Community på Sveriges dataportal
Wikibase and the EU Knowledge Graph as an use case
-
16 November 14.00-15.30 (CET): Wikibase and the EU Knowledge Graph as a use case
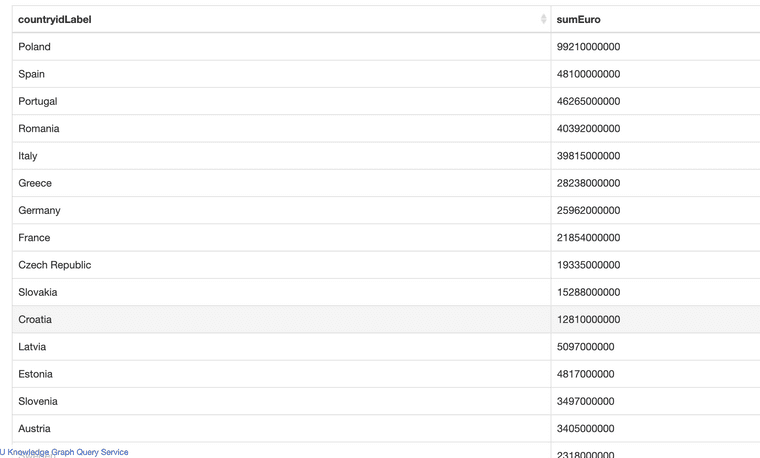
- The largest part of the graph is represented by projects financed by the European Union Cohesion funds. This data is exposed to citizens in Kohesio available at https://kohesio.eu.


-
@salgo60-ej-aktiv sa i Wikibase and the EU Knowledge Graph as an use case:
- The largest part of the graph is represented by projects financed by the European Union Cohesion funds. This data is exposed to citizens in Kohesio available at https://kohesio.eu.
Det var en väldig massa projekt i Portugal och Italien jämfört med övriga länder, och en del länder verkar sakna data. Hur går man tillväga för att göra summeringar på belopp per region t.ex.?
-
-
@salgo60-ej-aktiv Tack för demonstrationen. Det verkar som det kan vara ganska prestandakrävande att ställa intressanta frågor.
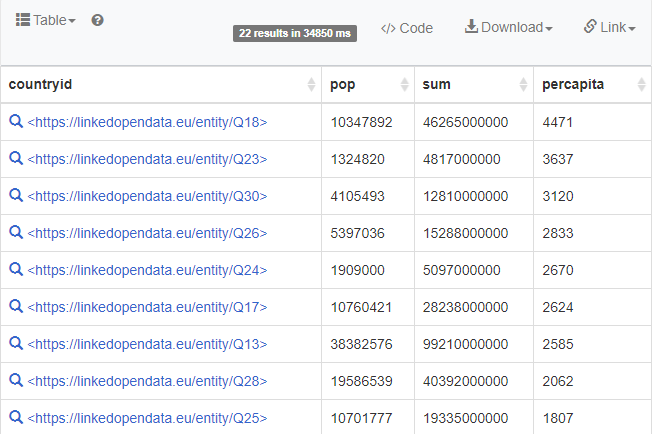
Jag provade som en övning att hämta folkmängd och budget per capita också. Population har flera värden över tid, men det verkar som det senaste värdet väljs automatiskt på något vis.
Som sagt vore det ju roligt att ha med namnen på länderna, men det orkar tydligen inte frågetjänsten med. Jag vet inte om man i praktiska sammanhang brukar kombinera olika typer av databastjänster och verktyg för att göra analyser.
java.util.concurrent.TimeoutException
at java.util.concurrent.FutureTask.get(FutureTask.java:205)
at com.bigdata.rdf.sail.webapp.BigdataServlet.submitApiTask(BigdataServlet.java:292)
at com.bigdata.rdf.sail.webapp.QueryServlet.doSparqlQuery(QueryServlet.java:678)
at com.bigdata.rdf.sail.webapp.QueryServlet.doGet(QueryServlet.java:290)
at com.bigdata.rdf.sail.webapp.RESTServlet.doGet(RESTServlet.java:240)Portugal (Q18)
Estonia (Q23)
Croatia (Q30)
Slovakia (Q26)
Latvia (Q24)
Greece (Q17)
Poland (Q13)
Romania (Q28)
...
-
@salgo60-ej-aktiv Aha ok, hade inte sett uppföljningen. Det gäller då att veta lite mer om hur systemet samlar ihop datan när man konstruerar frågor.
Med etiketter:
https://tinyurl.com/ye8lt2u2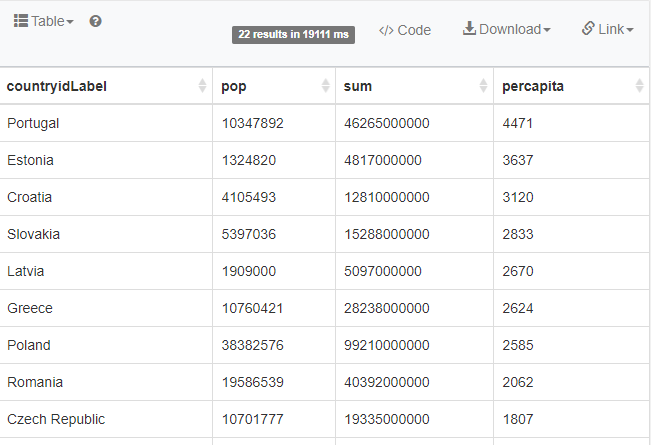
-
@jonor japp snyggt tacka Tagishsimon
") min variant https://tinyurl.com/yh3xpk27 verkar galet att Portugal har 20 ggr mer än Sverige jämfört per capita....
min variant https://tinyurl.com/yh3xpk27 verkar galet att Portugal har 20 ggr mer än Sverige jämfört per capita....video om detta med rank och federated search etc...
-
@salgo60-ej-aktiv Ok, jag hade av något skäl fått för mig att preferred rank skulle ligga högre upp i listan, men den låg längst ned där då. Ser nu att uppåt-pilen för rankning är fylld i den aktuella posten, förutom att det också framgår av egenskapen om "reason for preferred rank".
BNP är förstås också en intressant faktor att ta med i sammanhanget.
Det ser ut att finnas en hel del klurigheter i SPARQL att läsa in sig på, och körordningen är ju inte helt uppenbar, men kanske en tumregel är att körning av grupperade satser sker inifrån och ut. På Wikidata finns väl en förenklad query builder också, men jag vet inte hur långt man kommer med den, om det t.ex. skulle gå att formulera federerade frågor.
-
@jonor sa i Wikibase and the EU Knowledge Graph as an use case:
körordningen
-
första gången jag ser detta problem men det beror nog mer på att bra öppna data inte finns och mina SPARQL ofta är "koppla ihop" objekt
- utan vara databasmotor guru så känns det som en liten brist i SPARQL motorn (Blazegraph) att den "måste" ha nestlade sökningar för att optimera sökningen... borde inte vara raketforskning att inse att en Group by borde styra hur frågan exekveras (i detta fall etiketter...)
-
Tyvärr så är vi inte bortskämda med bra öppna data och SPARQL endpoints...
- vore trevligt om Vinnova, NSÖD, DIGG hade endpoint och levererade dataset. Känns udda att man inte designar med API first utan DIGG skapar websidor, att NSÖD verkar sakna verksamhets förankring och knappt fått fram data utan fokus verkar vara skapar några specar utan tydlig kravbild...
- vän av ordning känner att vi bara kastar bort skattepengar när vi inte jobbar mer strukturerat och det saknas ett "urgency" och ett commitment från kommuner, myndigheter....
- vore trevligt om Vinnova, NSÖD, DIGG hade endpoint och levererade dataset. Känns udda att man inte designar med API first utan DIGG skapar websidor, att NSÖD verkar sakna verksamhets förankring och knappt fått fram data utan fokus verkar vara skapar några specar utan tydlig kravbild...
-
Känns även som rollen som IT arkitekt som har visioner och känner ett ansvar för Öppna data är ledig
-
-
@salgo60-ej-aktiv sa i Wikibase and the EU Knowledge Graph as an use case:
- första gången jag ser detta problem men det beror nog mer på att bra öppna data inte finns och mina SPARQL ofta är "koppla ihop" objekt
- utan vara databasmotor guru så känns det som en liten brist i SPARQL motorn (Blazegraph) att den "måste" ha nestlade sökningar för att optimera sökningen... borde inte vara raketforskning att inse att en Group by borde styra hur frågan exekveras (i detta fall etiketter...)
Jo jag håller med, jag blev lite förvånad att den inte kunde optimera frågan på egen hand. I så fall skulle man behöva lite mer stöd för att kunna analysera och jämföra prestandan i delar av frågor.
- första gången jag ser detta problem men det beror nog mer på att bra öppna data inte finns och mina SPARQL ofta är "koppla ihop" objekt
-
@jonor sa i Wikibase and the EU Knowledge Graph as an use case:
Jo jag håller med, jag blev lite förvånad att den inte kunde optimera frågan på egen hand. I så fall skulle man behöva lite mer stöd för att kunna analysera och jämföra prestandan i delar av frågor.
Känner du till https://github.com/ad-freiburg/QLever? Jag har korresponderat huvudarkitekten, Hanna Bast, som doktorerat inom algoritmer och specialiserad sig på optimering. Den motorn visar tydligt vilka delar i frågan som tar längst tid och den är väldigt överlägsen BlazeGraph när det gäller sökoptimering. Detta kommer med en kostnad i form av den tid och energi som går åt att skapa ett index.
BlazeGraph är gjort för data som ändras snabbt och inte optimerat särskilt mycket verkar det som och tyvärr underhålls den inte alls sen flera år.
-
@jonor sa i Wikibase and the EU Knowledge Graph as an use case:
Det ser ut att finnas en hel del klurigheter i SPARQL att läsa in sig på, och körordningen är ju inte helt uppenbar, men kanske en tumregel är att körning av grupperade satser sker inifrån och ut. På Wikidata finns väl en förenklad query builder också, men jag vet inte hur långt man kommer med den, om det t.ex. skulle gå att formulera federerade frågor.
Japp, klurigt är det. BlazeGraph har hemsnickrat syntax också som inte är med i specifikationen också (tex named subquery som behövdes här).
Det går inte i dagsläget med Query Builder vad jag vet. SPARQL är en hel vetenskap verkar det som och det är en rätt brant inlärningskurva på språket tycker jag och ingen har gjort en överblick vad jag sett över vilka motorer som finns och vad de stödjer och inte. Dags för att bygga ut https://en.wikipedia.org/wiki/Comparison_of_triplestores med en ny tabell för vilka SPARQL features motorerna implementerad?
Om du vill kan du skapa ett ärende på https://phabricator.wikimedia.org/ för Query Builder och fråga efter stöd för federering
")
-
@salgo60-ej-aktiv Hej, det här inlägget verkar vara en blandning av
- Tips om en sakfråga
- Kritik om arbetssätt, organisation och bemanning av några aktiviteter.
De här två delarna mynnar ut i två skilda diskussioner.
Kan du dela upp inlägget i två så vi kan hantera frågorna var för sig? Som det är nu försvinner sakfrågan i kritiken, vilket jag tycker är synd.
-
@salgo60-ej-aktiv sa i Wikibase and the EU Knowledge Graph as an use case:
- Lucas 1 juni 2021 "Wikidata Live Querying"
Den hade jag inte sett! Tack för tipset
-
System referenced this topic on
-
Finns nu i Wikidata som en egenskap P11012
-
@Nina_Berlin
Håller med föregående talare!


Mvh Jakob
Web: https://karlstadsupport.se -
System referenced this topic on
-
@adrian sa i Blogginlägg: EU:s dataområden:
Det är EU-kommissionens program som är centralt förvaltat av EU-kommissionen. Därför är det också EU-kommissionen som gör uppföljningen och håller reda på finansieringens utfall. Genom att göra en sökning här kan du få fram alla projekt som är igång och fått finansiering genom DIGITAL
Tack @adrian det verkar som du har koll... vad ser man i denna Wikibase The_EU_Knowledge_Graph
- den presenterades 2021 nov 16 se post
- video Wikibase as an infrastructure for Knowledge Graphs: The EU Knowledge Graph - WikidataCon 2021