Community på Sveriges dataportal
-
Jag hittade ett svenskt bidrag från MIUN här om själva processen att släppa öppna data http://miun.diva-portal.org/smash/record.jsf?pid=diva2%3A1359760&dswid=-9111
För folk som är intresserade av att släppa data på Nivå 5 (dvs. länkad data) kan jag rekommendera att ta en titt på:
- https://www.wikidata.org/wiki/Q92286499 (artikeln om deep learning för relation extraction)
- se litteratur som handlar om semantisk annotation som är centralt för att länka från den egna dataposten och till andra i andra datamängder. Se även sameAs.
Det är i mina ögon helt essentiellt att myndighetspersoner tillägnar sig kunskap om (eller anställer nån som har koll på) ontologi, semantiska webben samt de koncept som nämns ovan för att kunna höja nivån på datan som de vill släppa som öppen data.
Ni som sitter på datan måste först annotera/matcha ihop den med andra datamängder och sen släppa. En möjlig mängd att matcha mot är Wikidata som blivit en nod i nätvärket av semantiska data och växer så det knakar.
Om ni börjar göra detta så är min gissning att ni väldigt snabbt inser behovet av en egen graf där ni kan stoppa in sådant som inte passar in i Wikidata och som ni sen kan länka permanent till när ni annoterar era dataposter.
-
@dennis_priskorn sa i Har någon här länkar till bra forskning om öppen (länkad) data?:
Jag hittade ett svenskt bidrag från MIUN här om själva processen att släppa öppna data http://miun.diva-portal.org/smash/record.jsf?pid=diva2%3A1359760&dswid=-9111
Skimmade artikeln lite (den är inte öppen tyvärr så jag fick trixa för att hitta den) och hittade ett citat från en användare som jag tycker känna igen mig i:
A lot of garbage, different codes, and different content. First, I had to filter each data point. What does this field mean? Oh, it means this. Then I pick it out and remove the rest. To start with something and get something to function (s. 223)
@salgo60 känner du igen det här?
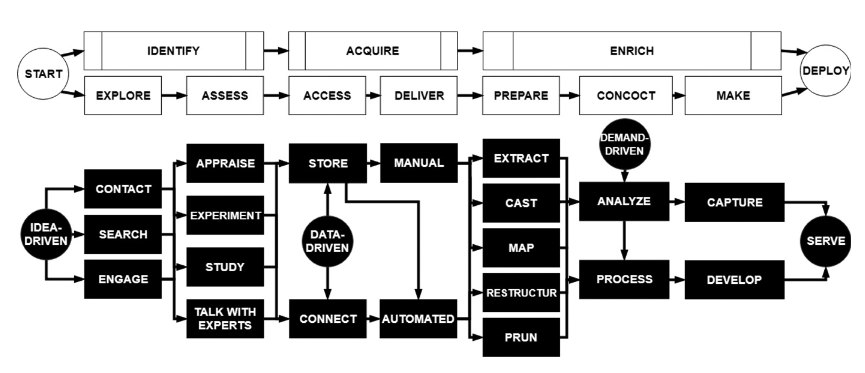
Här finns deras figur över hur hela processen ser ut från ett användarperspektiv. Datautgivaren kan göra livet mycket lättare för konsumenten genom att först annotera datan för att minska behovet av att alla nerströms måste göra en massa trixande för att begripa sig på vad som är vad och enkelt kan rensa bort allt som inte skapar värde i just detta användarfall.
-
intressant är
- att han använder ORCID för levande personer dvs. det jag efterlyste i nyttoanalysen som presenterades i förra veckan
Hlsn
0000-0003-2568-267X -
 M Maria_Dalhage moved this topic from Goda exempel och inspiration on
M Maria_Dalhage moved this topic from Goda exempel och inspiration on