Community på Sveriges dataportal
Communityskapande i Dataportalen - fler funktioner eller inte?
-
@Maria-Söderlind det är en enormt lång resa och inte enkel.... #linkeddataneedslinkedpeople är min tro
Bara detta Europeana projekt jag länkade till startade 2010 och har säkert kostat oss skattebetalare 100 tals miljoner Euro och ändå blir det fel, tar 2 år att få en felticket som säger att dom har viktigare saker..
") .... trots att skicka iväg konstnär x så att mottagande system förstår är enormt enkelt.... men ändå blir resultatet massa bilder utan bra metadata....
.... trots att skicka iväg konstnär x så att mottagande system förstår är enormt enkelt.... men ändå blir resultatet massa bilder utan bra metadata....Jag gillar dock inte att vi får ett landskap där DIGG publicerar sina saker på Linked in/ Facebook och sedan sitter Facebook och tom "lurar" av apoteken vilka personer på Facebook som köper vissa läkemedel.... gissar DIGG nu kan köpa vilka som läser deras meddelande och som äter Viagra, har problem med frugan som käkar lugnade och emailar andra karlar.... eller annat galet... gissar att många har på sin GPS spårning så vi lämnar även spår hur ofta vi befinner oss på obskyra platser...
Digitalisering skall fram men användas på rätt sätt... typ mina utegym eller offentlig konst
och inte av kommersiella aktörer med låg moral.... andra sidan av problemet är att Apoteken/DIGG måste fundera över vilket ansvar dom har att hoppa i säng med "vem som helst" 
-
En före detta användarereplied to En före detta användare on Senaste redigerad av En före detta användare
Stockholm rankas nu som världens mest hållbara stad !!!
 artikel 2022 Sustainable Cities Index
artikel 2022 Sustainable Cities Index(ingen nyhet för oss som kan vår Pugh)
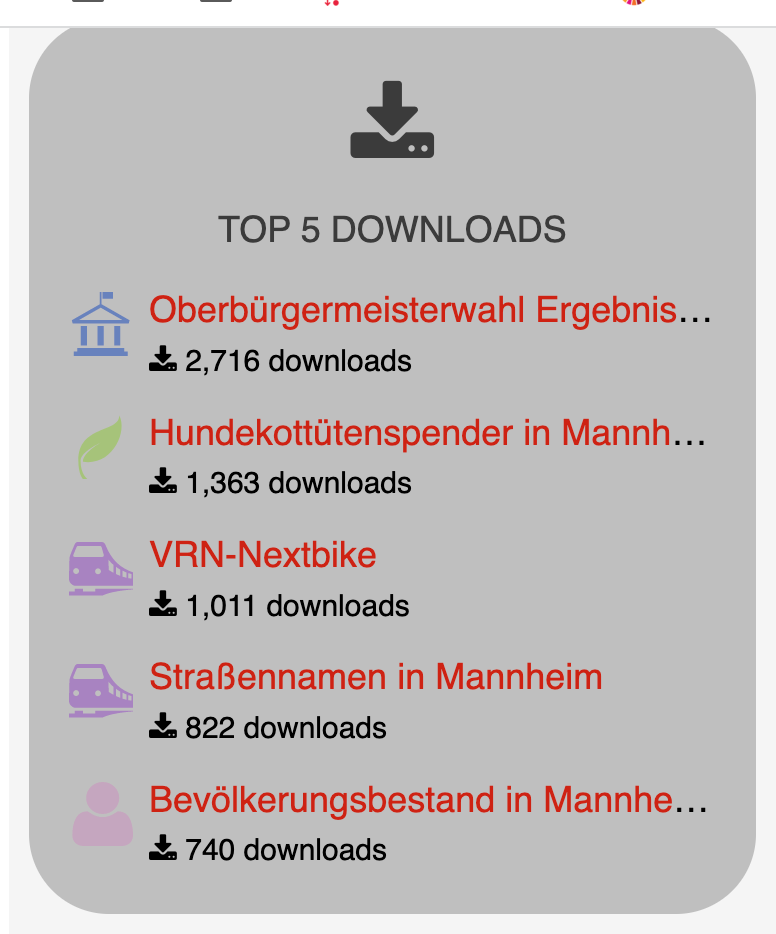
Kolla hur Stockolms nu kopplar kommuninvånares feedback till plats på karta se och lär

 många kategeorier, synlig statistik om bra eller dåligt....
många kategeorier, synlig statistik om bra eller dåligt....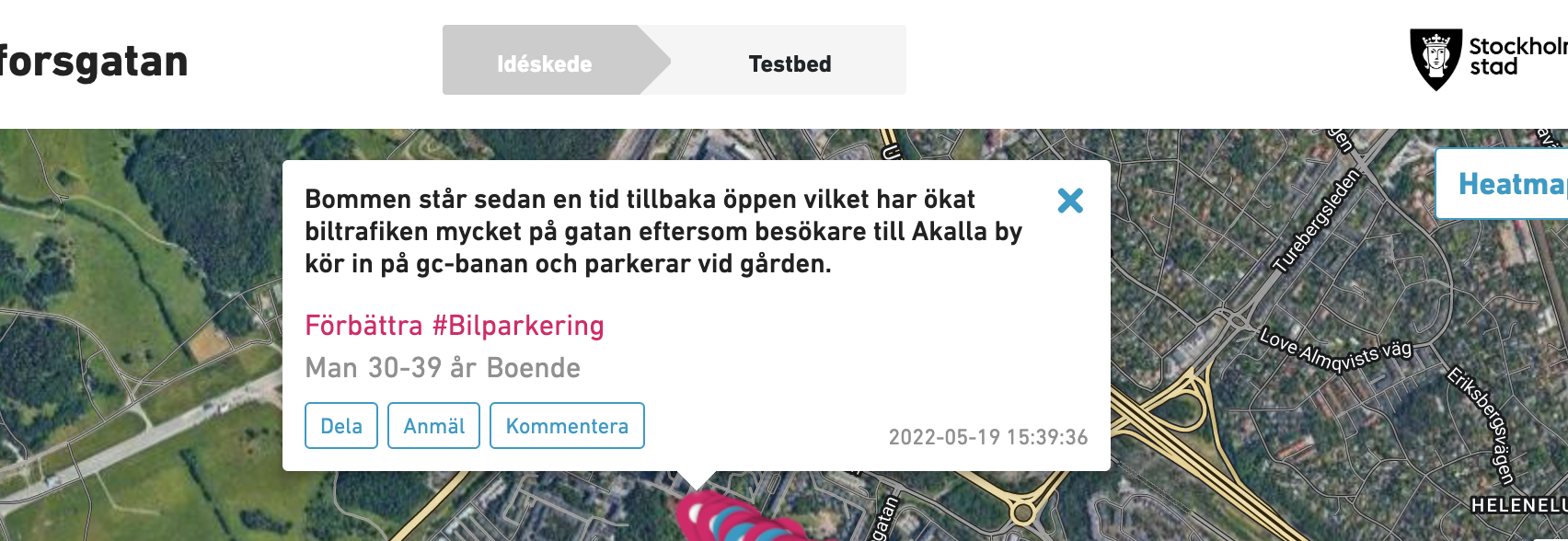
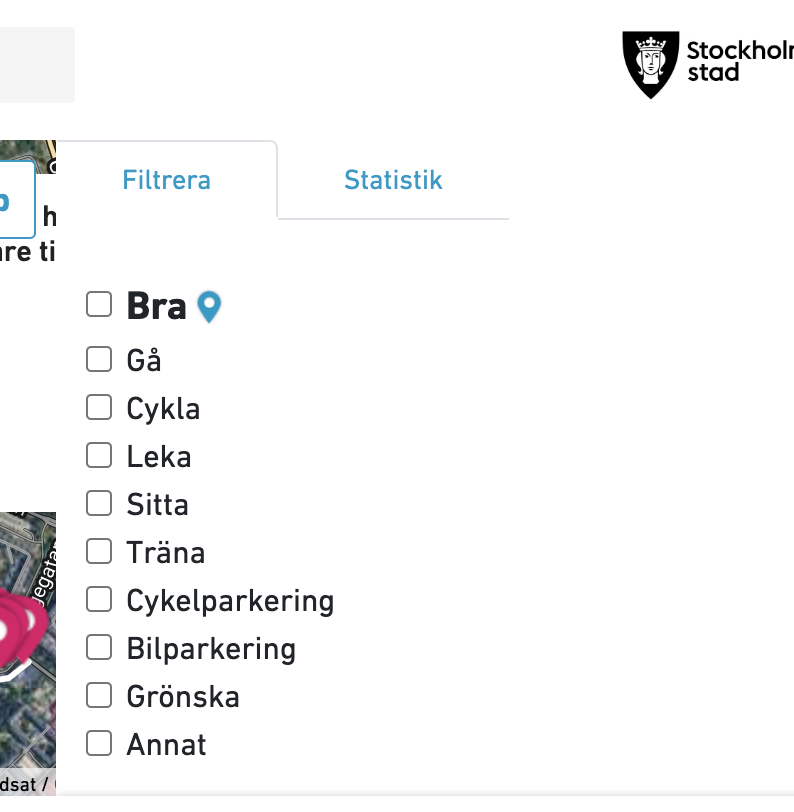
Massa kategorier att filtrera på
Statistik om det är "bra rop" eller feedback förbättringar gissar jag
- borde vara samma för alla dataset i portalen.... gärna fler parametrar, finns helpdesk, helpdesknummer, finns på GITHUB, teknisk mognad ..... nu har vi torrsimmat sedan 2010 med Öppna data dags att leverera
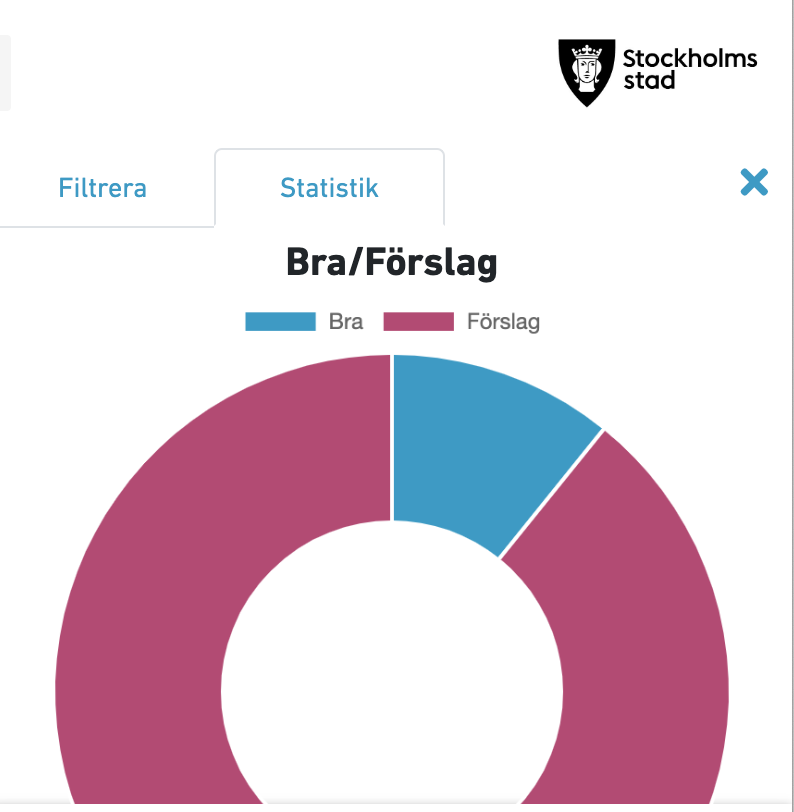
- borde vara samma för alla dataset i portalen.... gärna fler parametrar, finns helpdesk, helpdesknummer, finns på GITHUB, teknisk mognad ..... nu har vi torrsimmat sedan 2010 med Öppna data dags att leverera
-
-
@Stefan-Wallin Större delen denna konversation och mycket av det som Magnus pratar om handlar om hur man publicerar öppna data och hur specifikationerna bör utformas. Det är självklart bra att det finns tankar kring detta men är det inte så att:
DIGG publicerar ingen öppen data. De återpublicerar/skördar eller länkar till data som finns på andra ställen. Hur dessa datamängder är uppbyggda har DIGG inte mycket med att göra. De kanske borde, men i sådana fall som en röst när det kommer till framtagning av specifikationer.
De av er som har synpunkter på hur data publicerar bör snarare ta kontakt med respektive publicist. Det är dom som kan göra något åt det. DIGG har små möjligheter i dagsläget att göra detta. Ett steg i underlätta för er konsumenter att komma med önskemål och förslag framöver skulle kunna vara det som Maria i sitt ursprungsinlägg pratar om. Dvs att ge enklare möjlighet att prata brett om specifika publicerade datamängder.
Idag finns dock fortfarande möjlighet för er att prata med respektive publicist. Och får ni inte bra respons där så måste jag nog upprepa att DIGG inte i dagsläget kan trycka på vad gäller specifikationer och standarder. Det arbetet pågår på respektive publicist hemmaarena, Nationella Dataverkstaden och i andra forum som för mig tyvärr är okända.
-
@jonas-nordqvist sa i Communityskapande i Dataportalen - fler funktioner eller inte?:
DIGG publicerar ingen öppen data. De återpublicerar/skördar eller länkar till data som finns på andra ställen. Hur dessa datamängder är uppbyggda har DIGG inte mycket med att göra. De kanske borde, men i sådana fall som en röst när det kommer till framtagning av specifikationer.
Det stämmer i stort det du säger, förutom att DIGG också är en dataproducent. Vi publicerar fyra datamängder idag. Vi borde säkert publicera fler och det går säkert att hitta fel i våra datamängder också, men vi resonerar som @Maria-Söderlind - det perfekta är det godas fiende.
-
Som en följdtanke av detta, kan man ens tänka sig en myndighet som inte borde producera någon öppen data alls? Även om andra myndigheter har ansvar att publicera metadata om myndigheten så har jag svårt att tänka mig att det inte finns något som skulle kunna göras transparent tillgängligt i ett lättkonsumerat format relaterat till kärnverksamheten.
-
@Jonas-Nordqvist jag tror du missförstår mig och Magnus. Visst har vi åsikter om datakällorna som publiceras på dataportalen, men ämnet här är ju att diskutera ett förslag till communityskapande funktioner i dataportalen. Våra invändningar i stort är att istället för att bygga kommentarer frikopplat från datamängden bör man fundera på hur livscykeln runt de publicerade datamängderna fungerar och hur man jackar in communityt där om man faktiskt är seriös på att uppnå en fungerande engagerade community.
Jag(och förmodligen även Magnus) menar att dataportalen borde vara en datamängd i sig som kan dra nytta av att visa vägen för hur OpenSourcekulturen kan anammas i datapublikation.
Tänker direkt tillbaka på en annan funktion man bad om återkoppling på (filtrering och gruppering av data-källor där det från DIGG's önskan vara att begränsa till något smalt och unikt istället för brett och sammanlänkat)
I det fallet man är seriös på målet fungerande community snarare än på målet bygga en kommentarsfunktion, så kanske man ska fråga sig vad det är för interaktioner communityt är intresserad av att bidra med.
För mig är det viktiga i publicerad grunddata:
- att den håller hög kvalitet.
- att varje enskilt dataobjekt går att länka till och från som "samma-som"
- att existerande fel pekas ut tydligt
- att processen runt datan går att lita på
- att datamängderna går att hitta
För att uppnå detta behövs:
- att varje objekt i datan går att referera till otvetydigt med korrekta persistenta identifierare
- att felrättningar kan skötas transparent så att datan går att lita på & processen för att skicka in rättningar blir tydlig
- att det går att berika datamängderna med metadata från communityt så att fler kan hitta dem.
Vart det tydligt eller oklart?