Community på Sveriges dataportal
Textdata och delning av statliga utredningar för maskinell analys
-
Den 26/11 sker en halvdagskonferens som lyfter behovet av ökad databeredskap för texter/utredningar i staten.
Konferensen ordnas av ESV tillsammans med KB och Rise. Se https://www.esv.se/utbildningar-och-seminarier/seminarier-och-konferenser/datalabbet-resultaten-i-staten/Känner någon förresten till några liknande arbete kring textanalys som görs ?
-
Ungefär samma tema där dagens PDF fixering skapar hinder twitter
Datastory har nu tvättat myndighetsdata publicerade i PDF:er och skapat "Sök i regeringens diarium"

- mer från Datastory
-
J jonor referenced this topic on
-
@jonor tror det kan komma i efterhand men det var om du frågar mig helt fel nivå och väldigt visionslöst....
Min sammanfattning: Dagens myndigheter sitter med PDF:er som är layoutorienterade och då sitter man och pratar i flera timmar om att det inte är bra
Så myndighetsvisionen är presentera text som text inte med layout.... känns mer 1985 än 2021... man var till och med inne och snurra på att HTML som också är layoutorienterat skulle vara en väg framåt.... känns som DIGG borde vara ett kompetenscenter som deltar och pekar med rak hand...
dvs. det finns i dessa "gamla organisationer" inga visioner om att skapa kunskapsgrafer, NER och bygga "samma som", eller presentera saker på flera språk... var lite GD:ar med men dom kommer ju ofta från gamla myndigheter så dom har inte sett ljuset i tunneln är min tro....
Positivt trappan från 5stardata.info visades av Naturvårdsverket, Ulrika Domellöf Mattsson men förklarades inte
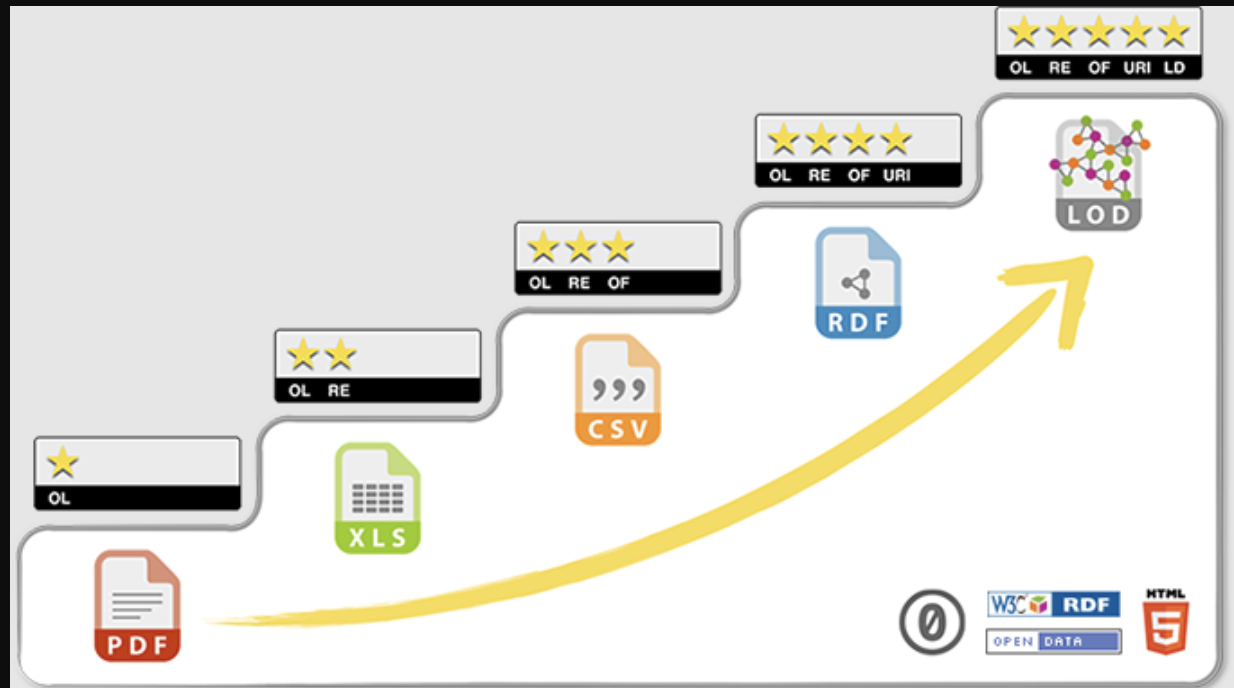
@jonor dyker du upp på Wikidata snack idag så kan vi fundera varför det blir så fel
- saknas tydliga visioner om flerspråkighet
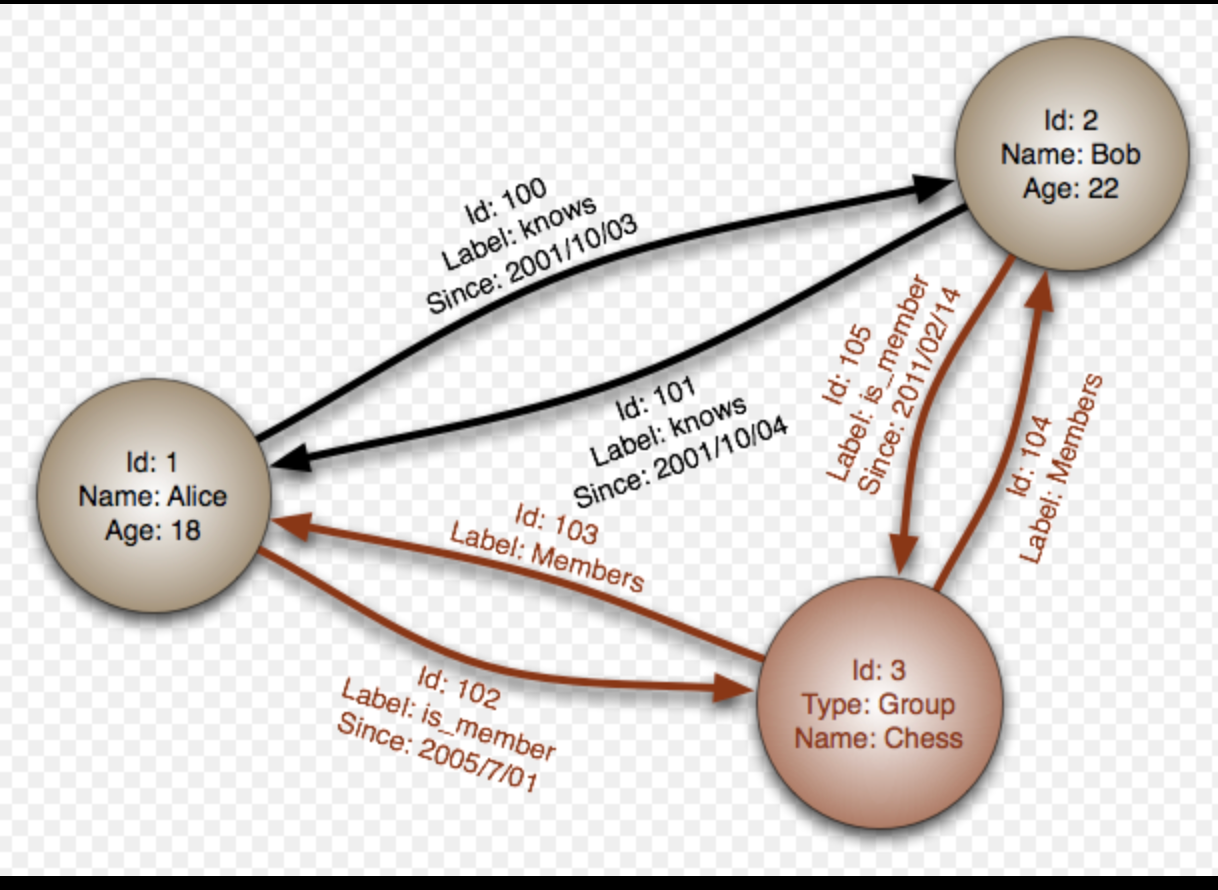
- saknas en insikt att dagens jobba i SILOS med "dumma" textdokument som inte intelligent kopplar ihop sig enl. modell som jag visar ovan med HD:s domar
- saknas visionen att koppla ihop alla Europas utredningar som behandlar samma saker dvs. koppla dataset med kunskapsgrafer till varje rapport som kopplas ihop med övriga Europas utredningar
- kostnaden och ineffektiviteten med att inte skapa digital kunskap måste vara enorm.... tom med Wikidata känns som ett under av effektivitet
Vän av ordning undrar kommer vi fortfarande 2031 sitta med svenska dataset om utegym med specar på svenska och tycka att vi skapar öppna data och tro att sbart är vi bäst i världen på att ta vara på digitaliseringsmöjligheter
Ny bok gratis om KG kgbook.org


-
@salgo60-ej-aktiv sa i Textdata och delning av statliga utredningar för maskinell analys:
Så myndighetsvisionen är presentera text som text inte med layout.... känns mer 1985 än 2021... man var till och med inne och snurra på att HTML som också är layoutorienterat skulle vara en väg framåt.... känns som DIGG borde vara ett kompetenscenter som deltar och pekar med rak hand...
Trots allt, HTML och Markdown är väl textformat som ligger nära till hands för att publicera strukturerade dokument på en betydligt högre nivå än PDF, med stöd för tabelldata, länkar och relationer mellan dokument. Wikidata beskriver ju information om och referenser till resurser, medan resurserna existerar i form av webbsidor som exempelvis artiklar på Wikipedia.
-
@jonor hör gärna av dig 0735152802 så jag förstår hur du tänker
- Wikidata med alla dess fel och brister har en grafdatabas med "samma som" dvs. datat är maskinläsbart och kan förstås.... det finns relationer och externa referenser dvs. man landar på nivå i 5star modellen
- samma har du för bild exemplet nedan men då är det en separat Wikibase installation som kallas "Structured Data on Commons"
- html är för mig (med bakgrund att ha jobbat med dess storebror SGML) djävulens påhitt som inte gör någon glad där texten kanske är enklare att webscrapa men har i princip bara layout struktur dvs. ointelligent
- Wikipedia har en "snygg" länkmodell där syntax [[zzzz]] skapar en relation mellan ett text element och ett annat textelement zzzz dvs. där visas relation mellan ett text element och en artikel MEN du saknar en beskrivning på relationen som i Wikidata kallas Property
- bra visualisering av detta får du om du installerar https://github.com/derenrich/wwwyzzerdd där alla länkar i en WIkitexten visas och kopplingar som även finns i WIkidata med en egenskap markeras gröna
-
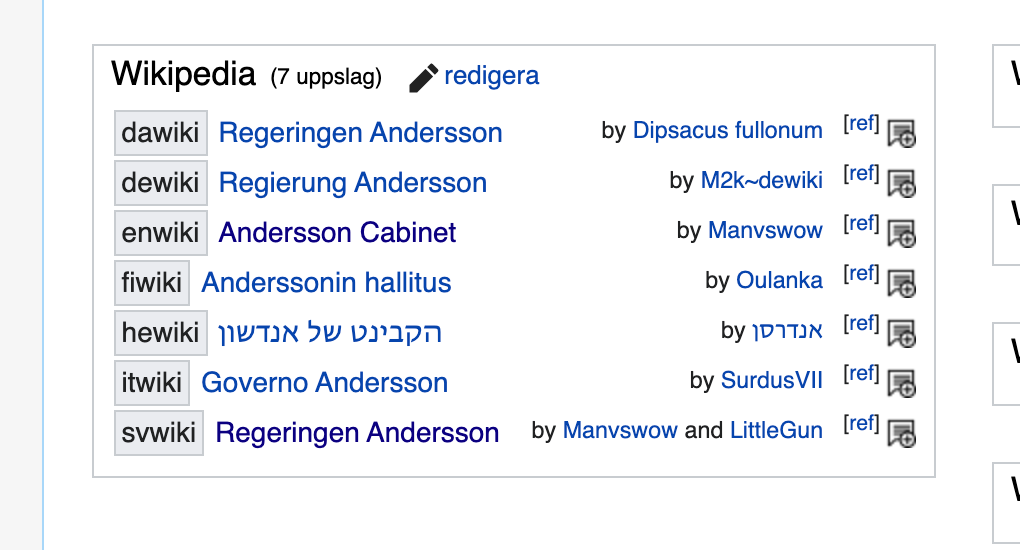
bild från Regeringen Andersson med wwwyzzerdd aktiverad
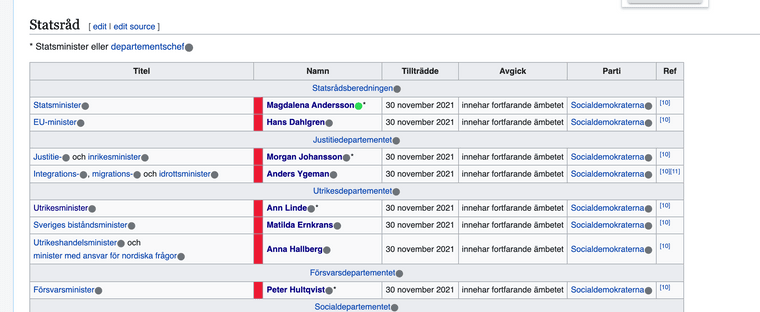
-
Annat exempel med semantisk koppling i bild länk

-
- bra visualisering av detta får du om du installerar https://github.com/derenrich/wwwyzzerdd där alla länkar i en WIkitexten visas och kopplingar som även finns i WIkidata med en egenskap markeras gröna
Hur digitala är Regeringskansliet ?
länk www.regeringen.se pressmeddelanden regeringsskifte-den-30-november-2021
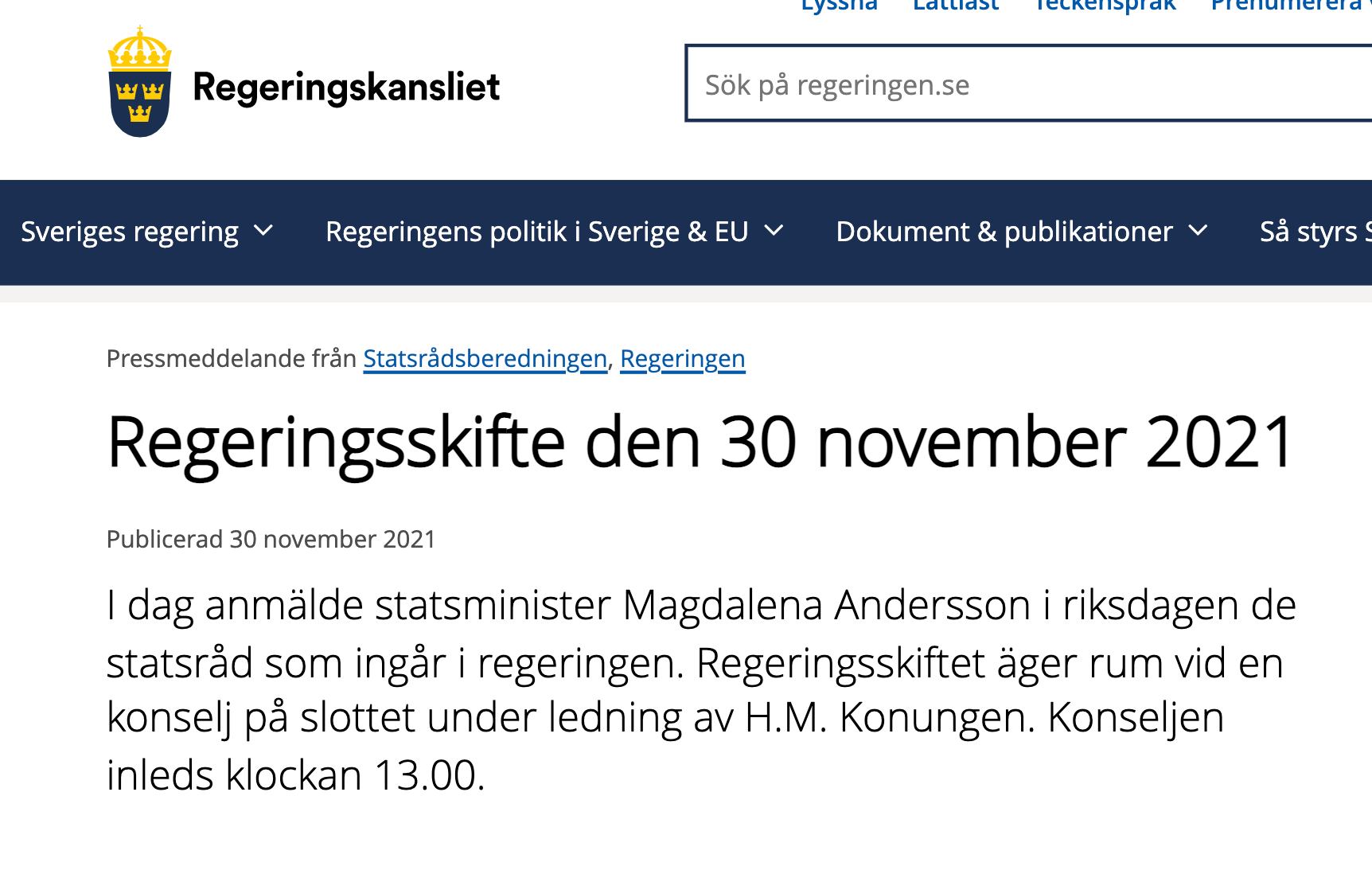


osv....
Här har du alla nya namnen som text dvs.
- saknas samma som
- skall datat webscrapas så är det i princip omöjligt att koppla texten till rätt person för många nya
- istället för att publicera data som kan användas så måste alla som skall använda datat göra jobbet....
- stöd för ett språk svenska (plats 96 i världen)
Min fundering
- varför finns ingen som har en vision att svensk Digitaliseringen innebär att skapa bättre digitala plattformar där data är data och kan även presenteras på andra språk
- varför publicerar en digital expert myndighet pdf:er?
- vän av ordning förväntar sig
- dataset släpps samtidigt som PDF dokumentet med strukturerad info om man måste släppa PDF:er
- att kopplingar mellan liknande dokument publicerade i olika länder enkelt kan hittas
- att icke svenskspråkiga skall kunna ta del av informationen
- att inte varje myndighet är en SILO utan precis som Wikipedia stödjer > 300 språk med EN gemensam Wikidata så borde Sveriges myndigheters info knytas ihop, eller varför inte hela Europas myndigheter eller är visionen [data om utegym på enbart
- vän av ordning förväntar sig
Var finns visionen?
- Wikidata med alla dess fel och brister har en grafdatabas med "samma som" dvs. datat är maskinläsbart och kan förstås.... det finns relationer och externa referenser dvs. man landar på nivå i 5star modellen
-
@angela Görs det någon uppföljning angående detta, finns det innehåll eller slutsatser att ta del av? Jag kan inte hitta något om det på webbplatsen.
11.20 Hur fortsätter vi framåt?
Clas Olsson, generaldirektör ESV
-
System referenced this topic on
-
System referenced this topic on
-
System referenced this topic on
-
J jonor referenced this topic on
-
J jonor referenced this topic on
-
System referenced this topic on
-
ESV har inte gjort någon uppföljning av konferensen men vi försöker fortfarande hålla oss ajour i frågan. Vi anser att en gemensam infrastruktur för delning, lagring, förprocessering, annotering/taggning av textdata är centralt för en förbättrad styrning och återrapportering. ESV är gärna med som stöd men kan inte vara den är ansvarig för frågan. Det behövs förmodligen även tydligare signaler från DIGG och politiken för att landskapet ska ändra sig. ESV:s datalabb arbetar däremot just nu med två projekt som kopplar till frågan. Dels tar vi fram en språkmodell för att underlätta remisshanteringen på myndigheter. Den hjälper bl.a. till att kategorisera förslagen i nya utredningar och hitta tidigare svar som lämnats i liknande frågor. Dels skapar vi en modell som analysera i vilken grad anslagsvillkoren i myndigheternas regleringsbrev är styrande och hur styrningen har utvecklats över tid och rum. Vi kommer att dela alla resultat längre fram i processen.
-
@phdsvennejunker tack för återkoppling har ni tittat på Rättsinformationssystemet dom hade som ambition att skapa strukturerad information för författningar (sammanställning jag gjort)
Vi anser att en gemensam infrastruktur för delning, lagring, förprocessering, annotering/taggning av textdata är centralt för en förbättrad styrning och återrapportering
Förstudien Ds 1998:10

https://www.legislation.gov.uk
När jag dök ned i Rättsinformationssystemet hittade jag att Engelsmännen varit lite duktiga med sina lagtexter länk med exempel Corona lag - rdfRiksdagens corpus
a) lite off topic så finns ett projekt med Riksdagstrycket där man märker upp det med TEI-parla-Clarin det snygga med detta är att man gör samma för massa olika länder i ParlaMint- svenska projektyta welfare-state-analytics riksdagen-corpus, info hos Umeå Universitet
- för att data skall vara av intresse bör man ha 5 star open data

- för att data skall vara av intresse bör man ha 5 star open data

---> dom pekar ut den som pratar med Wikidatas Qnummer för politikern...
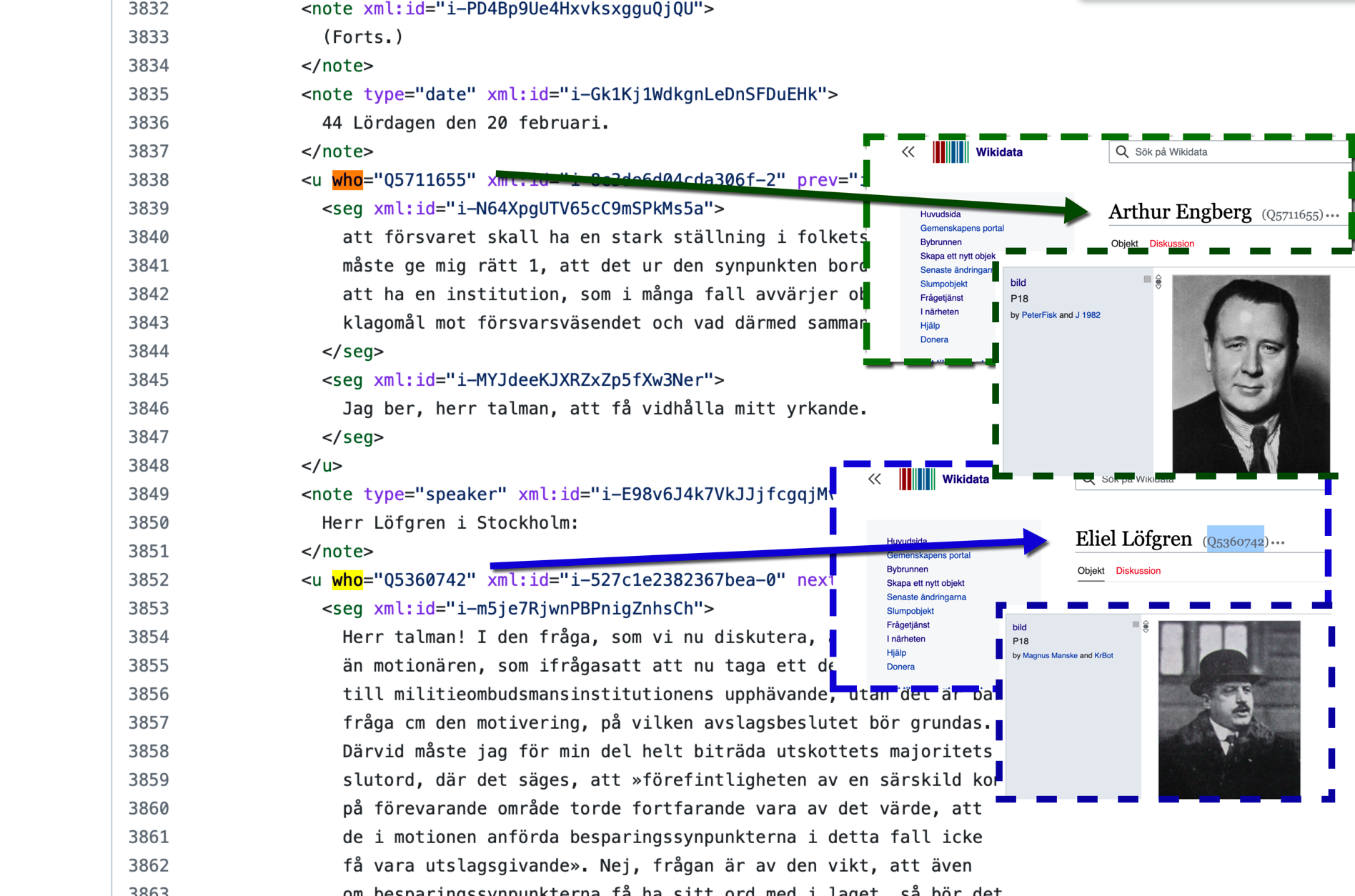
--> i wikidata kopplas sedan politikern till parti/bilder/källor etc länk
dom har skapat Notebooks och Python bibliotek pyriksdagen
Annan tanke följa upp kostnad öppna data
Tror det var @jonor som undrade vad kostar alla dessa öppna data SILOS projekt som startas. På 90-talet var jag med och byggde ESV:s datalager gissar att det hänt en del sedan dess borde det inte gå att fråga dagens datalager vilka aktiviteter som finns inom ex. öppna data och sedan kunna se belopp, vilken aktivitet det är? Att 290 kommuner har tolkat Kommunallagens krav på Anslagstavla på 290 olika sätt och skapat 290 olika lösnings SILOS som inte kan prata med varandra är nog inte den enda galenskapen hur våra skattepengar förbrukas.... att kunna se totalen som spenderas på exempelvis Öppna data tror jag skulle göra det enklare att diskutera om dagens laguppställningar skall matas med pengar eller om man skall skapa nya digitala organisationer med ett annat incitament/kompetens och hastighet.... - svenska projektyta welfare-state-analytics riksdagen-corpus, info hos Umeå Universitet
-
@phdsvennejunker jag fyllde på med lite exempel och semantiska tankar de problem vi ser se github.com/salgo60/Wikidata_riksdagen-corpus/issues/38#issuecomment-1229370127 hör gärna av dig
- jag har skapat en Magnus list med problem vi ser
- en föreläsning på Stanford zoom kommenterade denna lista vid 26:30 min
-
@Magnus-Sälgö Och sen har vi ju de nya buzz-worden ”digitala arenor”, ”digitala innovationshubbar” mm och en uppsjö projekt med olika etiketter (sätt ihop följande ord i valfri ordning: smart, sustainable, resilient, viable, data, platform, IoT, open). Mångfald är bra - när det finns ledning och styrning. Mångfald utan blir en enda röra.
-
@mistral svaret är enkelt lyft alla deltagarna till skridsklubbsnivå börja kommunicera med varandra på ett proffesionellt sätt med öppna backloggar, unika taskid:n. Jobba aktivt enligt en modell som nedan där det är tydligt att har man inte kontroll på öppna ärenden så är man på Level 1 "Process unpredictable, poorly controlled and reactive"
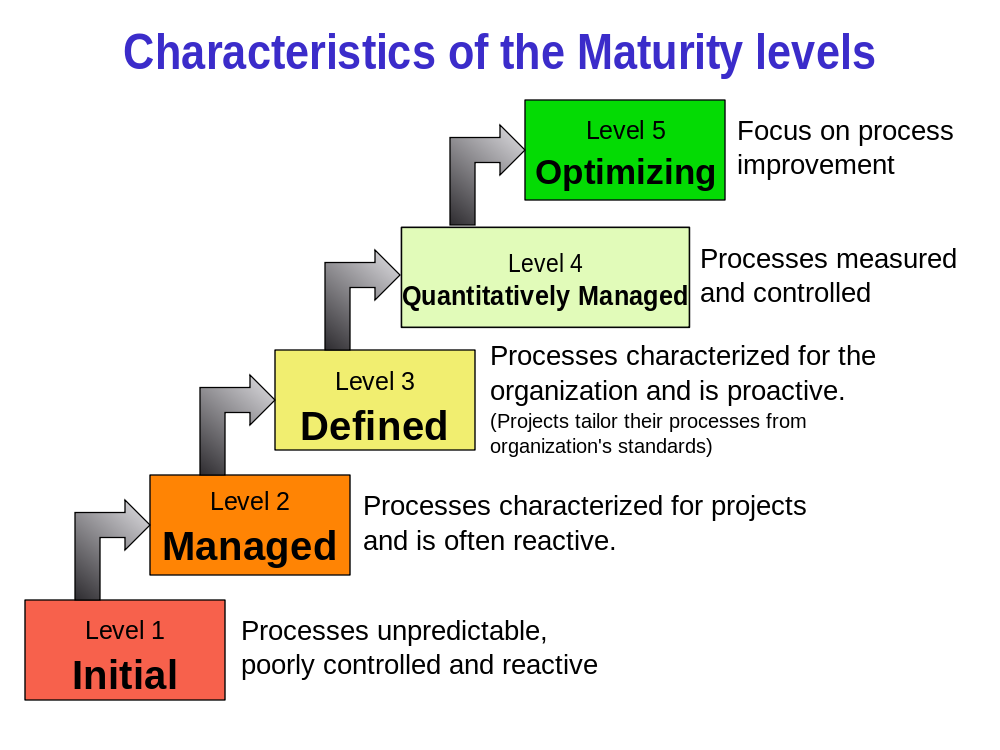
Skridskoklubbsnivå = Level 5- ->
- alla vet direkt när nyis finns tillgänglig i hela Europa
- alla vet direkt hur många plurrningar som gjorts idag och var dom gjorts, om det blev skadade och det finns färdrapporter att läsa som skrivs ofta i bussen tillbaka... is är färskvara alla skall veta var den finns
- alla tar del av alla incidentrapporter
- det finns aktiva diskussioner hur man utvecklar klubben och man letar med ljus och lykta efter kompetenta personer
- varje år utvärderar man hur processen kan bli bättre och resultatet delas... "Rapport från Prioriteringsgruppen"
- man har byggt upp ett gemensamt vokabulär se isordlista alla försöker beskriva isen på ett förståligt sätt...
det jag ser idag är en organisation som ingen läxar upp trots att man producerar medborgarförslag på 290 olika sätt, anslagstavlor på 290 olika sätt och verkar leverera sämre data än Kiribati då det gäller maskinläsbara data och DIGG som expert myndig sitter still i båten och vill inte ställa frågan behöver ni hjälp, eller vågar ha en dashboard (se min POC) med problem de ser hos myndigheter/kommuner.....
- FHM är ett bra exempel på hur dagens myndigheter kan skylla på massa saker (se 10 email om Corona data) och troligen saknar baskompetens...
")

{kind=link}