Community på Sveriges dataportal
Namnstandard vad specar heter och hur de refereras, backlog
-
-
Input DIGG backlog borde vi inte ha DOI nummer för specar så man kan referera dom tydligare. I exemplet så är inte ens specifikationens namn i dataportal och i refererad spec lika... versions nummer finns i URL:en inte i dokumentet tydligt ?!?!?! Som sagt snyggare att ha databas driven lösning se change history EntitySchema:E280 med diff mellan versioner och stöd för språk sv, en, de
-
Input DIGG backlog i metadata på dataportal.se borde länk backlog finnas för specar. I detta fall verkar det i dokumentet finnas en länk till gitlab lankadedata spec/utegym/-/issues
-
-
@salgo60-ej-aktiv DOI var ett riktigt intressant förslag. Jag/AF har mest tänkt UUID för identifierare. Tror du det finns något bra exempel på ett API som använder DOI?
-
@salgo60-ej-aktiv Med öppen backlog menar du typ såhär?https://gitlab.com/groups/arbetsformedlingen/taxonomy-dev/-/issues
-
@jonass Forskarvärlden använder DOI för publikationer och ORCID för personer (det var det jag gnällde på här att man inte förstod det) men det finns även för dataset. Wikidata har Scholia som byggs som ett lager över Wikidata... för att koppla ihop personer ämnen, författar grafer etc allt bygger på att datat har "samma som"
OT @Dennis_Priskorn som är snabb och lite galen har om jag nu fattat rätt satt upp Kubernetes instanser på Wikimedias servrar som kör hans nya verktyg dpriskorn/ItemSubjector och lägger på ämnen från Wikidatas kunskapsgraf på 1 miljon forskningsrapporter per vecka.... tror på denna lista är det Jsamwrites och So9q som ofta ligger högst och trycker in ändringar
")
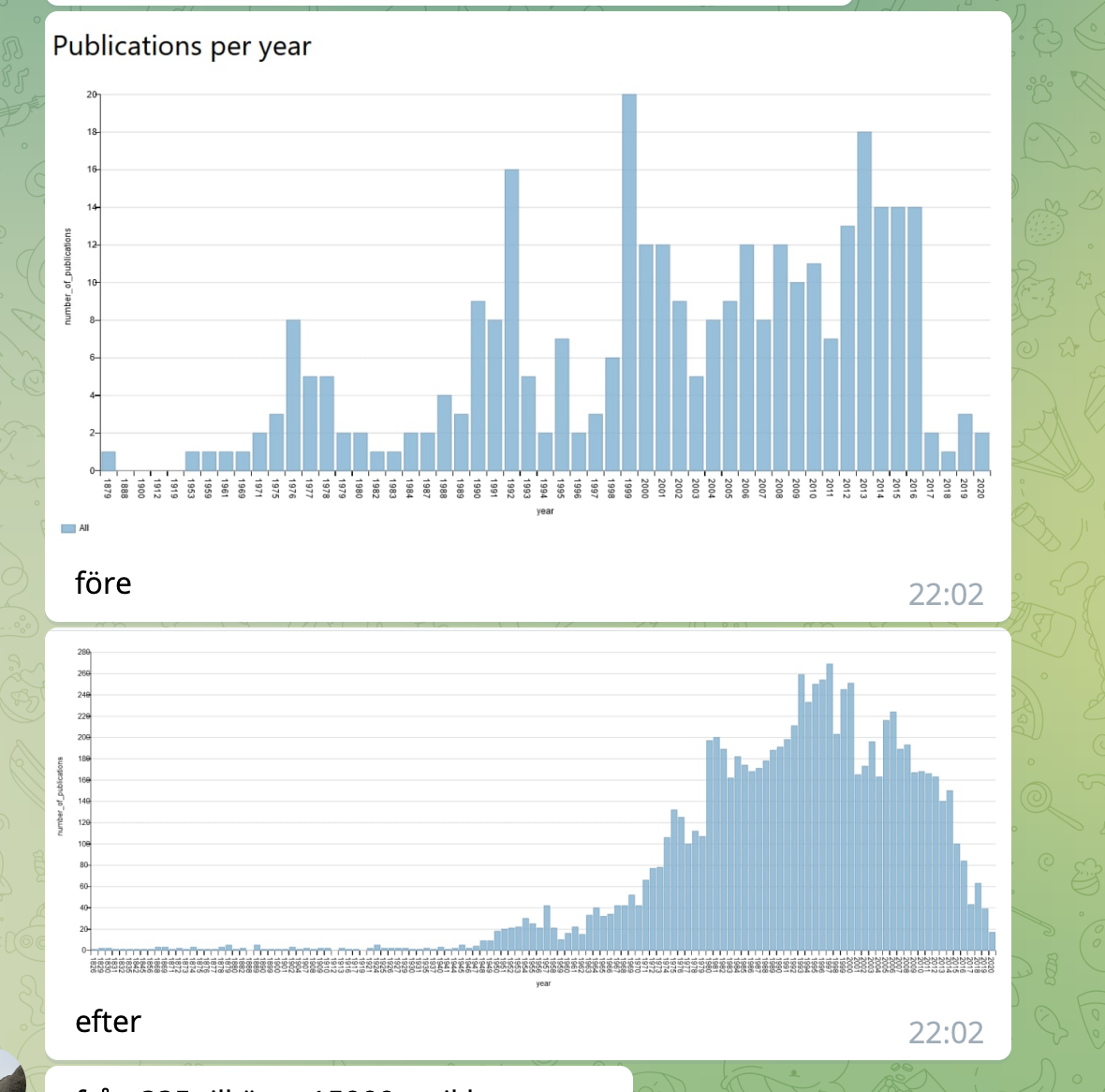
Nedan hur antal artiklar med ämnesord morfin blir fler.... bäst vore tror jag att datat kurerades vid källan men nu har vi inte en perfekt värld så då behövs krigare som herr Dennis
Kolla på Kaggle så sätter dom DOI numera på om du laddar upp ett dataset.
Harvard Dataverse kör det för sina dataset
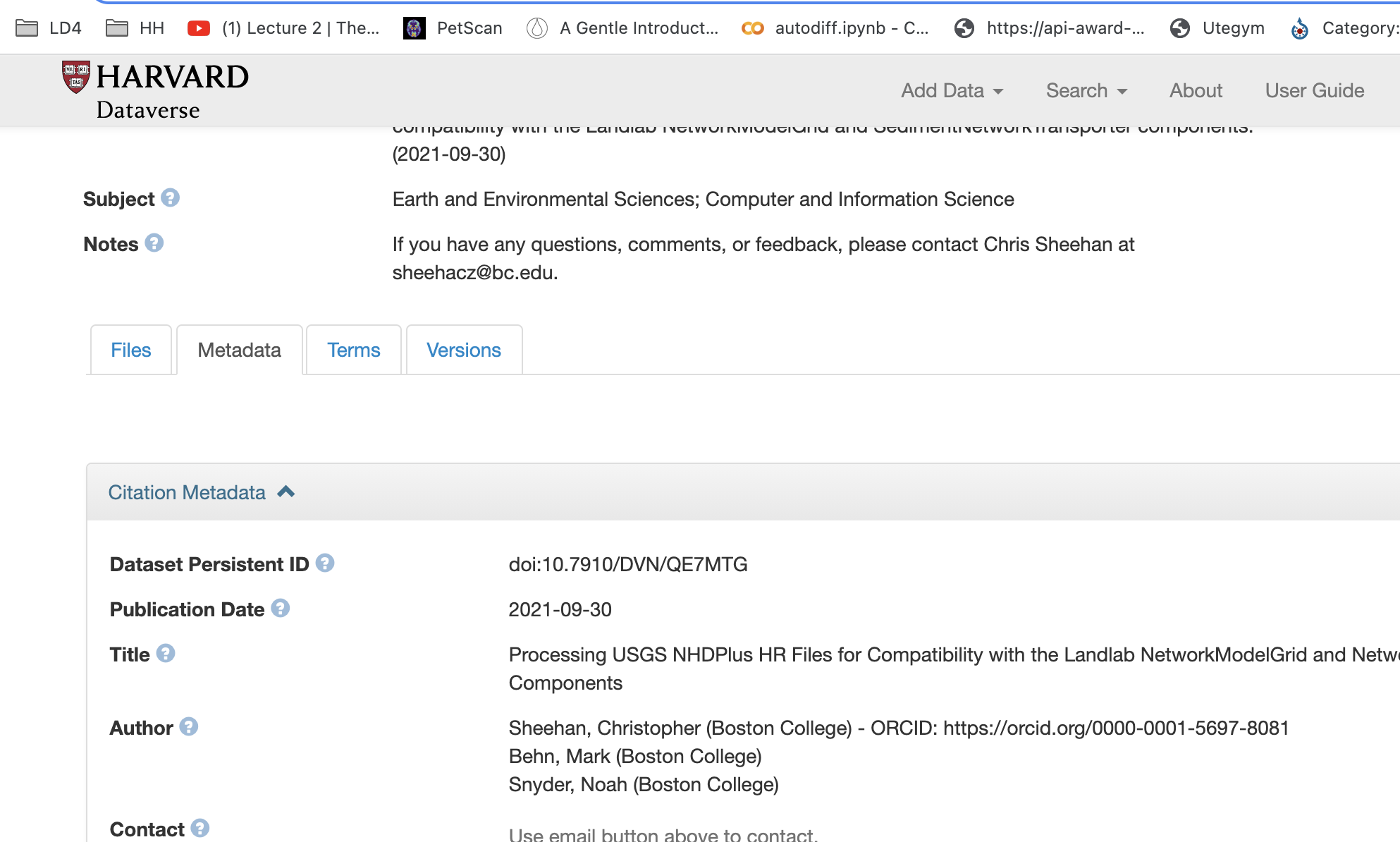
- GITHUB pushar det "Making Your Code Citable"

DIGG Anna pratade förut om att Öppna data är en lagsport. Att vi nu ligger enl. OECD fortfarande typ sist och har folk som inte ens ser brister hur vi jobbar med data och specar proffsigt eller varför man skall ha kunskapsgrafer tror jag är en early warning flag.... att vi har fel kompetenser...

För att parafrasera Louis Armstrong "Om man måste fråga varför man skall ha kunskapsgrafer och persistenta identifierare så kommer du aldrig att förstå svaret " dvs. jag tycker mig se nu är att varför inget händer är att vi har fel folk i laget som inte har rätt bakgrund och att vi inte har lärande organisationer ....Med hopp om att jag har fel
-
@jonass japp jag tror ni skall visa upp er mer och även dela hur tufft jag gissar det är att skapa datadrivna matchningstjänster (vilket jag tror ni gör).
Gissar att en organisation som LinkedIn aldrig behöver förklara vad datadriven arbetsmarknad är utan där tänker man hur påverkar detta kunskapsgrafen eller dom ML modeller vi har....
-
@salgo60-ej-aktiv tack för info, mycket intressant. Tror vi/af behöver hitta smarta sätt att nyckla/översätta kompetenser/yrken mot fler domäner än de vi traditionellt arbetar emot SSYK/ISCO/etc. Säg till om du har tid för möte någon dag, för att diskutera mappningar mot wikidata.
-
@jonass jag har alltid tid men inser mer och mer min inkompetens på yrken skills det är bara att ringa. Kanske vi kan få med @Dennis_Priskorn det är en yngre hjärna med bredare bandbredd än min....
annan variant är att hänga på Wikidata snack vi har just nu Söndagar 14:00 https://meet.jit.si/Wikidata-SV
-
@salgo60-ej-aktiv Hej, det här tycker jag var ett intressant inlägg.
Eftersom jag råkar vara jazzpianist tycker jag såklart att det är kul att se en bild på Louis Armstrong. Jag funderar också lite på kopplingen till morfin och tar omvägen över Charlie Parker och muskotnöt i apelsinjuice. Sedan talas det om både krigare och lagsport i positiva termer, vilket jag har svårt att få ihop. Jag funderar på vem som krigar och mot vem. Sedan kommer en del om kunskapsgrafer och akademiska referenser, vilket jag också är intresserad av.
Jag ser att det finns massor för mig att lära mig i det här inlägget, men jag har svårt att få fatt i andemeningen av det. Det är långt, det innehåller väldigt mycket text om många vitt skilda ämnen.
Skulle du kunna förklara lite kortare och i lite enklare termer vad det vill säga om just öppna data, öppna APIer och innovation kopplat till det? Så det är lättare att ta till sig för den som kanske är ny och behöver lära sig? -
@nina_ vi kan dela skärms så får du höra min bild eller skicka frågor tankar på Telegram salgo60 av kunskapsgrafer.... jag vet inte var du befinner dig på spektrat att se data drivna möjligheter och jag säger inte att jag har rätt men jag tror att företag som Linked in, Google ser möjligheter vi andra döda inte inser -> video svar på det jag tror du fråga om
- morfin --> är hur @Dennis_Priskorn klassificerar vetenskapliga publikationer i Wikidata men även Riksdagens dokument se video
- I Wikidata finns 27 miljoner med objekt som har DOI ofta är det forskningsrapporter och har man gjort rätt så citerar man en forskningsrapport och använder DOI - se "A Persistent Identifier (PID) policy for the European Open Science Cloud"

-
krigare = Dennis hade det varit en lagsport så hade vi lagt en "todo" i Riksdagens Öppna datas inkorg och dom hade kopplat vilka motioner som har med FN:s klimatmål, partiprogram etc....
** idag har Riksdagen ingen publik backlog utan det skall skickas email.....
** jag träffade Riksdagen 2019 och trodde dom att dom kunde kategorisera sina motioner med EUs kategorierna men det verkar ha dött ut
** att krigaren sätter ämnesord som Morfin kan vara bra men skadar inte att den som skriver motionen även gör det jobbet, plus kopplar det till klimatmål, partiprogram etc,.....
*** se "LinkedSDGs is an innovative platform designed to support the 2030 Agenda implementation" där man använder länkade data - vet ej status på detta initiativ -
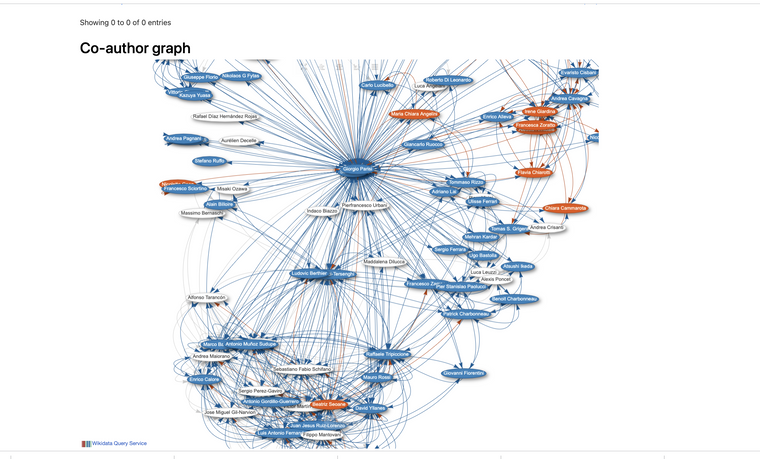
DOI - vetenskapliga publikationer publiceras på massa ställen som Öppna data för att förstå att vi pratar om samma rapport har man DOI dvs. som personnummer.... sedan skrivs en artikel av en person som identifieras med ORCID --> vi kan skapa grafer vilka skriver artiklar inom området Morfin, vem är mest citerad av dessa publikationer..... Wikidata är långt från fulltäckande men exempel vilka publikationer som skrivits av Nobelpristagare i fysik, hur årets pristagare = Q1235614 = orcid.org/0000-0001-6500-5222 = Giorgio Parisi har publicerat rapporter vi kunnat kopplat ihop med hans medförfattare Graf
@Ainali styrde upp så att Riksdagens dokument trycktes in WIkidata exempel vad Anna Lind motionerat om se även video
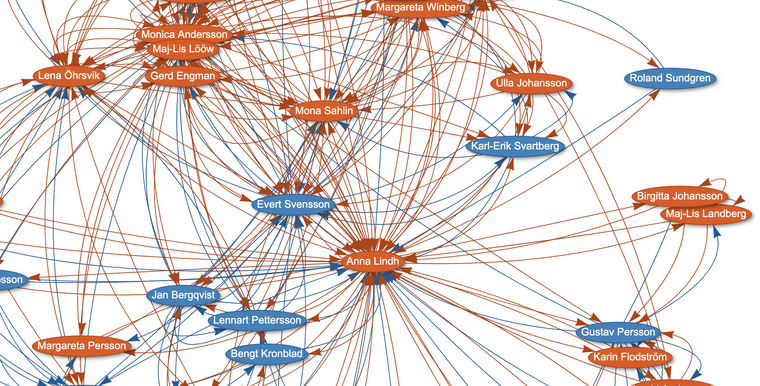
- morfin --> är hur @Dennis_Priskorn klassificerar vetenskapliga publikationer i Wikidata men även Riksdagens dokument se video
-
@salgo60-ej-aktiv Tack! Vi är ett tvärfunktionellt team och det är inte jag som är bäst på öppna data. Jag är med för det jag kan om agila och lättviktiga arbetssätt och för att jag har jobbat mycket med livscykelhantering, bl a. Vi lär oss av varandra. Jag tror att andra personer i teamet just nu tittar på en del av dina frågor.
-
@nina_ det är galna utmaningar känner jag.... när ett projekt som NSÖD inte hittar rätt med koordinater efter 2 år hur skall då en kommun göra rätt... med 158 kommuner som inte ens har en /PSI sida
- det kan vara så illa att det IKEA gör är det enda rätta att lyfta in nya kompetenser är ett måste.... om en budget på 16 miljoner med projektledning från ri.se och Vinnova blir ett magplask borde en haverirapport skapas och återkopplas
- varför reagerar inga "experter" på 2 år och var finns DIGG?? Vet att personer från DIGG suttit med vid NSÖD specandet...
- min erfarenhet skall man skapa kunskapsgrafer så är det 1000 ggr mer komplext än koordinater och skall man göra det ihop med andra så kan man inte ha dagens SILOS utan backlogs...
Finns tyvärr många liknande misslyckanden.... Kungliga Biblioteket startade 2012 med LIBRIS XL och inser själva att det inte blir bra, dom har stängt ned sitt diskussionsforum men där var folk enormt upprörda och det skrivs artiklar att uppdraget missköts.....
-
@salgo60-ej-aktiv sa i Namnstandard vad specar heter och hur de refereras, backlog:
-
Input DIGG backlog borde vi inte ha DOI nummer för specar så man kan referera dom tydligare. I exemplet så är inte ens specifikationens namn i dataportal och i refererad spec lika... versions nummer finns i URL:en inte i dokumentet tydligt ?!?!?! Som sagt snyggare att ha databas driven lösning se change history EntitySchema:E280 med diff mellan versioner och stöd för språk sv, en, de
-
Input DIGG backlog i metadata på dataportal.se borde länk backlog finnas för specar. I detta fall verkar det i dokumentet finnas en länk till gitlab lankadedata spec/utegym/-/issues
Finns det nått som hindrar DIGG att börja göra specar direkt i https://sweopendata.wiki.opencura.com/wiki/Main_Page? Det verkar ligga till högerfoten att bara sätta igång. @salgo60-ej-aktiv om DIGG vill ta över förvaltningen av den Wikibase vill du lämna ifrån den då?
-
-
En före detta användarereplied to En före detta användare on Senaste redigerad av En före detta användare
@salgo60-ej-aktiv sa i Namnstandard vad specar heter och hur de refereras, backlog:
morfin
Här kommer länken https://scholia.toolforge.org/chemical/Q81225
Innan jag gjorde matchningen fanns bara några hundra artiklar kopplade. Nu finns över 16.000 artiklar att hitta som använder "morphine" i engelska titeln.
Kopplingen tog ca. 1 min i människotid att sätta igång och några timmars datortid att utföra. Verktyget jag använder har jag skrivit själv, se koden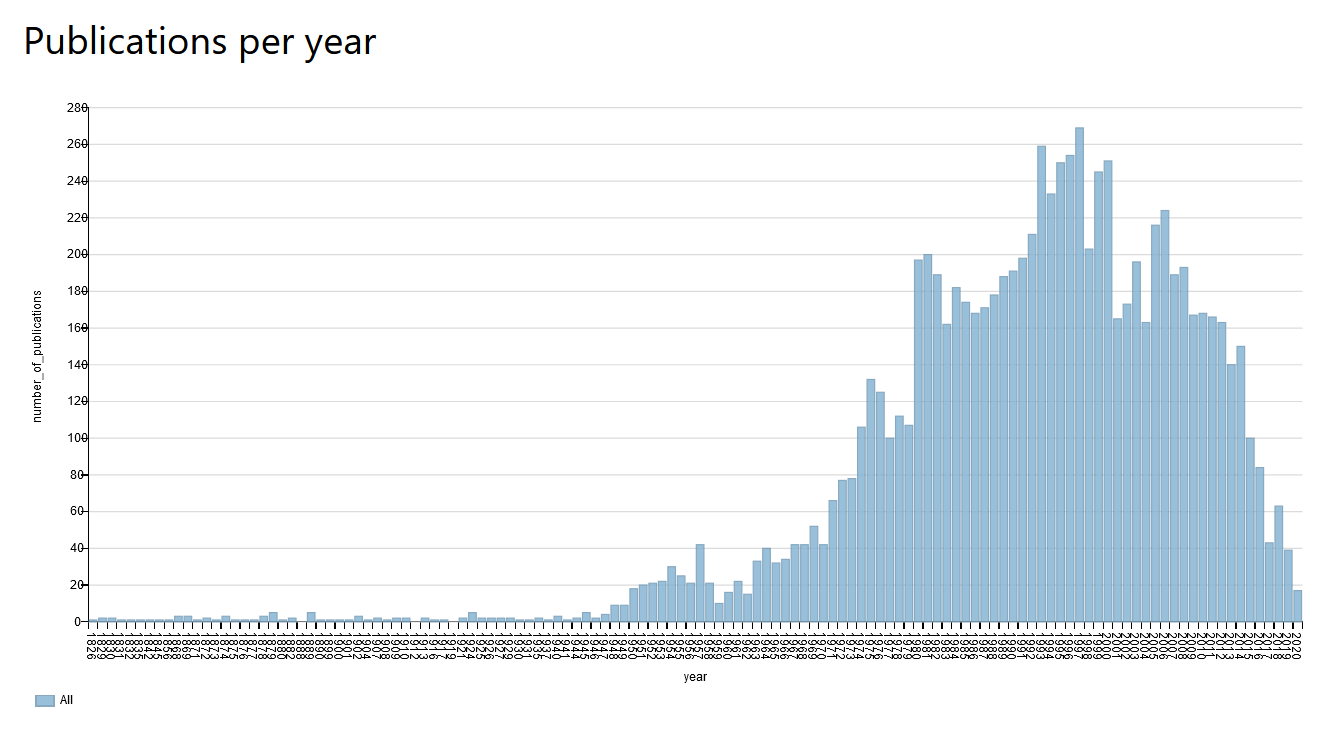
Det syns tydligt i bilden nedan att intresset för morfin i forskningen har toppat 1997 och sedan svalnat av ganska kraftigt. Detta kan bero på att vi tyvärr saknar många nyare artiklar i Wikidata, eller på att morfin redan är välutforskat och forskningen kanske numera fokuserar på andra ämnen vi känner mindre väl.Jag har försökt åtgärda bristen på artiklar i WD med andra självskrivna verktyg, men pga. av infrastrukturproblem har jag nekats att importera flera artiklar med bot i dagsläget.
-
@dennis_priskorn tänk om vi strukturerade öppna data med koppling till en kunskapsgraf.... och kunde navigera lika snyggt..
Verkar som ett företag Google hunnit före enl. Google AI blog: Building Google Dataset Search and Fostering an Open Data Ecosystem / video

-
 M Maria_Dalhage moved this topic from Tipsa och fråga on
M Maria_Dalhage moved this topic from Tipsa och fråga on