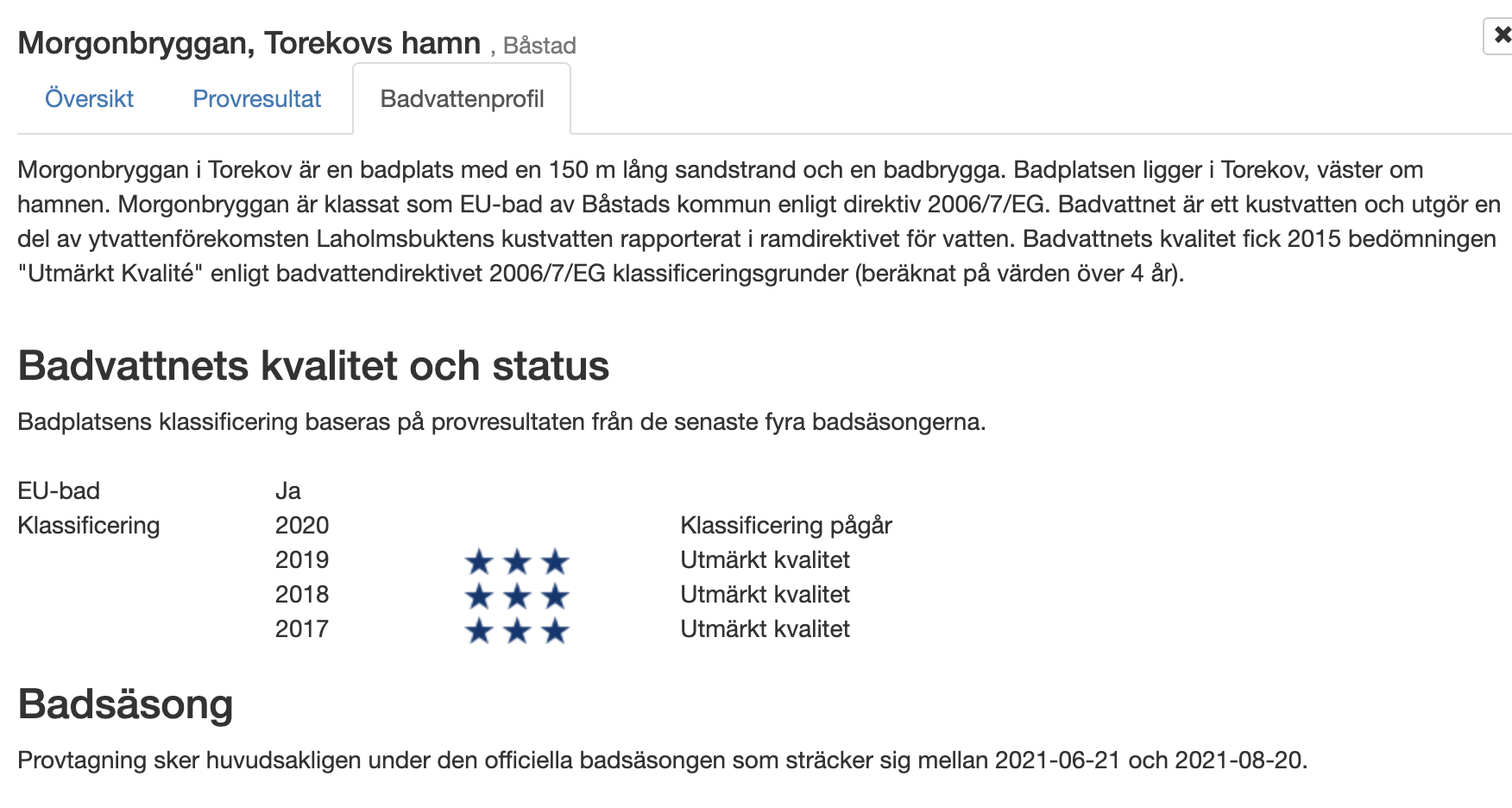
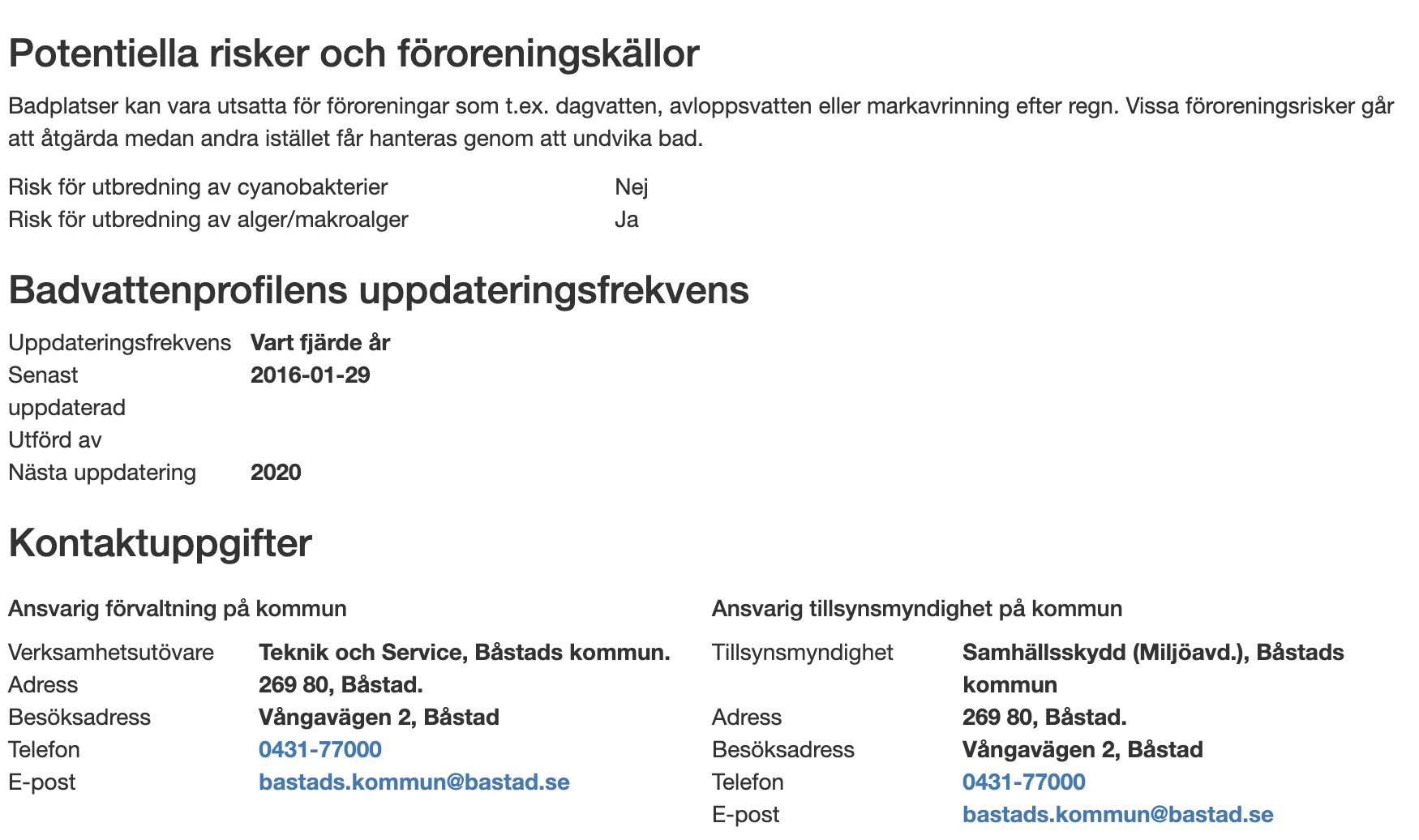
- Hav om Morgonbryggan
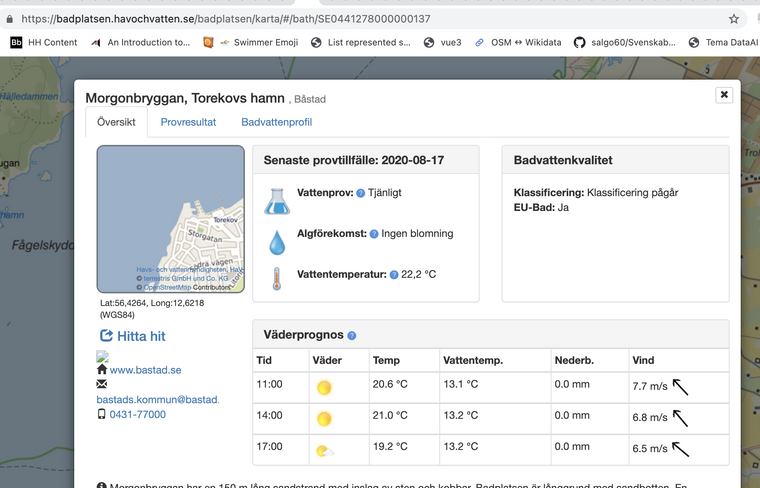
- senaste provtagning
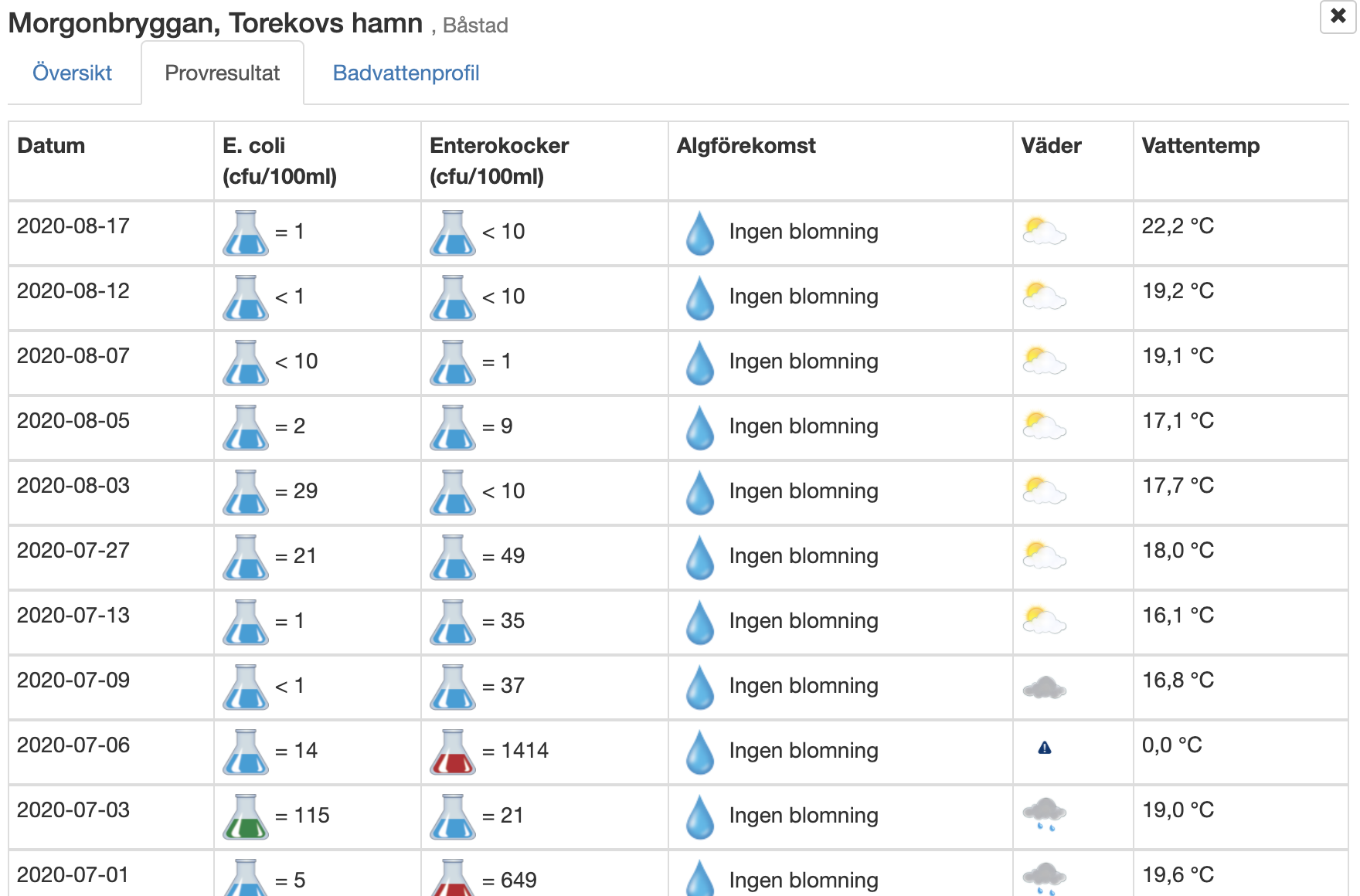
- Badvattensprofil med kontaktpersoner och tillsyn
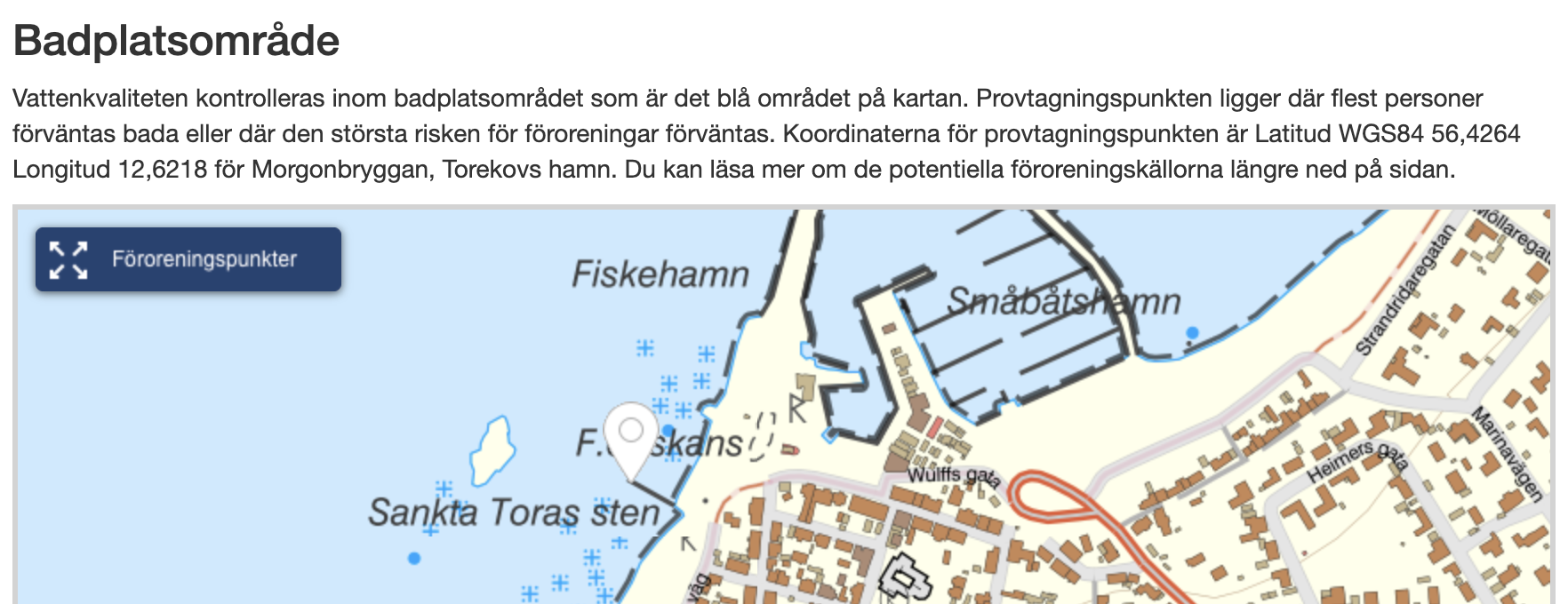
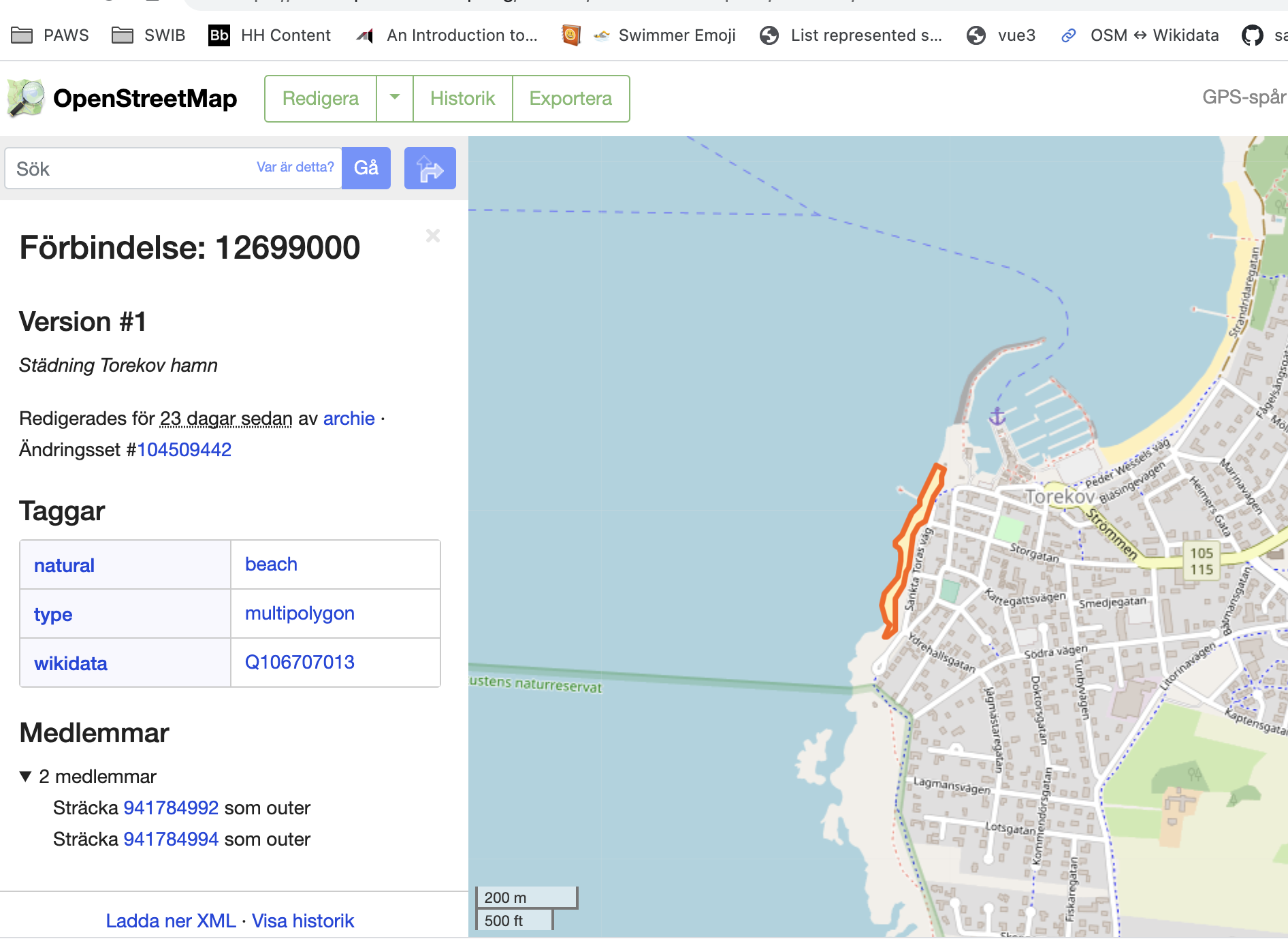
- Hur det ser ut på Open StreetMap relation/12699000 som är kopplad till Wikidata Q106707013
- Instagram plats locations/722470 = Torekov