Community på Sveriges dataportal
-
Kan någon förklara vad detta dataset gör datasets/760_1517 och hur det används och vem är målgrupp?
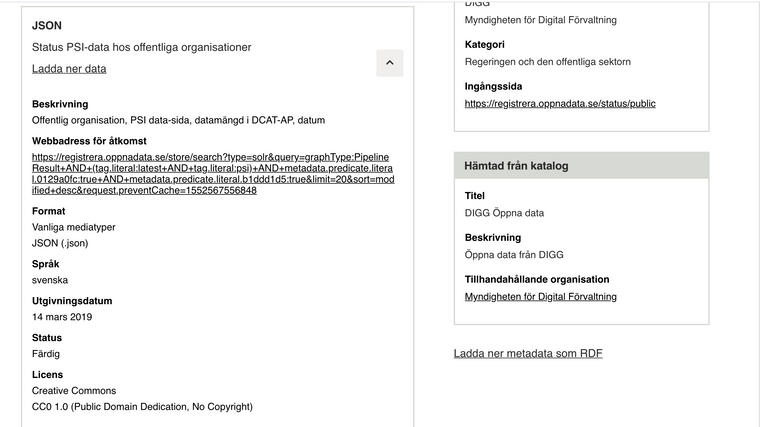
- Exempel hur den skall användas tror jag underlättar
-
@salgo60
Hej,
API:et visar status för offentliga organisationer huruvida de tillhandahåller en metadatakatalog till Sveriges dataportal, samt om de har en sida ex.org.se/psidataAPI:et används av oss själva för admin-verktyget för att identifiera vilka offentliga organisationer som tillhandahåller en katalog till dataportalen.
https://admin.dataportal.se/status/public ,
https://admin.dataportal.se/status/overview(Flyttar tråd till kategori Efterfråga data och API:er)
-
@kristine_ tackar video
- finns det exempel hur jag kan använda det?
- interna odokumenterade dataset känns inte som dom borde ligga på dataportalen.se
- min tro är att fler personer hittar till Wikipedia än till dataportalen så kan vi koppla ihop Wikipedia/Wikidata med motsvarande organisation på Dataportalen så skulle det öppna för att flera hittar detta dataset se video hur er organisation 80 gissar jag är samma som Wikidata Q836916 där vi kan visa detta på en, ar, zh, sv..... men även att det finns ibland artiklar ex Wiki Ukraina om Svenska Skatteverket --> förhoppningsvis lite enklare för icke svensk kunniga at ta del av Öppen data....
-
En före detta användarereplied to En före detta användare on Senaste redigerad av En före detta användare
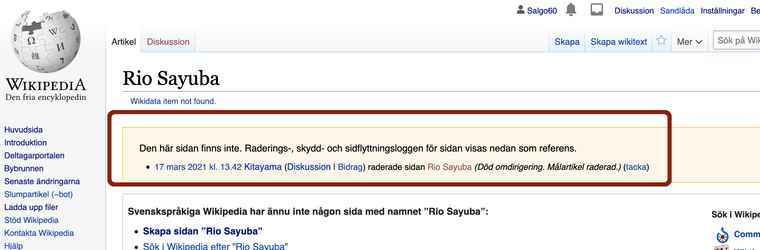
@salgo60 nu verkar datasetet borttaget länk lite mer transparens vore bra hur DIGG tänker och även att plattformen har spårbarhet...
Jämför spårbarheten hos Wikipedia när något tas bort så kan man se det med ev. kommentar
- Borttagen sida sv.wikipedia Rio_Sayuba som togs bort för 3 minuter sedan
-
@salgo60 Hej,
Api:et är inte borttaget men däremot håller vi på med en uppdatering av vår metadatakatalog som dataportalen skördar. Därför är inte datamängden synlig via dataportalen. Metadatakatalogen ska snart vara uppe igen dock, då kommer den åter vara sökbar på dataportalen./Kristine
-
@kristine_ och dokumenterad? av det jag såg känns det inte som den skall finnas på dataportalen bland andra dataset....
-
@salgo60 Här håller jag inte med dig. Allt behöver inte vara perfekt innan man publicerar sin data. Det är viktigare att man kommer igång och arbetar med ständiga förbättringar. Annars kommer man arbeta rätt länge innan man når några effekter och risken är att mycket data aldrig öppnas upp och då får man heller inte in synpunkter på vad som behöver förbättras.
-
@björn-hagström sa i Beskrivning: Öppna data från DIGG:
Annars kommer man arbeta rätt länge innan man når några effekter och risken är att mycket data aldrig öppnas upp och då får man heller inte in synpunkter på vad som behöver förbättras.
Nix felkompetens gör att du aldrig kommer i mål.... nu är vi > 200 miljoner in i DIGGs resa och ser 2 dataset man lyckats skapa....
Vi har DIGISAM som starta 2012 med kulturdata och Europeana samma år 2012 som skulle skapa länkade data och samla ihop museernas material i Europea och bli en referens och följer man upp detta så har vi bevis att inkompetens löser inga problem
- 2021
** museerna i Sverige klarar inte att skicka sitt material till Europeana utan alla personer som heter Carl Larsson blandas ihop
** ingen av dom 5 museerna jag kontaktade om detta fel vet hur man felrapporterar till Europeana
** Europeanas R&D manager Antoine Isaac har jag försökt att ha en dialog med om vi kan göra change management på Wikidata Entities se T251225 men jag gissar att dom inte vågar köra igång något för dom har lärt sig att museerna inte har digital kompetens och nu har man tyvärr börjat surra om att AI skall fixa dessa metadata brister... ingen seriös tror att man med dålig metadata kan göra bra AI....
** ett annat anti-pattern jag ser är att Europeana delar ut massa pengar så inga vill kritisera dom för att man är rädd att inte få del av kakan....
*** intressant är att se reaktionen från engelska WIkipedia som direkt reagera på dålig kvalitet och stoppade alla länkar till Europeana pga av för dålig kvalitet T243764
Det är viktigare att man kommer igång
- jag plockade ned DIGGs leverantörsfakturor länk och ser dom som lever gott på Öppen data trots dagens fel och brister är fakturerande konsulter --> kommer vi få se samma okritiska synpunkter som jag ser av > 100 miljoners projektet Europeana....??
- DIGG har till dags dato betalat konsulter och andra 200 miljoner och av detta har 2 dataset dykt upp där det ena har tvivelaktig kvalitet
- men denna "allt behöver inte vara perfekt" logiken så känns det som man skulle bejaka iden att ge körskolelärare 100 miljarder för att skapa självkörande bilar och sedan skulle vi komma till dom med synpunkter när inte bilen går dit vi vill..
") det är bara när man leker med andras pengar man resonerar så....
det är bara när man leker med andras pengar man resonerar så....
Skall Sverige bli bäst i världen på öppen data ...
Då måste vi ha kompetens där- det Agila sitter i ryggraden
- man måste förstå grundläggande saker som versionshantering och change management
- en organisation som DIGG måste peka med rakhand när det svamlas om öppen data skall vara på svenska eller engelska utan förklara att 2021 så gör vi språkoberoende lösningar som skall fungera att mata internationella AI lösningar
- när Google i veckan pratade om sin Dataset search och vikten av DOI då är man snabb och för dessa tankar till Sverige och förklarar hur detta skall göras...
- när man frågar varför EDP inte har en kunskapsgraf länk men Google har svarar man att man vagt varför inte.... varför tar inte Sverige tag i detta och visar ledarskap vi som skall bli bäst i världen....
- Google, Tesla, Amazon som tar ledarskap gör det genom att ha intern kompetens... jag är rädd för de stora konsult inköpen hos DIGG pekar på interna brister och blir inte mindre orolig när denna "allt behöver inte vara perfekt" ide påhejas...
Med hopp om att jag har fel
- 2021
-
@salgo60
Hej,
DIGG ansvarar för flera verksamheter däribland digitala tjänster och infrastruktur såsom inom digital post, e-id, e.handel, digital tillgänglighet m.m. Dessutom samordnar och analyserar vi utvecklingen av digitalisering av den offentliga förvaltningen och bistår regeringen på olika sätt i detta arbete. Dessa verksamheter bekostas av våra anslag och särskilda regeringsuppdrag. Det är naturligt att vi både jobbar med egen personal och tillsammans med leverantörer för att genomföra våra uppdrag. DIGG:s information om fakturor som vi nyligen tillgängliggjort som öppna data relaterar till vår hela verksamhet. Välkommen att gå in på digg.se för att läsa mer om DIGG:s verksamhet.Jag vill påminna om forumet uppmuntrar till en konstruktiv diskussion. Tyck gärna till om våra och andras tjänster, data och API:er, men håll en god ton. Vi kommer att ta bort inlägg som är kränkande eller nedlåtande mot moderator, andra forumanvändare samt övriga som inte använder tjänsten.
-
Detta inlägg är raderat!
-
@salgo60 sa i Beskrivning: Öppna data från DIGG:
@kristine_ och dokumenterad? av det jag såg känns det inte som den skall finnas på dataportalen bland andra dataset....
@salgo60
Jag har undersökt frågan nu och den dokumentation om API:et som finns är i två delar:
https://entrystore.org/kb/search/
och ett formell uttryck via OpenAPI (Swagger) här:
https://entrystore.org/api/Ska uppdatera informationen så det framkommer om datamängden på dataportalen också.
Men samtidigt inser vi att den dokumentationen är för generell och skulle kräva mycket av folk. Vi ska titta vidare om vi kan ta fram en lite mer specifik beskrivning/guide som förklarar hur man söker ut just information om datamängder, distributioner, utgivare etc. ur detta generella API.
-
@kristine_ ok det jag funderade på var mer om bättre dokumentation av enskilt dataset eller att saker som tas bort blir spårbara....
- om jag fatta rätt togs datasets/760_1517/ bort men
- i söndags dök datasets/760_1536 upp.... verkar som något batch jobb körs som la dit det igen... med annat id....
Rent generellt tycker jag att saker som
- finns det en relation mellan dataseten ovan?!?!? så skall det synas i metadata...
- versionshantering dvs. det skall vara spårbarhet mellan nya version
- tydlighet när saker läggs till... det känns som inte det finns i metadata
- konstiga termer som "utgivningsdatum" känns fel term... för något automatgenererat...
- osv....
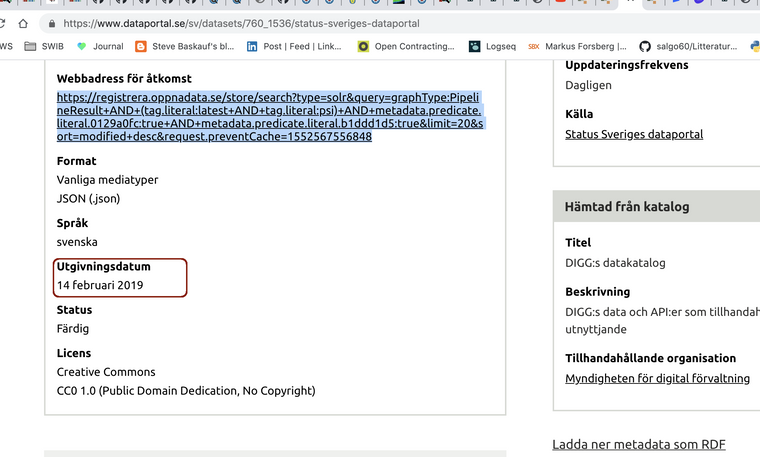
RDF:en accrualPeriodicity säger DAILY men inte mer https://admin.dataportal.se/store/760/metadata/1536
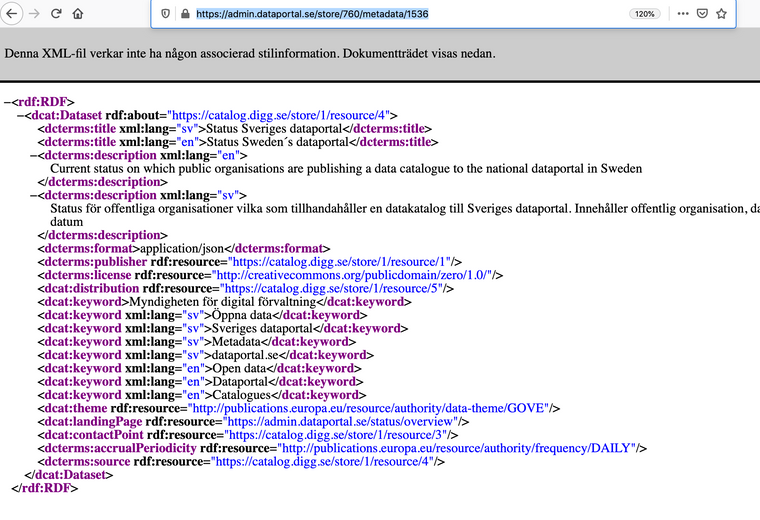
Detta är ingen prio för mig men det tar emot att dyka ned i dataportalen.se när den känns så virrig... men det kan lika gärna vara skit bakom mina spakar.... mer dialog med användare behövs... eller fler användare är min tro...
-
@salgo60 Jag vet inte riktigt var jag ska börja svara på detta men du är verkligen ute och vinglar från dike till dike här. Öppna data är en väldigt liten del av DIGGs verksamhet som Kristine också påpekar och den stora delen av DIGGs insatser för öppna data handlar inte om att själva publicera data utan att skapa strukturer så att andra ska kunna arbeta med det på ett bra sätt.
När det gäller alla de brister du pekar på så ser jag inte att något av detta hade blivit bättre av att man väntat på att data var perfekt innan man publicerade den. Det enda som hade skett var att det inte hade publicerats någon öppna data alls och då hade vi inte kommit någonstans med öppna data i Sverige. Du hade inte haft något att kritisera och vi hade inte kunnat ha en diskussion kring hur man kommer vidare och gör saker bättre.
-
@björn-hagström 1 dataset efter 2 år... det är väl inte så mycket att diskutera utan mer att börja leverera.... ingen säger att DIGG skall vänta jag är mer förvånad att inte mer gjorts...
Det känns inte som det tänks data... att skapa ett dataset för ett diarium tar en timme....
och även om det är en liten del så skrivs det rapport på hur bra det går för Sverige.... skall man vara datadriven så publiceras saker som dataset och även de olika rapportrarna som idag dyker upp i PDF innehåller data som borde bli enskilda dataset jmf forskarvärlden...
- dataset som jag från utsidan ser borde finnas för en myndighet (och särskilt DIGG som bör vara the leading star...)
-
publicerade rapporter - idag ligger dom lite här och där
- nu finns det i många rapporter ett diarienummer/ unikt id passar perfekt att ha som ett dataset istället för här och där på en web... gärna även vad som komma skall, kontakt person, diskussions yta....
-
kan ESV datalabs nya portal ha data om DIGG som budget etc. så borde myndigheten själv beskriva sig med instruktion, ansvariga, även lyfta it de mål som finns i ett dataset... även fast Svenne Junker tycker det verkar svårt så känns det inte svårare att ha egna objekt med start/slut
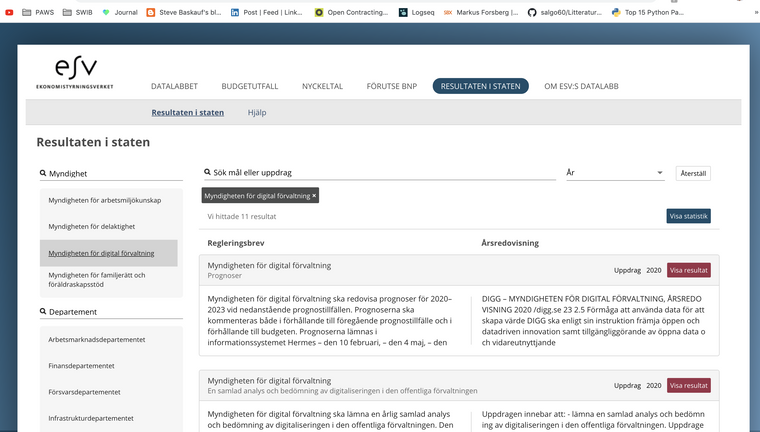
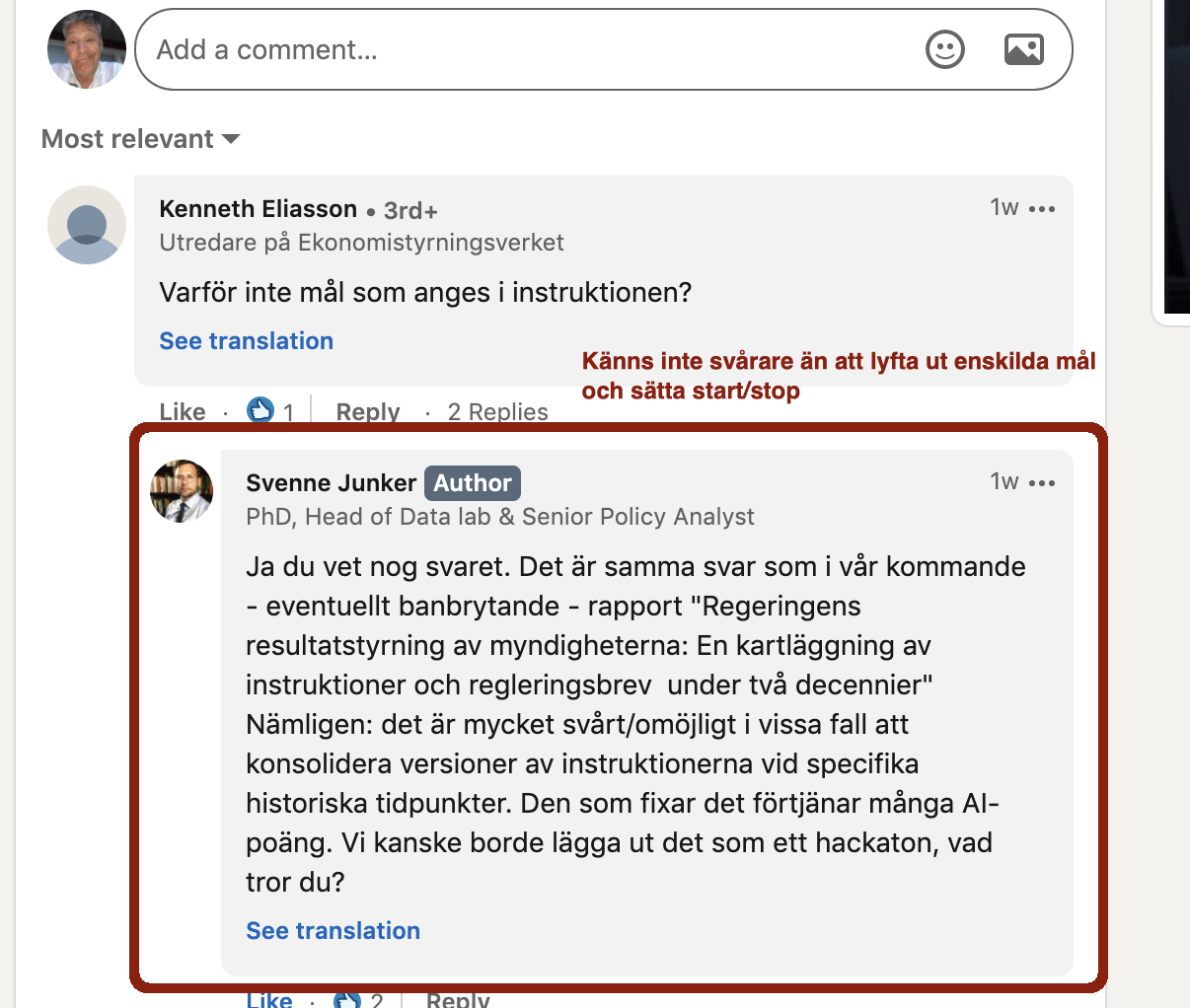
-
lär av forskarvärden publicera dataset MED rapporten dvs. pdf rapport som Dnr: 2019-139 "Uppdrag att öka den offentliga förvaltningens förmåga att tillgängliggöra öppna data, bedriva öppen och datadriven innovation samt använda artificiell intelligens" blir väldigt flummig och kollar man på slutsatsen som är att räkna dataset så blir det skevt när DIGG har 2 dataset och 50% av dessa verkar omöjliga att förstå vad det är dvs, man mäter inte kvalitet

-
- diariet var hittar vi det?!?! ett dataset? kolla på Linköpings kommun
- finns tydliga mål i Regleringsbrevet så borde det brytas ned till mål som DIGG driver och publiceras i ett dataset... att räkna framgång som "genom att antalet datamängder på Sveriges dataportal har mer än tredubblats" känns lite galet då SCB har 4534 av 7121 dataset
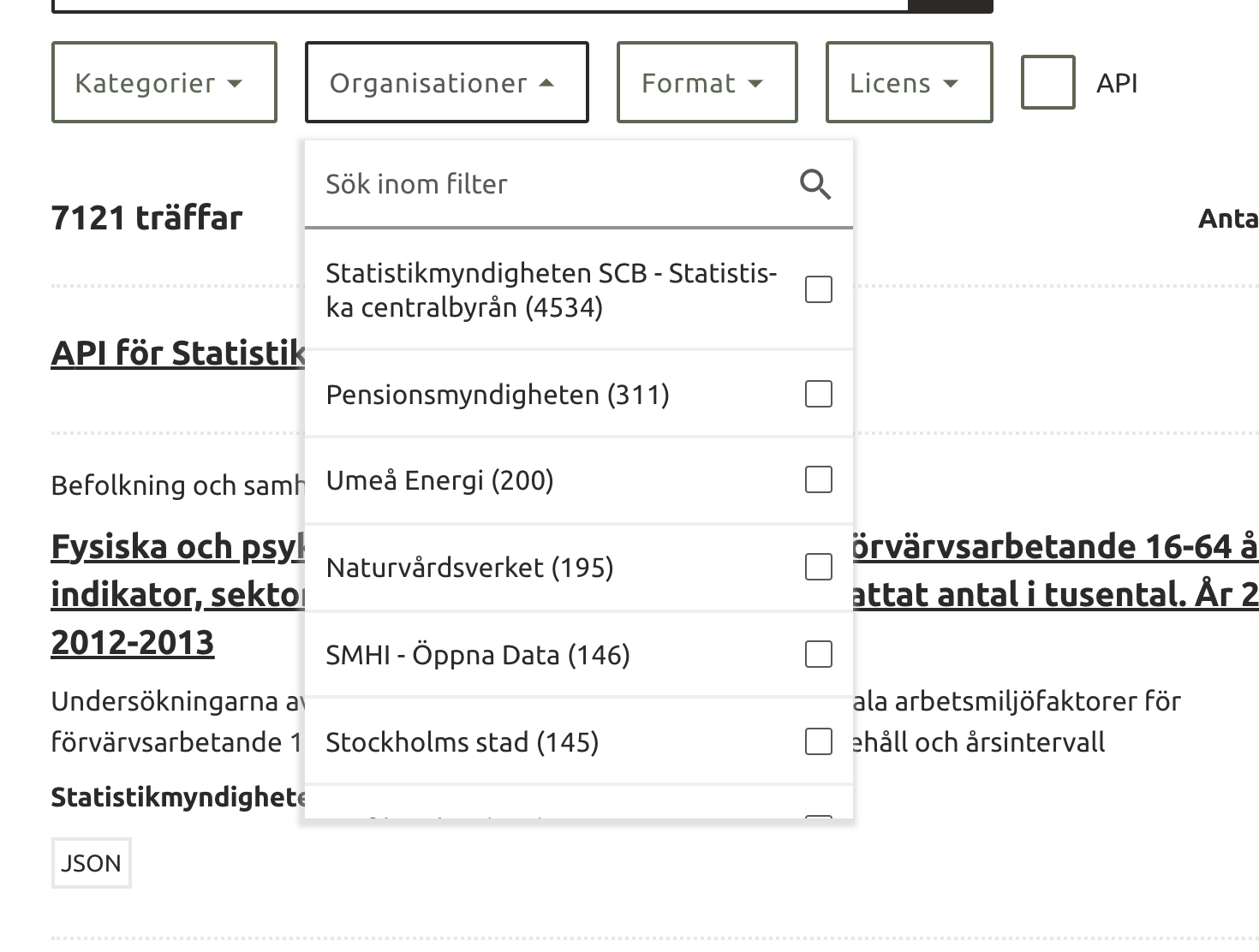
Finns säkert massor att göra och saker tar tid men nu är vi 200 miljoner in i denna resa så saker borde dyka upp och har det iunte kommit ännu är det stor risk att vi kommer att ha yesterdays weather om 2 år
Tim Berners Lee säger internets grundare säger detta att vara datadriven för en myndighet på ett bra sätt att man inte skall gömma data i massa snygga websiter utan publicera rå data som data link "making the world better"
- dataset som jag från utsidan ser borde finnas för en myndighet (och särskilt DIGG som bör vara the leading star...)
-
@salgo60 Det finns en hel del data DIGG kan och borde publicera och jag tror mer är på gång men det som ser enkelt ut för en utomstående är inte alltid det för den som ska göra jobbet. Till exempel räcker det inte att skapa datamängden. Man måste också ha koll på personuppgifter, sekretess, hur det ska publiceras, hur informationen ska exponeras, hur man eventuellt anpassar den till en standard, övertyga ägaren internt att publicera den, få resurser till att göra arbetet när alla resurser är upptagna och ett antal andra saker som att skapa dokumentation så att du inte skäller på dem. Det är inte så bara.
Sedan trodde jag vi kommit förbi stadiet med de 200 miljonerna. De har bland annat gått till väldigt många andra saker än att publicera öppna data. Det är en rätt oärlig diskussion av dig här.
-
@björn-hagström ingen har sagt att detta skall vara enkelt.... jag tror snarare vi inte förstår hur mycket med kompetenser som saknas som detta som jag tjatar om med kunskapsgrafer eller AI/ML och ha dataset som är fungerande... sedan det @Maria_Dalhage frågor om interoperabilitet så kan man ju fråga sig finns det en tanke hur t.ex. data publicerat av ESV datalab borde inte det ha en koppling till DIGGS fakturor och hur dom skall "jobba ihop"? om inte vem för man denna dialog med? hur följer man dom tankar som finns...
om DIGG som är en ny myndighet har problem med att publicera som Öppen data vem skall då göra Sverige bäst i världen på digitalisering och att alla lyfter sig, och hur skall old schools myndigheter kunna ta klivet? nån verkar ha lovat något som blev en tummetott... intressant är att samme herre tycker att vi skall även analysera vad vi är dåliga på vid 11:40 var är denna "Root cause analysis" (RCA)... snyggt vore att hoppa i säng med Jobtech och definera upp dom skills som en Digital myndighet skall ha som sedan kunde användas av andra som en checklista .....
Förr mig skall inte detta ta 2 år.... börja publicera dataset och ange vad det är för brister i data ( rekommendation vid 18 min i denna pod med tillägg "eat your own dog food")

-
@salgo60 Det var när du skrev:
"att skapa ett dataset för ett diarium tar en timme"
som jag tolkade dig som att det inte var så svårt att publicera öppna data. Samtidigt klagar du på brister när den inte är perfekt. Det är inte lätt att göra dig nöjd:) -
@björn-hagström @salgo60
Härlig tråd! Hetta är bra! Vi kan väl bara konstatera att det tar tid för oss myndigheter att tillgängliggöra våra öppna data. Och trots att vi sedan 10 år tillbaka haft en PSI-lagstiftning så går det långsamt. Ur mitt perspektiv, och kopplat till länkad data så uteblir effekterna eftersom mycket av den data vi vill länka till inte är öppen idag, och kommer sannolikt inte bli öppen på två år. (Den tid myndigheterna har på sig att anpassa sina särskilt värdefulla datamängder till ny lag.) En uppenbar anledning till att vi inte kan släppa data som öppen är att den är "inlåst" i olika system. Vi behöver titta på hur vi kravställer IT-system. Vi behöver ta höjd för att data går att dela mellan olika system och att data går att få ut även när vi ersätter ett system. Krav på öppna standarder som går att implementera i öppna källkodssystem är en förutsättning för att kunna få ut mer öppna data. -
@maria_dalhage ja men konstruktiv hetta vill jag se
se exempel nedan hur om man gör rätt med persistenta identifierare så kan forskning 1750 kopplas ihop med länkade data 2021Jag gjorde i veckan en övning att koppla ihop Litteraturbanken <-> bilder som har semantisk interoperabilitet med WIkidata <-> forskning på Runstenar av Uppsala Universitet och Riksantikvarieämbetet dvs. många SILOS och många kockar och vi delar kanske inte helt samma världsbild plus att med all rätt finns ett Trust issue mellan domän specialister och hobby runeologer
se min artikel Structured_data_for_GLAM-Wiki/Roundtripping/KMB
Det intressanta här är att allt detta går rel. enkelt för att
- runforskarna redan 1750 skapade persistenta identifierare till de olika runstenarna
- när nya runforskare hittade på nya nummer serier så refererade man till dom äldre
- nu i #Wikidata gödslar vi med ca 5000 identifierare vi kopplar ihop så denna forskning blir inte inlåst och vi kan koppla ihop allt
- som jag visar i artikeln så genom att dessa forskare redan 1750 flrstod vikten av persistenta unika identifierare och att vi idag 2021 sätter upp skyltar bredvid runstenar i naturen så kan även vi hobby runeloger ta bilder och förklara vad vi ser.....
Inlåsnings effekten = 0 även fast det är en bok Bautil från 1750
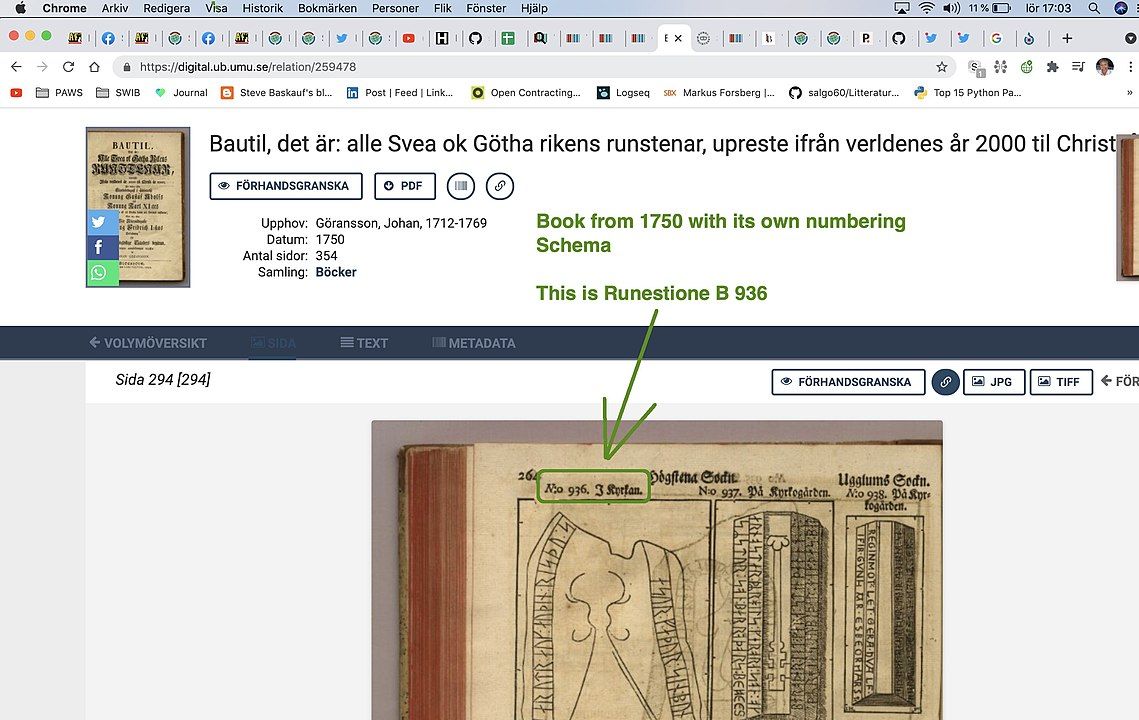
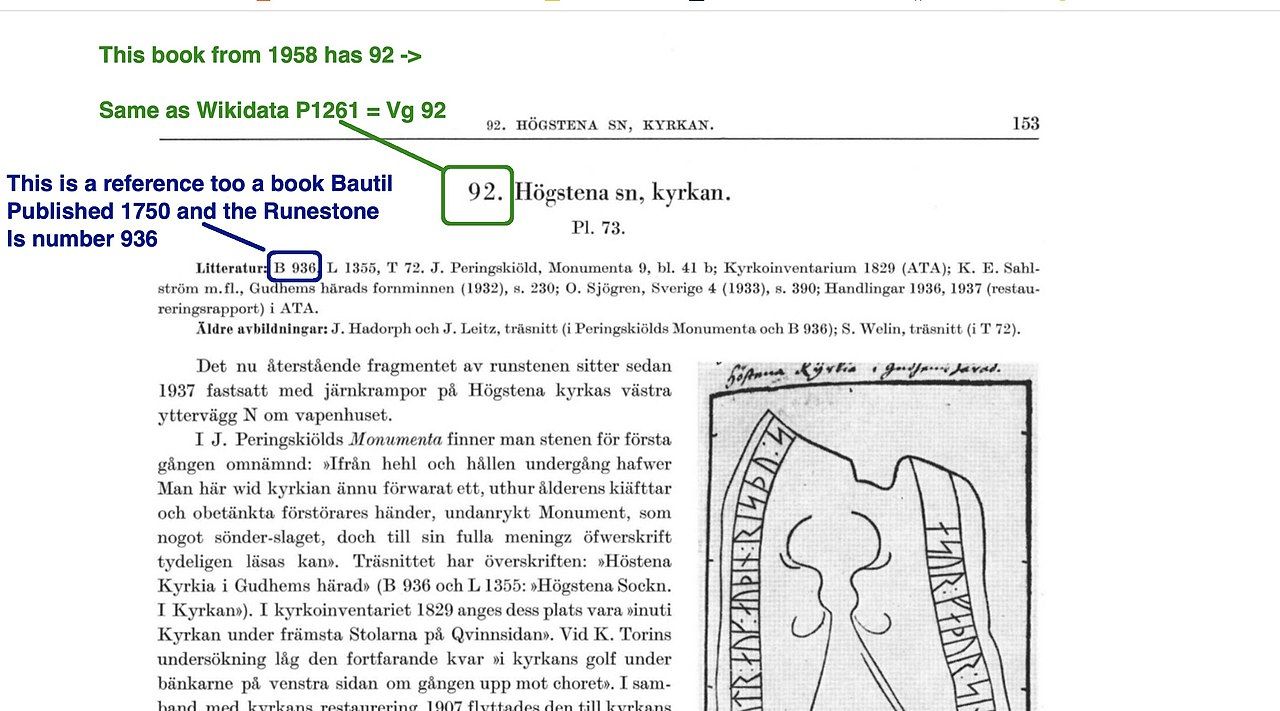
det är detta tänk jag skulle vilja se är att vi har diskussioner om.... kultur Sverige startade 2012 med att diskutera detta och har enligt mig gjort massa misstag
- fel kompetens i organisationerna
- avsaknad av tydlig vision
- jobbar inte med moderna plattformar som GITHUB och change management
- väldigt svårt att ta åt sig tänket med persistenta identifierare se hur flera 100 miljoner plöjs in i ett EU projekt Europeana som inte levererar
-
 K Kristine_ moved this topic from Efterfråga data och API:er on
K Kristine_ moved this topic from Efterfråga data och API:er on