Community på Sveriges dataportal
Some open source products ESV's datalab uses to innovate with AI
-
Hi everyone,
At ESV's datalab, we work a lot with AI and we try to be as open as possible about the outcome of our projects. A lot of them are web applications which are made available to everyone on our website: datalabb.esv.se. In some cases, we publish the results and lessons learnt as reports. I'm also hopeful we'll be able to publish more and more of our code in the future.
In the meantime, I thought I'd publish a short post on this forum to talk about some of the open source tech we use in our projects. My hope is that you find something interesting and if you already are using one of these tools, don't hesitate to contribute to the discussion below. I also added the tools to the amazing list at offentligkod.se.

LLM
More and more of our projects revolve around the use of large language models (LLM) so I'll start with that. Our first real project last year was called Fråga GPT (report) and based on OpenAI's models GPT-3.5 and GPT-4.
Since then, the competition has increased and even though we still use GPT-4 a lot, we routinely use Claude, Mistral, Llama2/3 and many others.
Langchain
In order to make it easier to switch, we've been using Langchain, a Python framework that lets you call a large number of APIs with reusable components. You can in theory write a single pipeline and switch the underlying model.
from langchain_openai import ChatOpenAI from langchain_community.chat_models import ChatOllama prompt = "Find the information in this document: {{ document }}." cloud_llm = ChatOpenAI(model="gpt-4") cloud_answer = cloud_llm.invoke(prompt) local_llm = ChatOllama(model="llama3") local_answer = local_llm.invoke(prompt)In practice, this can prove harder as LLM products don't have the same function set (some have a JSON mode, function calling, others don't) and specific instructions are often required to optimise for each model.
Still, a toolbox that abstracts the complexity of connecting to various providers if very useful! We've also been testing tools such as instructor, guidance or lmql in order to get more control on the output text but we are not using them yet in our projects.
LlamaIndex
We mainly use LlamaIndex to build RAG pipelines. RAG (retrieval augmented generation) is the process of providing relevant context to a large language model so it can answer a question better. We are for instance building an assistant able to browse legislation and a large number of work documents to answer questions about them.
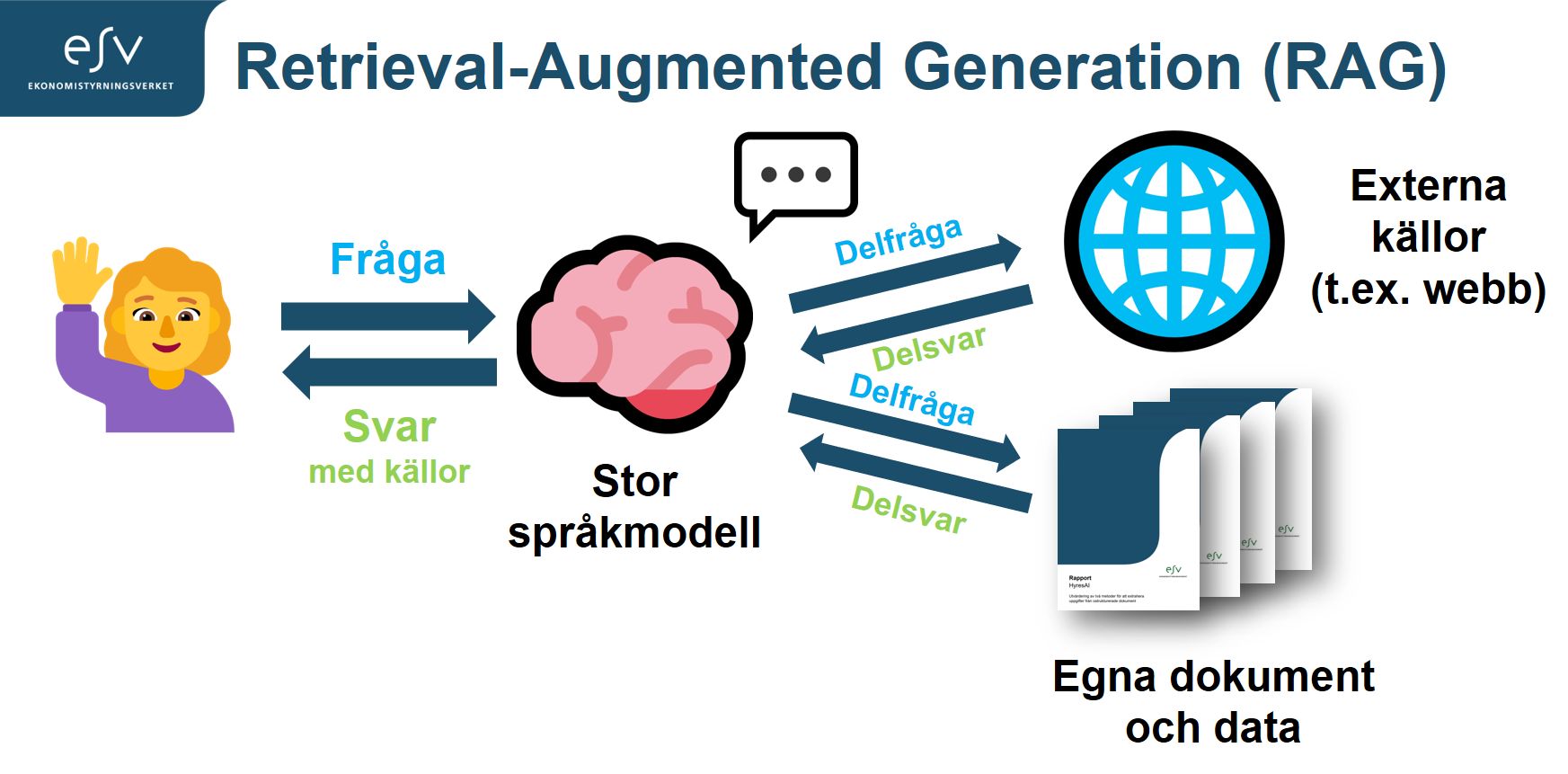
LlamaIndex is helpful and abstracts a lot of the underlying logic but it can also be hard to understand how things work. In order to improve performance, we translated the built-in prompts to Swedish. Just like many other tools in this field, the edges are still a bit rough.
Local models
Ollama

In order to run local models, we use Ollama. It's very simple to deploy new models and Ollama's API can be plugged into most systems, including the two mentioned above. When Llama3 came out a few weeks ago, we were running it on our local workstation half an hour later.
There are alternatives such as vLLM, LiteLLM and LocalAI and we might switch to one of them for production (or even bare transformers or llama.cpp for inference) but Ollama is hard to beat for simplicity and quick testing.
UI
For several projects (including FrågaGPT and our current RAG project), we developed our own simple UIs. Mostly because there were still few products available when we started and we wanted to build in robust feedback features to let users evaluate the results. We are currently trying open source UIs that are ready to deploy and that we can plug our various models onto. In the future, we will probably either integrate AI features in our work tools or use ready-made UIs such as the ones we're testing now. But there are new solutions popping up every week so it's hard to keep track of which ones are best. Here's some of the ones we tried:
Open WebUI
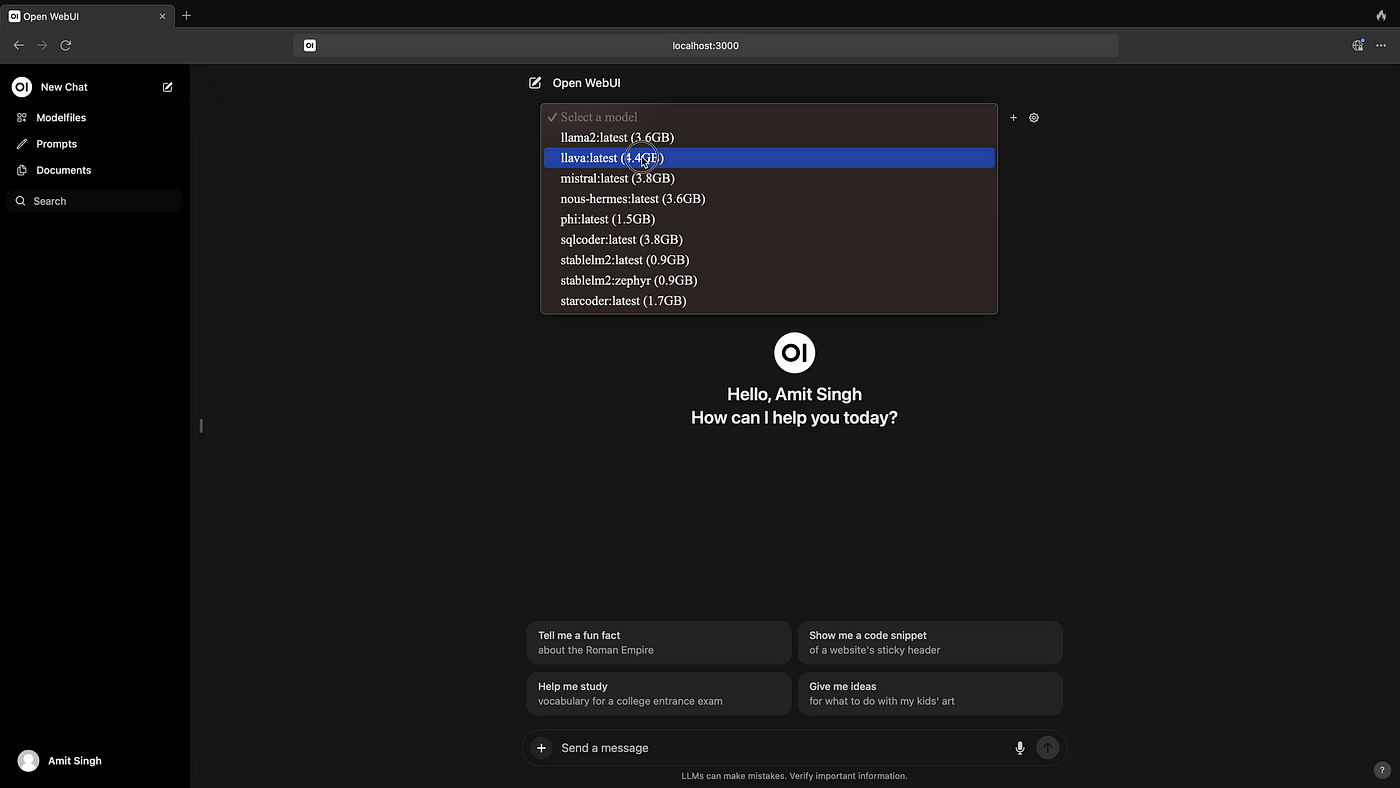
Open WebUI is a typical clone of ChatGPT and we plug it on top of Ollama so we can test local models: Llama 2/3, Mistral, Mixtral, Phi... In addition to basic features, it is possible to save assistants with a custom instruction (much like OpenAI's GPTs), to upload documents that assistants use in their answers and to have several models answer the same question simultaneously (for easy comparison). Some other basic features that are useful for us is an admin panel with user management and evaluation features for each answer. The conversations and feedback can be exported as JSON for analysis.
AnythingLLM
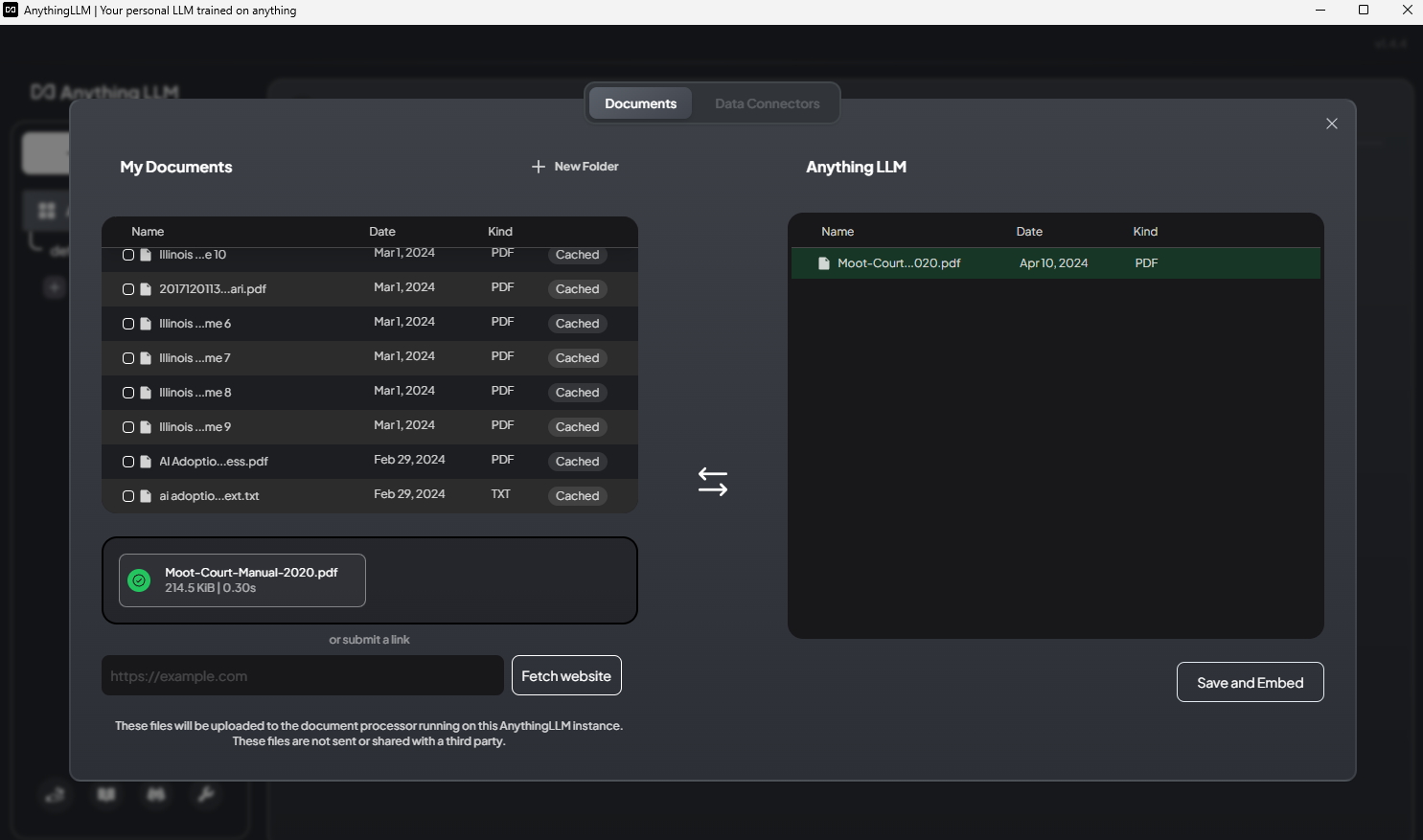
AnythingLLM is very similar. It also has good user rights management. It can be plugged to our local models on Ollama as well as all major cloud LLM providers (OpenAI, Anthropic, Mistral...). The UI looks promising for its RAG capabilities as it makes it easy to import a large number of documents and to create "workspaces" accessing them. But it's unclear whether the quality of the retrieval is good enough and whether it's possible to tweak the RAG pipeline to optimise it.
Flowise
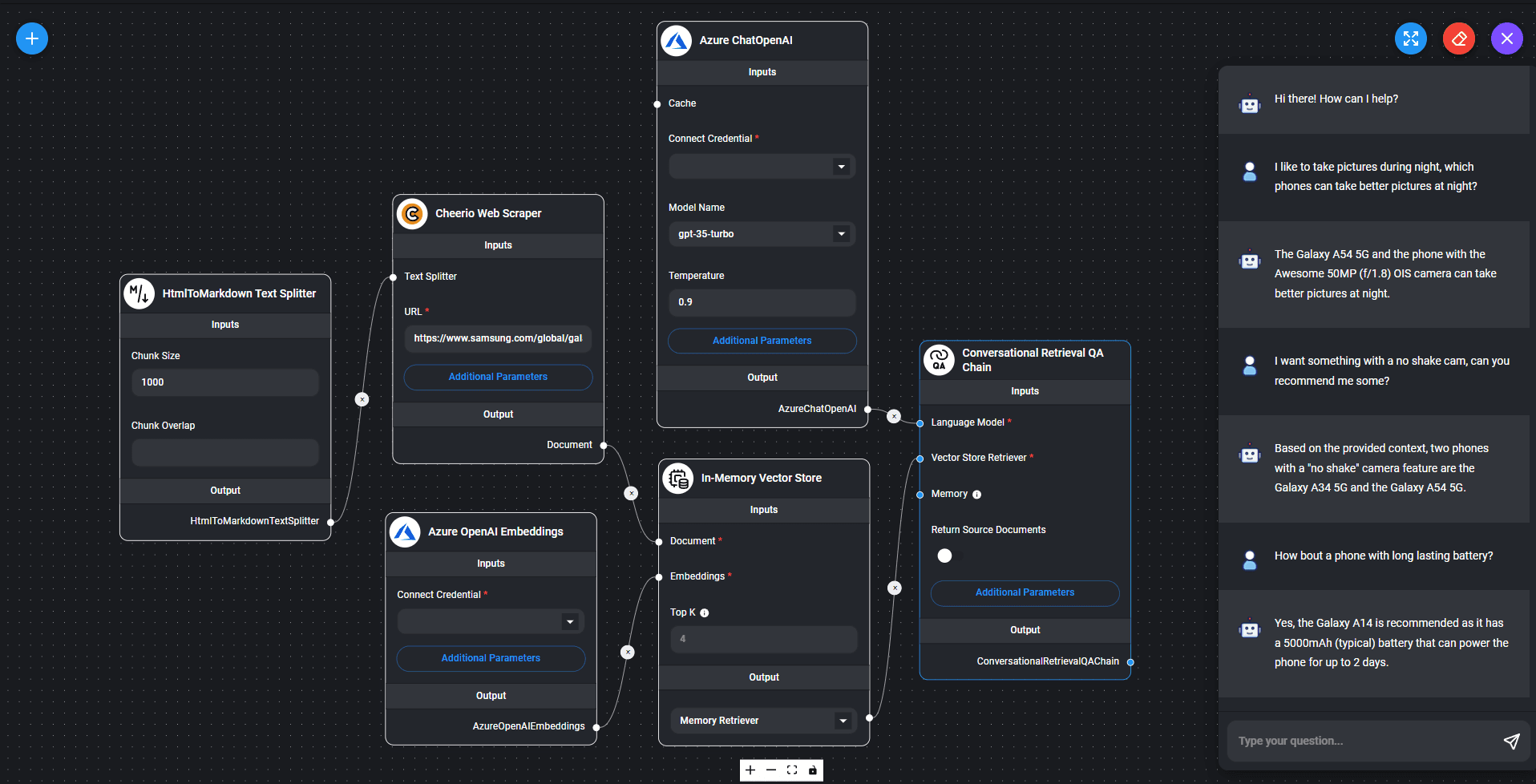
Flowise is more advanced than the others and doesn't work out of the box. It's more of an orchestration tool where you assemble blocks to connect data sources, prompt templates, output parsers and LLM APIs, all in a drag-and-drop interface. It's a promising complement to LlamaIndex in that it theoretically could let collaborators at ESV build and test their own pipelines without coding a single line. If the results are interesting, we could then build a more elaborate system with robust quality control. We know of at least one of example of Flowise use in the Swedish public sector: one of the winning teams at last eSam's hackathon used it to build its prototype.
Flowise has some competitors that we didn't test: dify and Langflow.
We're very curious to hear what other Swedish government agencies are using. I recently saw that Skolverket was preparing to roll out an assistant to its coworkers that builds on LibreChat.
Programming
Continue
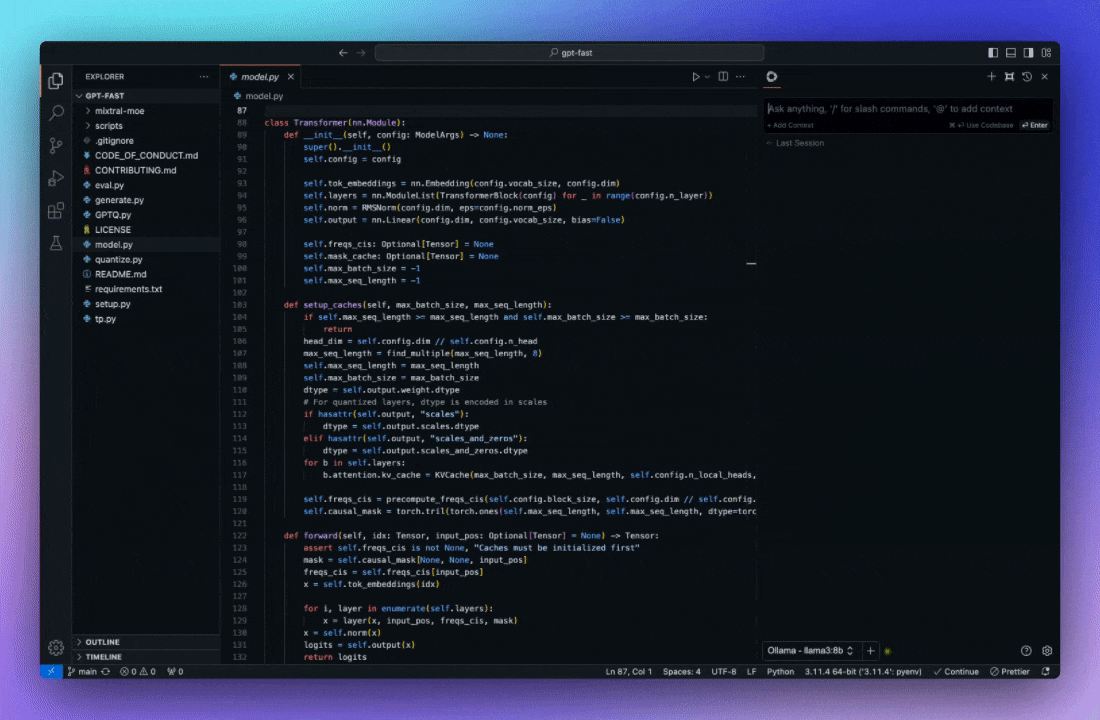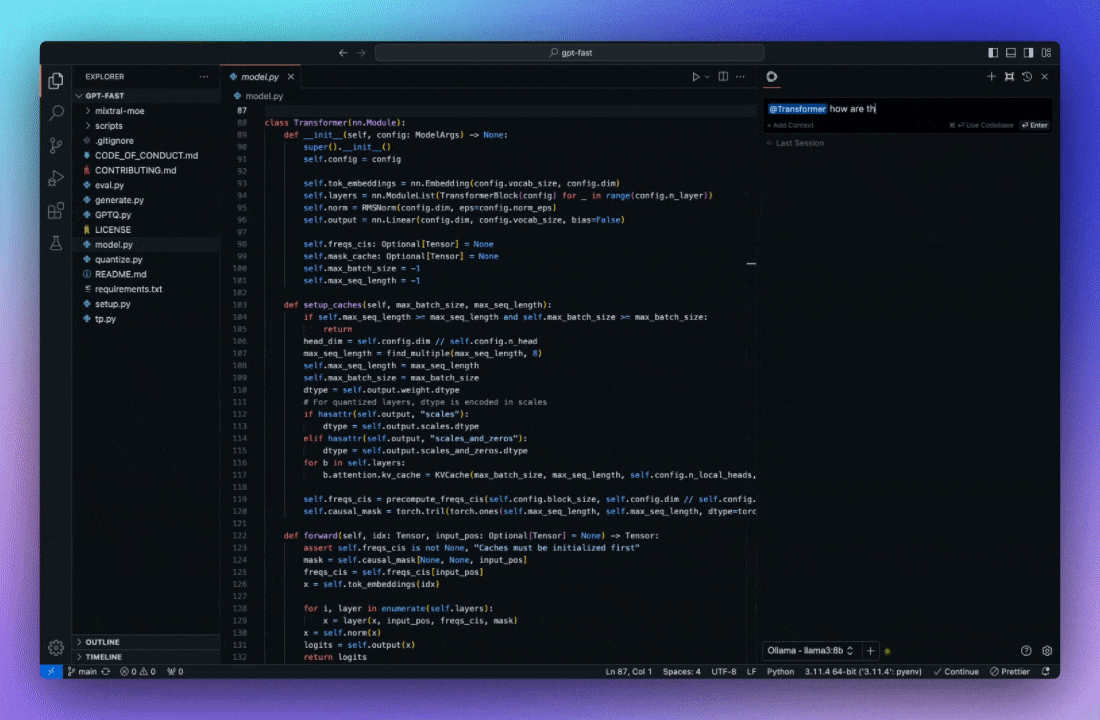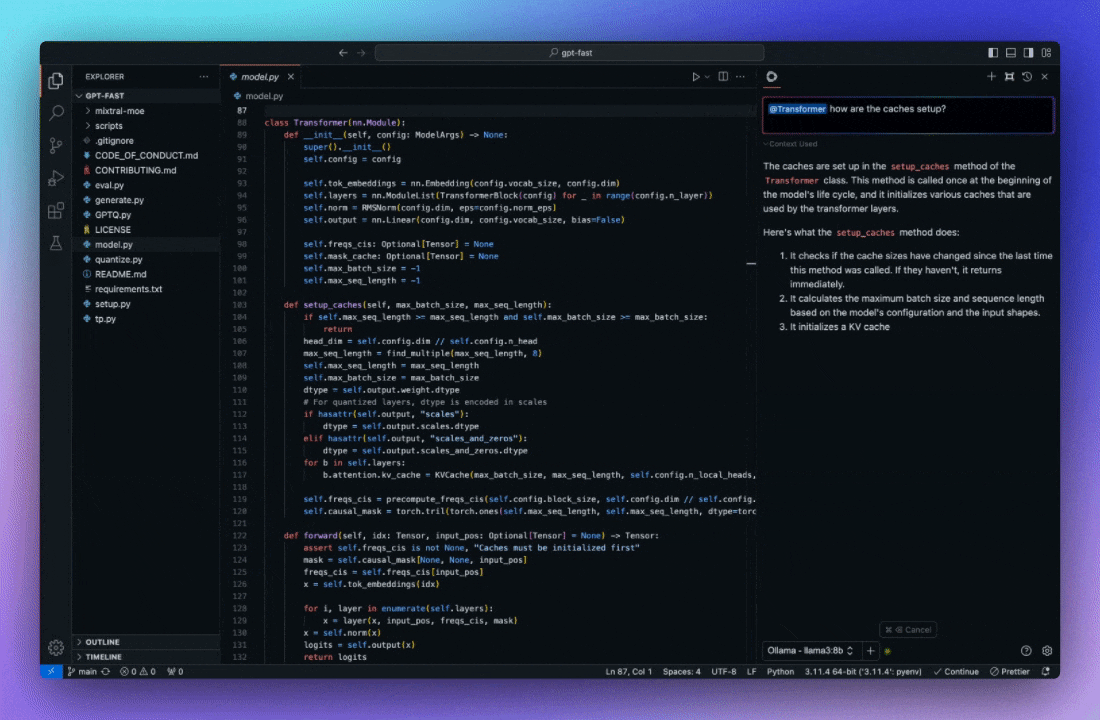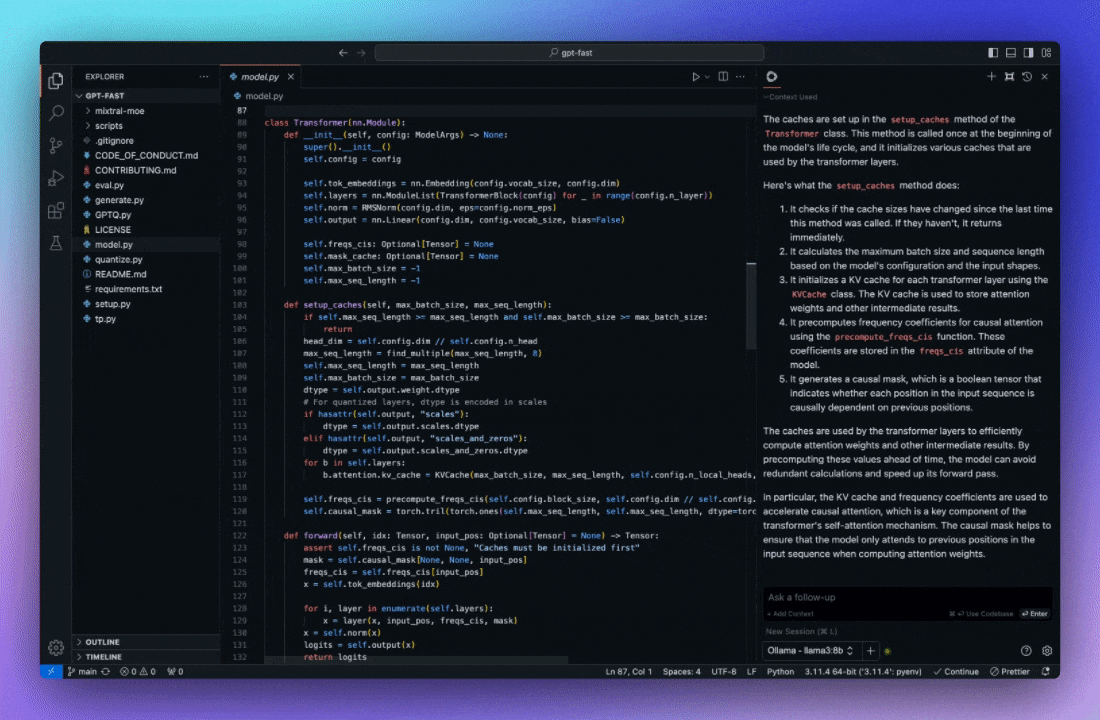
As a side track, we've also been testing alternatives to Github Copilot to assist in coding. We first tried Tabby that could auto-complete or suggest whole blocks but the results weren't good enough to make us adopt it. Since April, we are testing Continue and I am much more impressed by its potential.
Functionally, Continue integrates in your IDE (VSCode or JetBrains) and is available as an assistant that has indexed your project's code. You can have a conversation with the assistant and quickly point to some parts of the code in order to debug or improve them. It can then suggest new code that can be reviewed before being integrated. It can also auto-complete whole blocks like Tabby.
Continue integrates with Ollama so we have 5-6 models there that we have been trying. For autocomplete, a small one like starcoder2:3b provides new code almost instantly. For conversation, codellama:7b and deepseek-llm:7b work great and we can hope that the next CodeLlama based on Llama3 will be even more convincing.
Unfortunately, Continue isn't available for Visual Studio 2022, which a majority of our agency's developers use. But I'm hopeful the same sort of tools will come and we recently managed to connect this extension to our local models on Ollama.
Conclusion
This list could be a lot longer, we use open source software in almost all we do. I hope this little text can be interesting and that we can start a conversation on what tools we use to build (generative) AI in the Swedish public sector.
What do you use at your agency or municipality? Don't hesitate to reply in this thread and to get in touch with us! We'd love to collaborate!

-
Intressant Pierre! Jag ska skicka den här tråden till mina AI-kollegor som pratar en hel del om generativ AI:)