Community på Sveriges dataportal
Communityskapande i Dataportalen - fler funktioner eller inte?
-
Full av energi! Idag hade vi ett möte med ett antal dataproducenter om hur vi tillsammans kan svara på frågor kring våra datamängder och API:er. Vi tittade på hur det ser ut idag i Dataportalen och vad vi skulle kunna göra imorgon.
Målsättningen med mötet var att:
- Få kännedom om dataproducenterna vill ha en öppen dialog kring sina datamängder eller inte.
- få kännedom om dataproducenterna vill att diskussionstrådar ska synas på nivå datamängd eller organisation. (De som deltog å mötet såg behov av bägge).
Mest intressant var att den nya funktionaliteten att kunna visa diskussionstrådarna vid datamängderna istället för via Communityt (det vi har kallat tråda ut diskussionerna) upplevdes av flera av er som nice to have, men kanske inte prio på vad vi/DIGG bör satsa på.
Diskutera gärna med oss i denna tråd om vad ni vill att Dataportalen fokuserar på. Det är tillsammans som vi kommer fram till den mest hållbara lösningen!
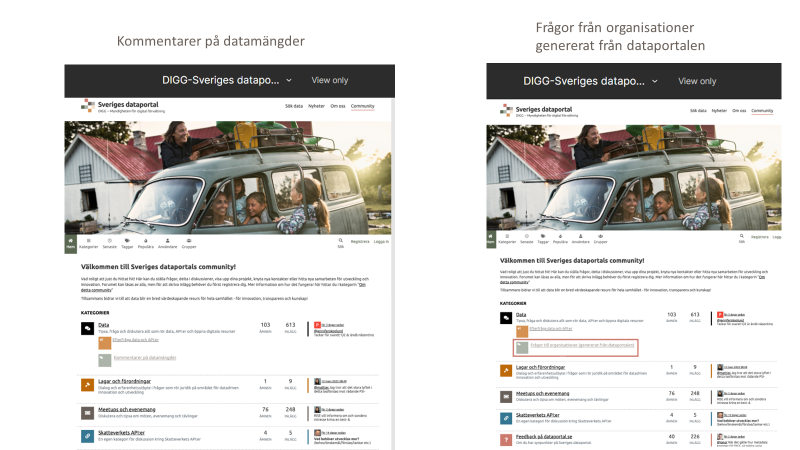
Nedan är bilder som visades under mötet. Två bilder som visar vad vi skulle kunna ändra på Dataportalen.se:
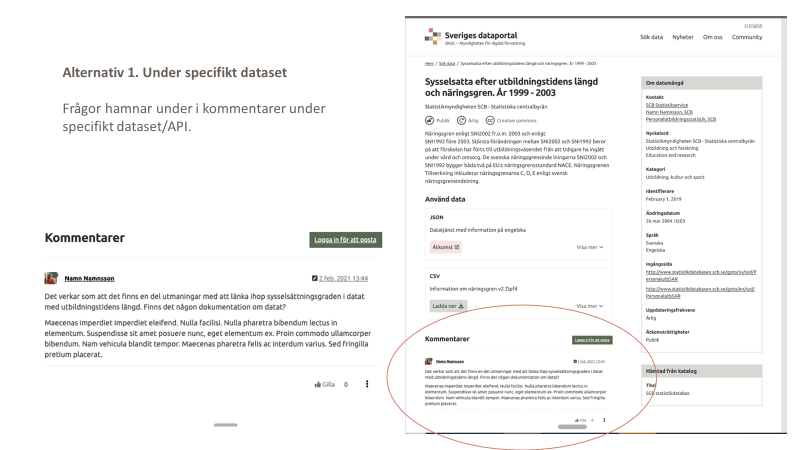
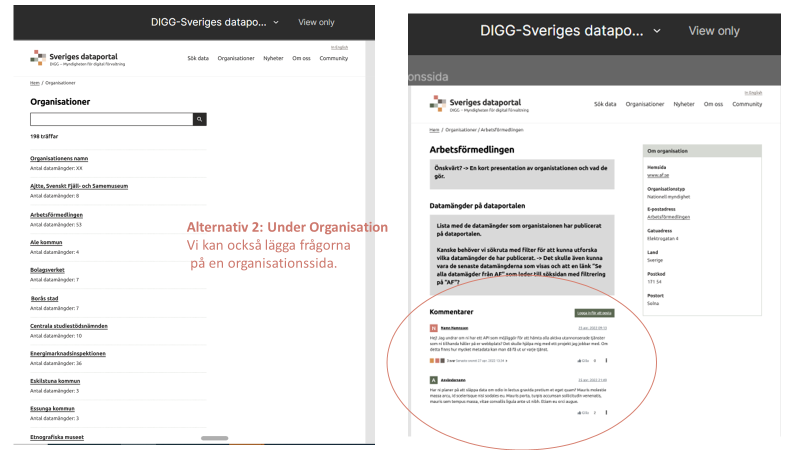
Hur det skulle se ut från Communitysidan:
Tack till alla ni som deltog på mötet och som var så uppriktiga och tydliga i var diskussion.
-
@Maria_Dalhage Bra med kommentarsfunktion, nivå beror ju på om kommentaren gäller enskilda datamängder eller frågor som är gemensamma för flera datamängder under organisationen. Är det kanske tänkt att inläggen ska riktas/aviseras till den organisation som förvaltar/äger datamängden så att man kan förvänta sig svar därifrån?
Man borde kunna länka i ett inlägg eller från en kommentarstråd och koppla till de datamängder som berörs så att det inte är 1:1 mellan inlägg och en datamängd eller en organisation.
När man är inne på det vore det bra med funktioner för uppföljning av ärenden motsvarande GitHub issues el. liknande angående en eller flera datamängder, eller koppling till en sådan sida för ärendeuppföljning som är tillgänglig från varje berörd datamängd/objekt.
-
@jonor Jag tolkar det som att det du efterlyser är den publik kundtjänst? Idag har vi info@digg.se. Det är ingen öppen kanal idag. Teoretiskt skulle DIGG kunna be dem som ställer frågor att i första hand vända sig till Communityt och där svarar vi på frågan publikt. Det finns sannolikt både för-och nackdelar med att göra på detta sätt. Men det är en intressant tanke att, i alla kanaler, jobba öppet i första hand, om inte särskilda skäl (bl.a. sekretess) föreligger. Tror att @jenniferskoglund kan ha tankar kring detta inlägg.
-
@Maria_Dalhage Ok, jag vet inte om jag har missförstått ämnet i någon aspekt, ni frågar dataproducenter om de vill ha en öppen dialog kring sina datamängder. I egenskap av konsument vill jag definitivt se en öppen dialog och kunna dela synpunkter, frågor och svar, och jag vet inte riktigt vad det kan finnas för skäl eller exempel på situationer där man inte skulle vilja ha det. Möjligen då att det krävs ett administrativt arbete för att granska kommentarer på samma sätt som inlägg i det nuvarande forumet, det borde ju vara inräknat i ekvationen.
Bättre än att en datamängd kopplas till en e-postadress vore att den kopplades till en ärende-sida i ett projekt eller i brist på detta en forumtråd där man kan följa upp och referera till frågor om datamängdens användning och utveckling.
Jag tror att det jag var inne på i tidigare inlägg är att kommentarstrådar borde kunna orienteras kring förvaltande organisation eller det projekt som datamängderna samlas under. Man kan t.ex. tänka sig 10-20 datamängder som innehålller likartad information och drivs under samma administrativa enhet på en förvaltning.
-
en ärende-sida i ett projekt eller i brist på detta en forumtråd där man kan följa upp och referera till frågor om datamängdens användning och utveckling.
Kanske snacka ihop sig med @mattias och använda handlingar.se och ha färdiga mallar där datamängden fylls i med fråga och sedan anges om man fick ett bra svar eller inte
Många kommuner/ myndigheter verkar kommunicera utan att man får ett spårbart nummer så man kan följa dialogen det löser detta och kommunerna kanske skärper till sig... samma med dom flesta myndigheter jag snackade med 2019
- av alla kommuner jag kontaktat > 70 har åtta gett mig ett ärendenummer
- helpdesk med helpdeskid är enormt ovanligt
-
positivt i veckan fick jag ett bra svar av RAÄ med heklpdesknummer I-2206-0290 dock visar detta svar att dom har enormt skitig data så där skulle jag vilja se vad kommer dom att göra dvs. se en backlog/roadmap vart dom är på väg
- kolla gärna på svaret från RAÄ som visar hur jobbigt det är att underhålla data... RAÄ har enormt mycket '''skit i data''', system som inte finns osv.... skall vi komma igång med öppna data så måste alla aktörer kunna kommunicera med varandra och säga nu ändrar jag mitt data 31/6 kl. 8:00 så då slutar era applikationer att fungera.... i bankvärlden där jag kommer ifrån där fanns färdig definierade meddelande SWIFT och alla inser att levererar man inte så är man inte en bank på måndag... den mogenheten finns inte med Öppna data.... en lösning på denna omogenhet är att man sätter upp nya funktioner som ser till att data tvättas och blir användbart se video Corona data på GITHUB som Our World in Data levererar där alla världens länders data samlas som Sverige inte kan leverera dataset men hämtas in via en websida
- jag skickade x antal email till folkhälsomyndigheten start 29 dec 2020 men dom fatta aldrig att data skall levereras som data och idag 2022 är det fortfarande en dålig websida OWID hämtar sitt data från se video
- kolla gärna på svaret från RAÄ som visar hur jobbigt det är att underhålla data... RAÄ har enormt mycket '''skit i data''', system som inte finns osv.... skall vi komma igång med öppna data så måste alla aktörer kunna kommunicera med varandra och säga nu ändrar jag mitt data 31/6 kl. 8:00 så då slutar era applikationer att fungera.... i bankvärlden där jag kommer ifrån där fanns färdig definierade meddelande SWIFT och alla inser att levererar man inte så är man inte en bank på måndag... den mogenheten finns inte med Öppna data.... en lösning på denna omogenhet är att man sätter upp nya funktioner som ser till att data tvättas och blir användbart se video Corona data på GITHUB som Our World in Data levererar där alla världens länders data samlas som Sverige inte kan leverera dataset men hämtas in via en websida
-
positivt även med Riksarkivet där man nu på GITHUB får bra svar och jag inser hur jag tidigare missförstått vad dom har och lagt ned några 100 timmar att göra fel
") , lite intressant synpunkt av en nestor på WIkipedia är att det är bra som det är för han tycker Riksarkivet har dålig kolk på svenska församlingar - data som data och koppla ihop sig är inte lätt
, lite intressant synpunkt av en nestor på WIkipedia är att det är bra som det är för han tycker Riksarkivet har dålig kolk på svenska församlingar - data som data och koppla ihop sig är inte lätt- samma problem med Riksarkivet dom har "skitigt data" som att alla skolor betecknas vara en myndighet men dom verkar sakna en strukturerad process med en backlog där saker som detta kan planeras in.... det är enormt mycket arbete med data och datakvalitet... dagens fire and forget där data laddas upp och sedan struntar man fungerar inte
- dock bra att som konsument veta att Umeå kommun kommer enl. @Maria-Söderlind nog aldrig att ha 5 star open data och säga konstnär samma som WD eller annan och att det tar 2 år att rätta stavfel är vad man kan förvänta sig..... organisationen är inte datadriven eller proaktiv....
-
@Maria_Dalhage uppmuntra bra beteende och gör det enkelt för konsumenten av data att se vilka som "sköter sig"
- kunna ange om publik backlog finns
- vid sökning kunna filtrera bort dom som inte har det
- kunna se planer i en utvecklingsplan & roadmap
- vid sökning kunna filtrera bort det
- exempel Riksarkivets planer / Wikidata planer
- vid sökning kunna filtrera bort det
- dataset som har kodexempel, där såg jag som en variant att ha GITHUB ämnen se min dialog med Riksarkivet
- enkelt kunna skicka fråga om data/fel och spårbart som jonor säger
- som sagt snacka ihop dig med handlingar.se så email kan skickas med 2 klick och som @jonor säger att dessa email blir spårbara/ status kan följas upp/ kunna se all frågor inom samma område (jmf Öppna data hos handlingar.se)... att prata med 290 kommunerna fungerar inte tycker jag min test visar men även projekt som NSÖD kom fram till att en kulturresa skall göras vilket jag tolkar att det fungerar inte och dagens struktur kommer aldrig att leverera
- exempel hur jag ser vilka kommuner som har Öppna data där jag skrivit en Notebook för att hämta datat, kommuner som svarar, kommuner som inte ens har en PSI data sida, kommuner jag börjat prata om licenser på bilder, kommuner jag frågat om att ha metadata vad bilden föreställer samma som ex. Wikidata
- som sagt snacka ihop dig med handlingar.se så email kan skickas med 2 klick och som @jonor säger att dessa email blir spårbara/ status kan följas upp/ kunna se all frågor inom samma område (jmf Öppna data hos handlingar.se)... att prata med 290 kommunerna fungerar inte tycker jag min test visar men även projekt som NSÖD kom fram till att en kulturresa skall göras vilket jag tolkar att det fungerar inte och dagens struktur kommer aldrig att leverera
-
@Magnus-Sälgö Att kommunerna ska lägga resurser på att koppla ihop sitt öppna data med WD - känns det verkligen korrekt? Är det verkligen detta de kommunala pengarna ska läggas på?
Ja, det tog oss två år att rätta upp stavfelet i namnet - men å andra sidan så blev det gjort till slut. Jag har aldrig sagt att man ska förvänta sig att det tar två år. Allt som man jobbar med inom en kommun hamnar i en prioriteringsordning. Att rätta ett stavfel, kanske hamnar långt ner hos vissa verksamheter men har högre prioritering hos andra.Om de verksamheter som delar öppna data inom kommunerna fick lite beröm och "bra gjort att ni börjar dela öppna data" istället för bara påpekande om brister (vilket vi också ska ha jag säger inget annat), då kanske vi skulle komma framåt snabbare?
Alla kan vi göra fel, men vi försöker hela tiden bli bättre, det är väl det viktiga?
Jag tror personligen att vi kommer snabbare framåt om vi försöker lyfta och stötta varandra istället för tvärtom. Men vi får alla ha olika åsikter. -
@magnus-sälgö tack för tips! och jag håller med om att Handlingar.se är en fantastisk tjänst som visar på hur offentlig sektor kan jobba mer proaktivt med öppenhet med stöd av nya tjänster. För er som vill ha mer information om handlngar.se så kan ni bl.a. titta på inspelningen: https://nosad.se/workshops#offentlighetsprincipen
-
@Maria-Söderlind bra fråga
kommunerna ska lägga resurser på att koppla ihop sitt öppna data med WD
kort svart NEJ men ni borde vara mer datadrivna och ha panik
Långt svar: det är detta med att förstå 5-stardata och varför ni har en web... frågan kan ställas tvärtom varför skall man lägga ut öppna data med textsträngar om konstnärer som är felstavade?!?!? Vart vill ni med eran web? era skulpturer...
Mitt kanske naiva svar är mervärdet och göra dessa skulpturer findable ge besökare mer info
- koppla samma som
- i detta fall gjorde jag jobbet åt er så det är bara att hämta
- jag gjorde även ett schema --> i en perfekt värld så skulle alla kommuner nu leverera data enligt er modell
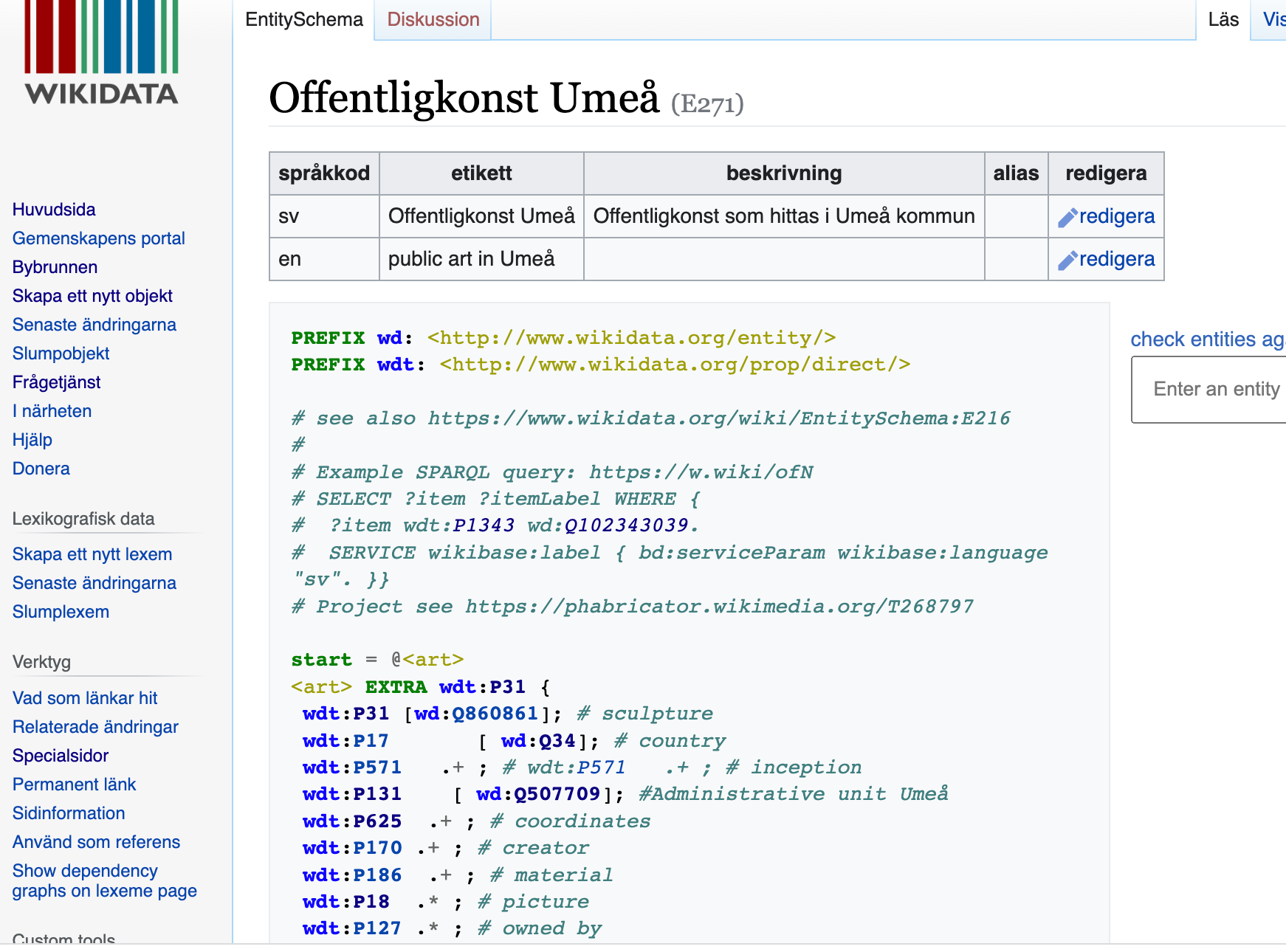
- mervärde med Wikipedia ?!?!? Många kollar där och Google gillar ännu WIkipedia
- Exempelvis MOMA i New York länkar tillbaka till WIkipedia/Wikidata varför inte Ume
- Wikipedia har idag om Umeå kommun och skulpturer
- Lista över offentlig konst i Umeå kommun --> dvs. du hittar var och kan läsa vidare...
- artikel om era konstnärer finns på flera språk 16 språk i Wikipedia och engelsk Wikipedia har artikel om > 10 av konstnärerna (lista)
- Exempelvis MOMA i New York länkar tillbaka till WIkipedia/Wikidata varför inte Ume
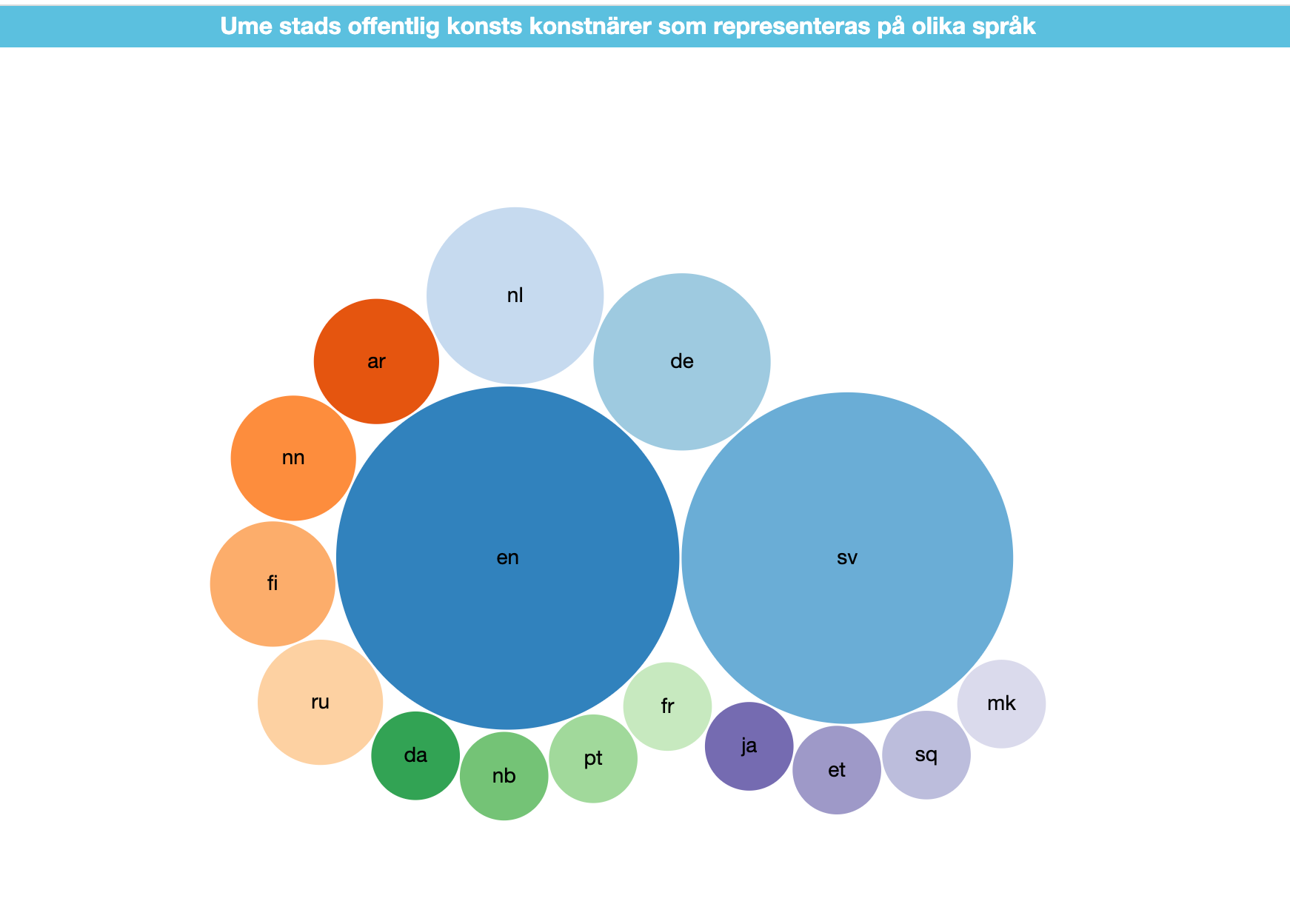
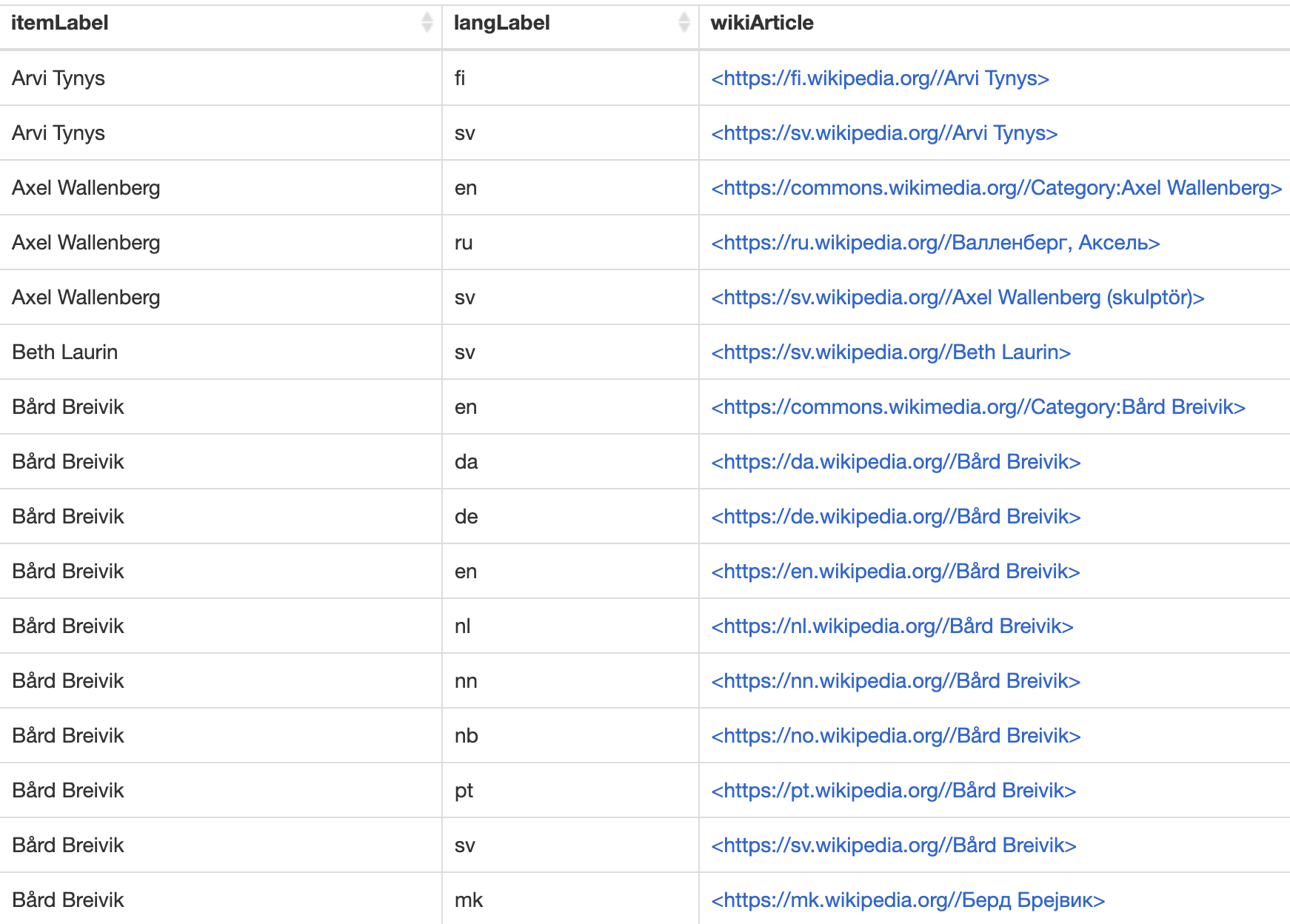
Det intressanta är inte konstnärer utan att ha data som data.
Kolla på NOSAD "Öppna data för ett hållbart godstransportsystem" då Christian Landgren var med där han presenterar hur tvillingstäder kan simuleras. där drönare används för att leverera...
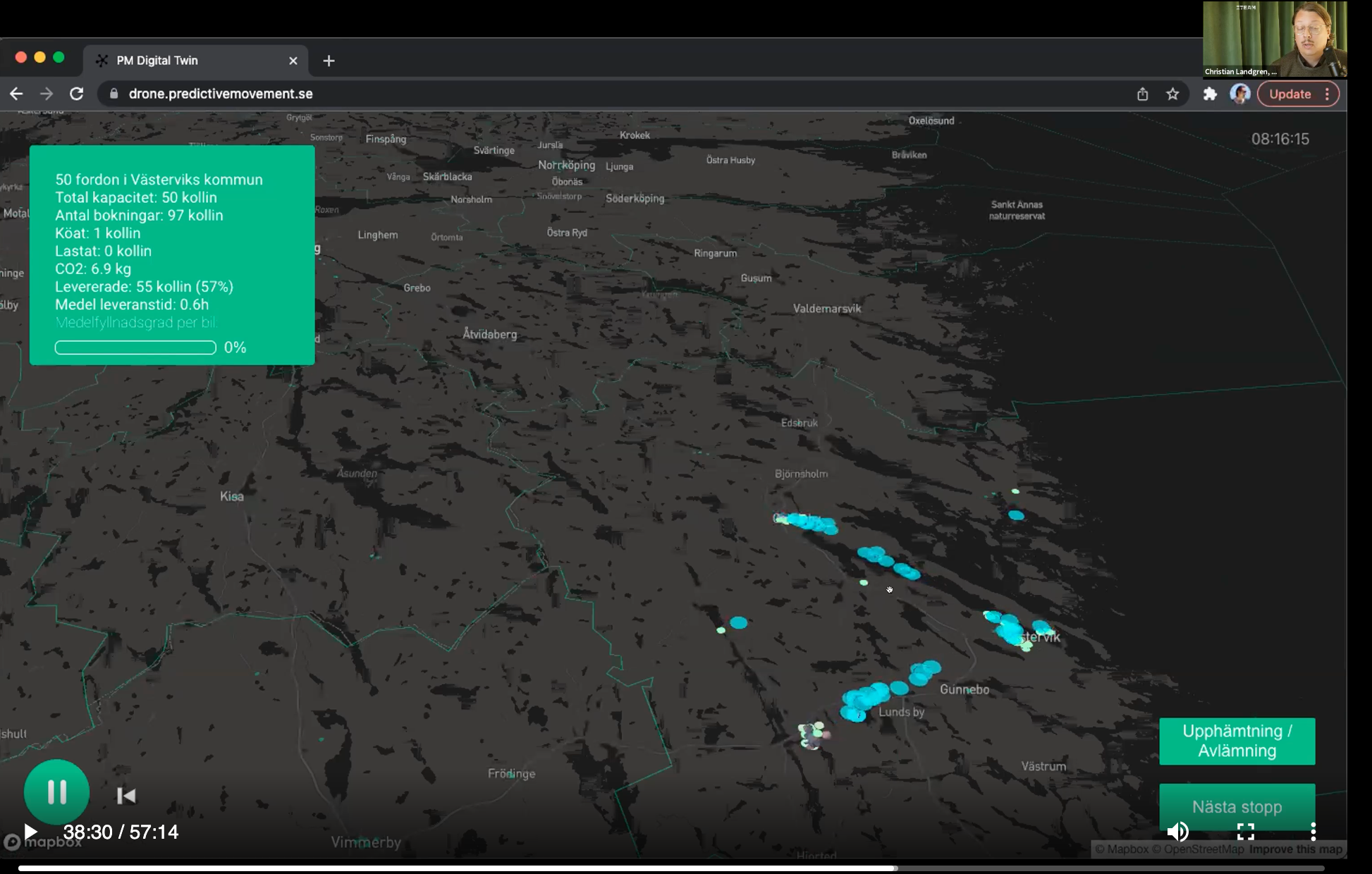
med mer data som data och data som är 5-star data så kommer nya saker att kunna ske... 5-stardata innebär det @jonor pratar om att man kopplar ihop det med en kunskapsgraf "Why Government Websites Need a Knowledge Graph"
- dagens Öppna data SILOS utan publika backlogs känns lite som Moses stentavlor ...
- fundera över om vi hade banker som inte kunde prata med varandra för att deras data var en SILO ?!?!?
- när jag var scrummaster på SEB prata man om att i Tyskland heter det "Garage clearing" eftersom värdepapper utbyttes historiskt av att två bankmän från olika banker möttes i ett garage med en portfölj och bytte värdepapper.... påminner lite om var vi är idag med Öppna data (rätta mig om jag har fel)
- fundera över om vi hade banker som inte kunde prata med varandra för att deras data var en SILO ?!?!?

Bättre kan vi !!!!
- jämföra olika städers skolmåltider map koldioxidutsläpp
- kan maten påverka hur eleverna presterar i skolan
- kan mat som serveras i vår kommun bli bättre med avseende på matsvinn per skola
- vad gör andra kommuner med lika mycket matsvinn som vi har
- vilka skolor i kommunen jobbar aktivt med en fråga kan andra kommuner se och lära....
- vad gör andra kommuner med lika mycket matsvinn som vi har
Mina utegym, badplatser eller skulpturer är bara enkla data som mer tar pulsen på om data som data kan levereras... att börja bli data drivna då är det en helt annan nivå av datamognad...
- koppla samma som
-
Detta inlägg är raderat!
-
Bättre sökfråga som visar Wikipedia artiklar på flera språk för konstnärer som finns som offentlig konst i Umeå
Samma men visar detta på en karta med bild på statyn om det finns....
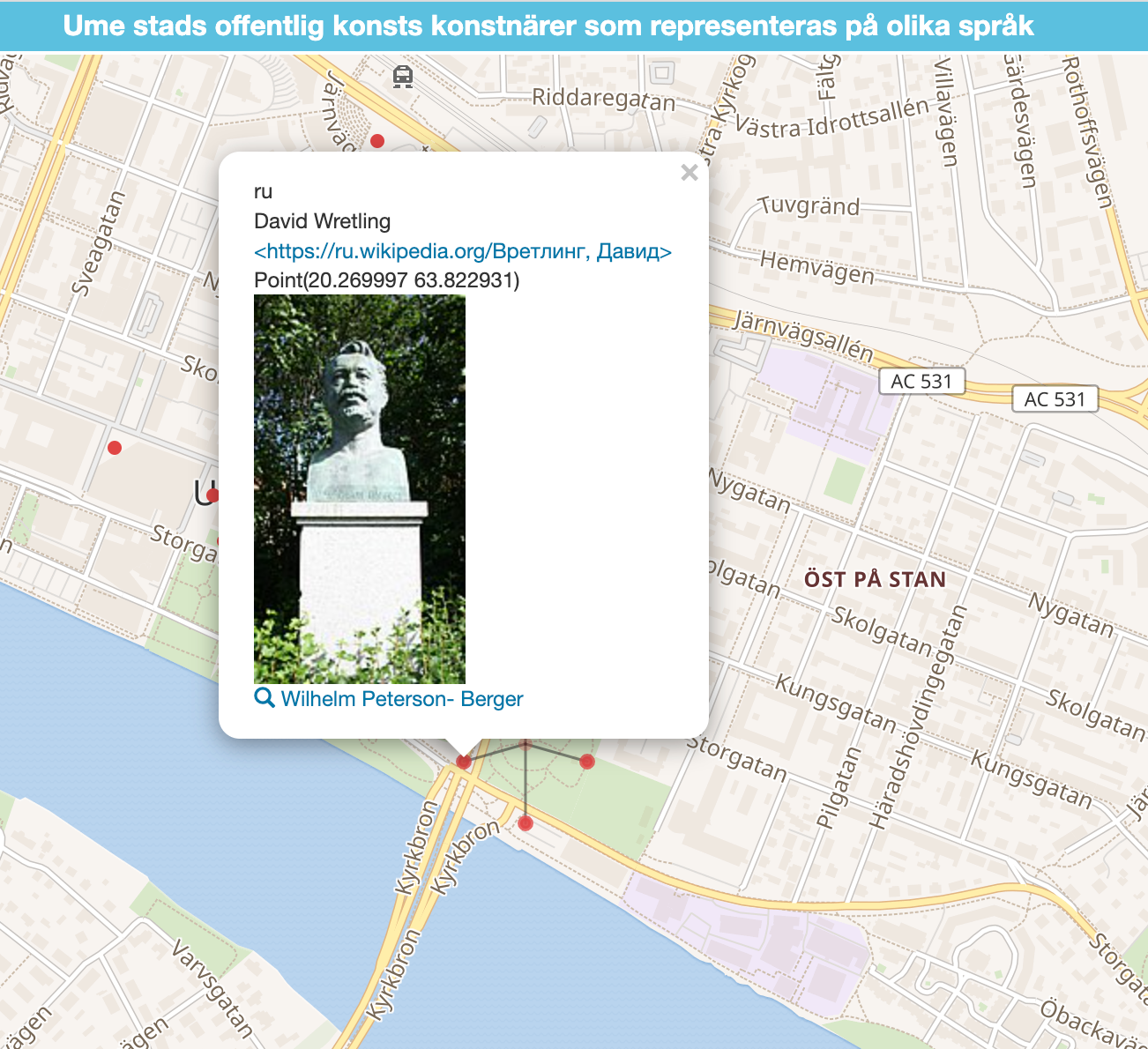
Hela detta med Öppna data är en resa som är enormt krokig,....
När det gäller just offentlig konst som dialogen ovan med Maria handlar om så samlade Wikipedia Sverige in var dessa skulpturer finns för hand pga. brist av Öppna data detta slutade med 750 000 böter och dom i högsta domstolen .... tror ingen såg denna komma.... lesson learned var agila
-
@Maria_Dalhage det problem vi ser på Wikidata är
- att data har fel
- att institutioner är mer eller mindre mogna att ha helpdesk, ge oss helpdeskid...
- exempel i ett > 100 miljoner Euro projekt Europeana tog det 2 år innan jag fick ett helpdesk nummer
Skall data användas så måste det finnas ändringscykler som jag som konsument litar på....
Försök till "lösning" av detta mismatch problem
- Wikidata bygger ett eget system - Wikidata:Mismatch_Finder - GITHUB

Jag tror en bra dataportal för Svensk Öppen data skall ha denna funktion att enkelt kunna felrapportera data på post nivå och version av datat och enskilt data..... dagens kommuner etc... klarar inte av detta....- exempel
** Södertälje kommun rapporterar skolor som textsträngar med matavfall. Önskar skola samma som skolenhetsregistret
** Södertälje rapporterade Naturreservat utan kopplingar Fixat
** Umeå kommun har konstnär men inte samma som extern auktoritet
** osv. osv.
Ingen vill ha dålig data
Disclaimer Wikidata har inte startat använda detta verktyg ännu..... finns kanske bättre...
-
@Maria-Söderlind och @Maria-Söderlind, jag förstår att @Magnus-Sälgö inlägg kan kännas svåra att ta till sig eftersom de alltid är lite spretiga med okompletta meningar och har många bilder och punktlistor och upplevs vara för fokuserade på annat (andra myndigheter som gör fel, wikipedia och wikidata). Jag har läst och fattat vad han skriver och jag tänker att jag ska försöka mig på ett annat grepp för att förklara andemeningen.
De 2 stora poängerna som jag ser kan förklaras på detta sätt:
- Alla grepp ni tar för att inkrementellt förbättra anser Magnus är bortkastade eftersom ni inte tänker om arkitekturen.
- Magnus menar inte att ni ska lägga tiden på att länka till wikipedia själva utan vara smarta med hur ni specar datan och hur den publiceras så att rättningar kan införas enkelt istället för svårt.
Sättet att ta sig dit kan vara t.ex. dessa:
- Läsa på om 5-star open data
- Ta en genväg genom att använda er av wikidatas stora register av "samma som" istället för att börja från scratch.
- Se till att ha beständiga unika identifierar för allting.
- Bygg en ny data-plattform som bygger på triplett-idén och definiera upp lämpliga tripletter. Det är otroligt kraftfullt!
Visionen
Det @Magnus-Sälgö försöker påskina är inte att hacka ned på er eller vara en klagans person. Utan visa på att visionen är fel. Han älskar att ni publicerar data men önskar att ni 2022 har kommit så mycket längre i att länka samman data och behandla data som data.
Visionen bör alltså vara att istället för att prata om enskilda funktioner som tar lång tid att bygga och som ni kanske inte prioriterar, bygga ett system som låter alla engagerade användare med lätthet förbättra datakvaliteten till höger och vänster.
Om ni är fast i att förbättra portalen istället för att bygga om
Tips: Fundera på hur ni löser länkningen och visualisering av länkning. Låt forumet vara sitt egna system. Skapa inte en till diskussionsplats i form av kommentarer där man ska uppfinna trådning, formatering med mera igen, det är ju redan gjort i communityt.Ni kanske kan börja och ta er till 4-stjärnig data genom att:
- publicera alla datamängder, datamängdsgrupper, organisationer och organisationsgrupper i dataportalen i listor(i JSON såklart) på dataportalen.
- lägg till ett fält i forumets trådskapande del som är "Handlar om" som gör uppslag i datamängder, organisationer och grupper av datamängder eller organisationer från dataportalen. Detta fält ska naturligtvis referera till id't som objektet har i dataportalen.
- Länka från forumet till dataportalen i varje tråd med "HANDLAR OM [datapublikation]" och exponera listor per datamängd och organisation ifrån forumet så att ni i dataportalen kan fråga efter trådar som:
- handlar om datamängden
- handlar om organisationen
- handlar om datamängdsgruppen
- handlar om organisationsgruppen
Då kan ni länka från datamängdens sida till relevanta trådar på forumet — i de olika grupper av inlägg som är intressanta och relevanta för datamängden
Ni bör kunna skapa en knapp som säger diskutera datamängden på communityt som länkar användaren vidare till en trådskapande del med datamängden förvald i det nya fältet
Om ni kan tänka er att bygga om dataportalen
Då skulle jag föreslå något i denna stil. Där man drar nytta av triplett-tänket som wikidata pionjärat
Använd dessa tekniker som backend:
- En Wikidata som metadata-lagring i dess SparQL
- En självhostad gitlab där grunddatan publiceras. Varje organisation eller organisationsgrupp publicerar sina fasta data i ett repo, när datan uppdateras så blir det en commit och ändringarna är spårbara,
- Har man strömmande data så behöver den i sig såklart inte publiceras på gitlab utan accessvägarna beskrivas i repot's README istället.
- Samma frontend som idag, men som ställer frågor mot SparQL istället
- Låt frontenden få ett publikt "redigera"-läge som länkar små redigera-knappar till data entiteten i wikidatan istället.
- Låt SparQL-fråge-systemet vara publikt tillgängligt
Modellmässigt så borde t.ex. dessa entiteter skapas som items (Q-värden)
- Datamängd
- Organisation
Modellmässigt så borde t.ex. dessa entiteter skapas som egenskaper (P-värden)
- Publicerad av
Då kan vi t.ex. utrycka tripletten:
- Q"Sysselsatta efter utbildningstidens längd och näringsgren. År 1999 - 2003" är P"Publicerad av" Q"SCB" - Q"Sysselsatta efter utbildningstidens längd och näringsgren. År 1999 - 2003" är en (is_a) Q"Datamängd" - Q"SCB" är en (is_a) Q"Organisation"Helt plötsligt kan vi då ställa SparQL-frågor som:
? P"Publicerad av" Q"SCB" ? is_a Q"Datamängd"Och få tillbaka alla entiteter som är datamängder och publicerade av SCB.
Här sätter bara fantasin gränserna!Effekterna
- Vi kan ställa godtyckliga frågor om datamängden som är sveriges dataportals datamängdsmetadata.
- Vi kan definiera godtycklig metadata om datamängderna och snabbt bygga ut funktionaliteten
- Vi får beständiga identifierare till datamängderna (Q-värden och commit-hashar på gitlab)
- Vi får beständiga identifierare till den transparenta helpdesk-funktionaliteten på gitlab.
- Varje datamängd har en egen helpdesk på gitlab
- Alla kan skapa en PR/CR(pull request/change request/ändringsbegäran) och peka på exakt vad som är fel i en fast datamängd direkt på gitlabben. Rättningen är då en knapptryckning bort.
- Och många många fler.
Slutligen:
- Har jag tolkat dig rätt @Magnus-Sälgö?
- Vart det begripligt @Maria-Söderlind och @Maria_Dalhage?
- Om ni inte klarar av det, speca gärna "Förlsag till hur en '5-star open data-länkad dataportal baserad på öppen källkod och byggd öppet med öppen källkod, som är användarvänlig och tillåter en öppen diskussion och beständiga identifierare' kan byggas" i en DIS så kommer det komma bolag till er undsättning.
-
 S Stefan Wallin referenced this topic on
S Stefan Wallin referenced this topic on
-
@Stefan-Wallin mer än rätt tycker du pekar framåt bara att installera en wiki skulle kunna göra att vi har platser att jobba ihop på även fast det är ett enkelt verktyg fungerar det fantastiskt bra på WIkidata/ Wikipedia
- 5-star data är grunden att lyckas
Känner att jag ser alltför många projekt utan publika projektytor utan man försöker dela på Linked in med begränsningar på 1000 tecken.... finns en Wiki hos DIGG (och kanske en GITHUB clone) hos DIGG så finns ingen ursäkt....för mig känns det till exempel helt galet att Vinnova producerar en PDF om datadelning och det verkar inte finnas några digitala spår... jag saknar att dom
- delar data som data, har en publik projekt yta, inga diskussionsgrupper eller hur man tar kontakt med folk, eller att det finns sparade inspelningar av den enda aktivitet jag hittat "Hearing om datadelning"
- resultatet verkar vara att starta nya projekt hos Vinnova....
- jag klara inte av att hitta spår i deras API:er
- lika galet att uppdraget presenteras utan en projektyta hos regering.se där man kan hitta projektet, kontaktpersoner eller resultat.... känns som det finns en kontaktskräck
den här diskussionsgruppen där man kan redigera sina inlägg enbart i 10 minuter är ett litet steg.... en wiki är mer jobba ihop och det finns versionshistorik etc,..,. eller varför inte en wiki per identifierade grunddata inom den offentliga förvaltningen...
Exempel hur en WIki kan användas
-
vad @Ainali gjort
- Wikidata:WikiProject_Sweden/Swedish_Riksdag_documents motioner/betänkande/utredningar/SFS...
- samma måste göras för motsvarande dokument från kommunerna sedan skall dessa dokument kopplas till Agenda 2030/ SDG
- liknande projekt men för alla politiker i hela världen
- OT GITHUB repositories där > 200 kopplingar finns till olika parlament, exempel svenska parlamentets data jämförs vad som ändrats
- liknande projekt men för alla världens administrativa indelningar
- alla världens myndigheter - Wikidata:WikiProject Govdirectory
- Wikidata:WikiProject_Sweden/Swedish_Riksdag_documents motioner/betänkande/utredningar/SFS...
-
- Högsta domstolens beslut
- snygg koppling vilka som utreder underlag och vem som dömer i HD se tweet
- Högsta domstolens beslut
-
jag har skapat eller är del av
- försök att samla ihop Sveriges kommungubbar
- Fredmans epistlar
- Badplatser
- Utegym
- Runstenar i Sverige
- Svenska Akademin
- Svenska Litteraturbanken
- .... SBL, SKBL, Nobelpris vinnare
Andra projekt med koppling Sverige
-
@magnus-sälgö Snyggt! Bra sammanställning av goda exempel.
Du skriver " ..bara att installera en wiki skulle kunna göra att vi har platser att jobba ihop på även fast det är ett enkelt verktyg fungerar det fantastiskt bra på WIkidata/ Wikipedia."
Det finns en vilja hos från civilsamhället att samarbeta och hjälpa myndigheter och kommuner i deras jobb. Goda intentioner som offentlig sektor ibland har svårt att möta. Och det beror ju på ovana. Många individer (privata som offentliga-aktörer) är ovana med publika diskussioner. Det man eftersträvar är ju att arbeta öppet och smart (för att effektivisera och vara med transparent), men för många finns en oro att den publika dialogen blir för omfattande och tidskrävande och ytterligare en aktivitet. (Och ibland är det så.)
Att något är svårt betyder inte att vi inte ska försöka, och här har vi helt klart en hel del att lära från Wikidatavärlden.
-
@Maria_Dalhage egentligen är det bara att skapa en yta på Wikidata.... och "vara med" samma med GITHUB ... numera är även gratis gott
Snart kommer en Wikibase.cloud som är en gratis "tom" Wikidata hostad i molnet ex. min betatest
blir för omfattande och tidskrävande
Att leverera 5-star data tycker jag skall jämställas med att börja med Maskininlärning det tar tid och ny kompetens/ekosystem behövs... och vi kommer att göra fel vilket Johan Magnusson poängterar är en del av processen.
blir ... tidskrävande
Vore intressant om projekt som NSÖD var mer öppna med var resurserna lagts på (att själva ha öppna data) och sedan kunna börja jämföra hur man själv jobbar och om det är det mest effektiva...
Hade hoppats att min en vecka med badstränder/utegym skulle skapat intresse av fördelar med ett verktyg som Wikidata...

-
@Stefan-Wallin Jag utgår ifrån att en stor del av ditt inlägg inte var menat till mig utan en annan Maria?
Kan bara påpeka att uppdatera vår öppna data behöver inte ta lång tid, som jag sa tidigare är anledningen till att det gör det ibland att det kommer längre ner i prioriteringen beroende på vilken data/verksamhet det handlar om (samt vilken arbetsbelastning/resurstillgång de har) -
@Maria-Söderlind delvis även dig, framförallt din kommentar om:
Att kommunerna ska lägga resurser på att koppla ihop sitt öppna data med WD - känns det verkligen korrekt? Är det verkligen detta de kommunala pengarna ska läggas på?
Vad jag ville kommunicera, men kanske missade att tydliggöra. Är att det inte alltid måste vara Wikidata som organisation offentlig sektor(ni?) ska samarbeta med och lägga tid på, utan att ni kan skapa er egna Wikidata och webbbaserade Git-repon när ni publicerar data och därmed enkelt och strukturerat kunna ta emot feedback, rättningar OCH HJÄLP från engagerade medborgare. Därmed skulle ni slippa göra allt jobb själva och istället utnyttja kraften i Crowdsourcing. Superbra framförallt när det gäller alla sorters kartdata eller kart-knuten data som representeras av fysiska ting i vår omvärld(bad, gym, skolor, skolmåltider med mera kan alla ses som kartdata). Men just ihopkopplingen som wikidata är så bra på är något offentlig sektor behöver bli mycket bättre på. Här menar Magnus och jag att en genväg ni kan ta är att använda en wiki som bassystem istället för att uppfinna egna som kostar dyrbar utvecklingstid och långa inköpsprocesser.
Så istället för att lägga tid på att koppla ihop egen data med Wikidata så kan ni ge medborgarna verktyg för:
- att skapa SammaSom-kopplingar som ni kan godkänna med en knapptryckning
- att använda riktiga persistenta unika identifierare som kan kopplas mot externt
- att använda existerande öppen källkods-mjukvaror för helpdesk-ärenden med egna persistenta identifierare. Dessa ärenden bör kunna vara helt publika och transparenta. Inspireras gärna av Github/Gitlab eller använd en egenhostad Gitlab för ändamålet.
Här @Maria_Dalhage kan DIGG ta ledartröjan och tillhandahålla mjukvaran där resterande offentlig sektor kan bjudas in och agera. Skapa primära offentliga kontaktvägar och rekommenderade metoder.
-
Andra som sliter med hur man skall jobba ihop och skapa användbar metadata är kulturarvet se Facebook dom har en workshop om detta 17 oktober....
Skillnaden är att utan bra metadata stannar forskningen... dvs. så borde det vara för kommuner att andra kommuner använder det metadata som producerar av deras "tvilling kommuner etc..." men där är vi inte idag... varför...
Gissar att dom försökt i 400 år så det verkar ta tid....
 eller så kan man lära av deras misstag... jag tycker EU projektet Europeana är exempel på 10 års misslyckande det jag ser
eller så kan man lära av deras misstag... jag tycker EU projektet Europeana är exempel på 10 års misslyckande det jag ser- SILOS
- finns sällan på GITHUB eller ger dig ett helpdesk nummer
- verkar ha svårt att anställa nya kompetenser... Spotify har 70 000 ansökningar per månad / Riksarkivet får knappt några sökande på utlösta ITjobb har jag hört...
- brist på standarder hur data beskrivs exempelvis yrken, alla uppfinner sin egen
- Riksarkivet SBL har enormt bra domänkunskap men publicerar inte data som data dvs. metadata... SKBL som också skrev biografier var digitala, hade API och producerade 50 kvinnobiografier per månad medans SBL skapa 5 per år.... se Notebook
- saknas publika backlogs / roadmaps dvs. det är svårt att se vart arkiven etc. är på väg
- det @Stefan-Wallin pratar om att ha korta 3 veckors sprintar har jag inte sett utan man får något efter 4 år.... och kan inte enkelt kommunicera med dom...
- SILOS
-
@Maria-Söderlind min kanske naiva tro är att man bör tänka API first dvs. när du bygger en web så börja med att skapa data som data inte ens DIGG som starta för 3 år sedan och skall vara experter verkar ha tänkt så utan det blev mer webdesign och snygga bilder --> att deras författningar etc. inte finns som Öppna data utan bara på en websida.... (1999 fanns en ambition att skapa öppna data i projektet lagrummet av alla författningssamlingar men man la ned projektet kring 2006 och det blev en websida med länkar känns som behovet av rätt kompetens underskattas hela tiden... )
det kommer längre ner i prioriteringen
med APIFirst så kommer tom Öppna data först sedan websida.... Tim Berners Lee som skapade www säger detta i denna video "raw data now" .... han pratar även om Hans Roslings begrepp database hugging

Tyvärr ser jag att några av dom få Öppna data lösningar jag hittat hos kommunerna bygger på att datat som visas på web:en inte direkt skickas över till Öppna data --> felstavningar, ändringar syns inte samtidigt vilket jag tror att öppna data gärna "glöms bort"
Kan Facebook lura apoteken att samla in data till dom vilka läkemedel vi användare köper och koppla det till person borde övriga samhället komma längre med det digitala är min tes....
-
@Magnus-Sälgö Håller helt med om att Öppna data tyvärr inte är prio ett i kommunerna och driver själv argumentet att allt som ligger på vår publika webbsida direkt borde kunna speglas till öppna data. Vi har api'er till all vår öppna data, inser dock att det inte är dessa api'er som du syfter till. Mycket av vår data är tyvärr inlåsta i system som vi ibland själva har svårt att få åtkomst till. Detta förhindrar vi numera genom att i alla upphandlingar kravställa att det ska finnas apier så vi kommer åt datan. I de allra flesta fall har vi apier som matar vår portal med data. Dessa apier ligger dock innanför våra brandväggar så de utanför organisationen kommer aldrig att få åtkomst till dessa. Men det behövs ju inte så länge vi har samma "masterdata" innanför som utanför brandväggen.
Vi håller långsamt, jag vet :), på att bygga upp en informationsstruktur/arkitektur som håller i längden för vår data. Men det tar tid och vi vill inte att det ska vara ett hinder för att kunna dela öppna data under resans gång. Så ibland blir det data med dålig kvalité, men å andra sidan så betyder det ju att vi då har data med dålig kvalité och vi är öppna med det.
@Stefan-Wallin vi kikar just nu på funktionalitet som ger möjlighet att ge feedback direkt på en datamängd. Är dock osäker på om det finns en publik vy för den, men ska definitivt kontrollera/önska det.