Community på Sveriges dataportal
Dela kodexempel: ett enda klick kan räcka
-
Att dela kodexempel
För några år sedan som gymnasielärare ville jag tillgängliggöra ett utbildningsmaterial som involverade programmeringskod. Jag kom fram till följande önskemål:
- Enkelt att komma igång
- Något icke-kommersiellt
- Roligare än bara kod och ett terminalfönster
Jag hade upptäckt Jupyter och bestämde mig för det som grund. Jupyter är en arbetsmiljö där kod kan skrivas och köras i så kallade Jupyter Notebooks där kod, text, grafer, och annat interaktivt kan få plats. Just därför lämpar de sig väl för utbildningsmaterial tycker jag!
Två lösningar
Jag kommer presentera två lösningar för att tillgängligöra kodexempel, utbildningsmaterial, och övrigt.
Den enklare lösningen
Med gratistjänsten mybinder.org kan du dela kodexempel som blir tillgänliga för andra att köra genom ett enda länkklick.
Ungefär såhär gör du för att dela kodexempel med mybinder.org:
- Gör kodexemplet tillgängligt på GitHub, GitLab, eller liknande.
- Skapa en konfigurationsfil (requirements.txt för Python t.ex.) som beskriver vad som behövs installeras
- Besök mybinder.org och skapa en länk
- Dela länken
Exempel på kodmaterial delat via mybinder.org:
-
Klassiskt kodexempel av Jupyter notebooks interaktivitet:
https://gke.mybinder.org/v2/gh/jupyterlab/jupyterlab-demo/master?urlpath=lab/tree/demo/Lorenz.ipynb -
Utbildningsmaterial för maskininlärning av mig, lämpligt för engagerade elever i gymnasiet som läst iallafall matte 3:
https://gke.mybinder.org/v2/gh/consideratio/jupyter-se-math-teacher/master?urlpath=lab/tree/source/gradient-descent/gradient-descent.ipynb -
Kodexempel på hur ett API av polisen.se kan användas, skapat av @salgo60 under Hack for Sweden 2019:
https://gke.mybinder.org/v2/gh/hack-for-sweden/open-data-examples/HEAD?urlpath=lab/tree/polisen-se.ipynb
Den klumpigare lösningen
Som lärare ville jag att mina elever skulle kunna spara sitt arbete och liknande, men för detta krävdes något mer än mybinder.org. Jag listar nedan projekten som möjliggör detta, och är nu projekt jag har möjliggjorts att arbeta fulltid med att utveckla. Att använda dessa lämpar sig kanske bäst för universitet, skolor, företag osv. som kan investera lite tid och energi att tillhandahålla en sådan infrastruktur för sina elever, anställda, eller liknande.
-
JupyterHub var ett lämpligt verktyg för att hjälpa mig göra Jupyter arbetsmiljöer tillgängliga för mina elever. Med en JupyterHub kunde de få köra koden på en extern dator istället för sin egen, och även spara sitt arbetsmaterial där osv.
-
JupyterHub installerat på Kubernetes visade sig även mycket lovande för att hjälpa hela min skola eller t.om. hela skolkoncernen.

University of California: Berkeley, studenter som går Data8 kursen där eleverna övar med kodexempel med hjälp av en JupyterHub.
Tack för er tid
Jag hoppas detta har kunnat fungera som en introduktion av potentiellt relevanta verktyg.
Varma hälsningar från Uppsala!
/ Erik Sundell -
@consideratio stort tack
Jobtech hade en session "API-nycklar, Swaggger och notebooks - hur maximerar vi tillgänglighetgörandet av öppna data?" 2 feb 2021 där Kevin Dee Boman (Göteborgs universitet) presenterade Jupyter se video vid 51 min
Det intressanta jag tog med mig var frågan vid 60 min där man föreslog att denna Jupyter lösning borde finnas tillgänglig och det intressanta var att som student var detta redan gjort på GITHUB och självklart. Känns som vi har en generations fråga och att vi behöver få detta tänk hos alla....
Fråga @consideratio : Jag gjorde en koppling #Wikidata och GITHUB Topics länk.... har du någon bra erfarenhet/tankar hur man enklare kan hitta vilka applikationer som skapats och som använder dataset...
Skall Sverige bli bäst i världen på Öppen data som alla lovar så måste vi få en helt annan utväxling är min tro. Viktiga komponenter
- tydligt ägande av data och dess kvalitet och då inte bara datat i min SILO utan mer som OWiD som samlar in all vaccinerings info från alla länder som alla kan hämta på GITHUB
- enormt mycket mer dialog och att det finns tydligt produktägande med publika backlogs
- synlighet från Ledare som pekar med rak hand att dom inte skyr några medel att vi skall bli bäst i världen och att man på ett trovärdigt sätt har en plan/uppföljning att detta skall ske...
- att dessa ledare hela tiden lyfter fram lyckade försök och identifierade problem så vi får
- ett momentum
- en känsla av urgency....
- att identifierade problem lyfts till någon typ av scrum av scrum möten mellan kommuner/myndigheter/intressenter ... SILOS är inte ok...
-
Superbra exempel! På Jobtech Development blev vi så inspirerade av dina exempel så vi tittar på om vi kan skapa en "paketerad"-miljö för icke-programmerare.
-
Va roligt!
Vill då kort också tipsa om en lättviktigare installation av JupyterHub kan göras utan Kubernetes med guiden på tljh.jupyter.org - då kan en ensam server används för upp till ungefär 100 samtida användare.
Vid behov kan en fråga efter hjälp på discourse.jupyter.org för övrigt, eller besöka JupyterHub's chatkanal på Gitter / Matrix.
Lycka till!
-
@salgo60 sa i Dela kodexempel: ett enda klick kan räcka:
har du någon bra erfarenhet/tankar hur man enklare kan hitta vilka applikationer som skapats och som använder dataset...
Hmmm nej tror det krävs en standard för deklarera datakällor. Det kan mycket väl krävas att det finns någon morot att använda denna standard för att deklarera datakällor också för att den ska tillämpas.
Jag kom att tänka på att GitHub redan kan visa vilka kodprojekt som beror på andra kodprojekt genom att söka efter välkända filnamn. På motsvarande sätt funderar jag på ifall det finns motsvarande filer som deklarerar datakällor, och jag tror det.
Jag kan inte så mycket om Intake, men det är ett verktyg som hjälper användare att konsumera data från olika källor. Med Intake så deklarerar användarna faktiskt sina datakällor i en YAML fil. Så om de börjar rekommendera ett enhetligt sätt att namnge dessa filer så vore det fullt rimligt att scanna källkod på GitHub, GitLab etc efter dessa filer.
Detta blev en avstickare från ämnet av att dela kodexempel, så jag föreslår att uppföljningar görs från en helt ny tråd i detta forum dock!
-
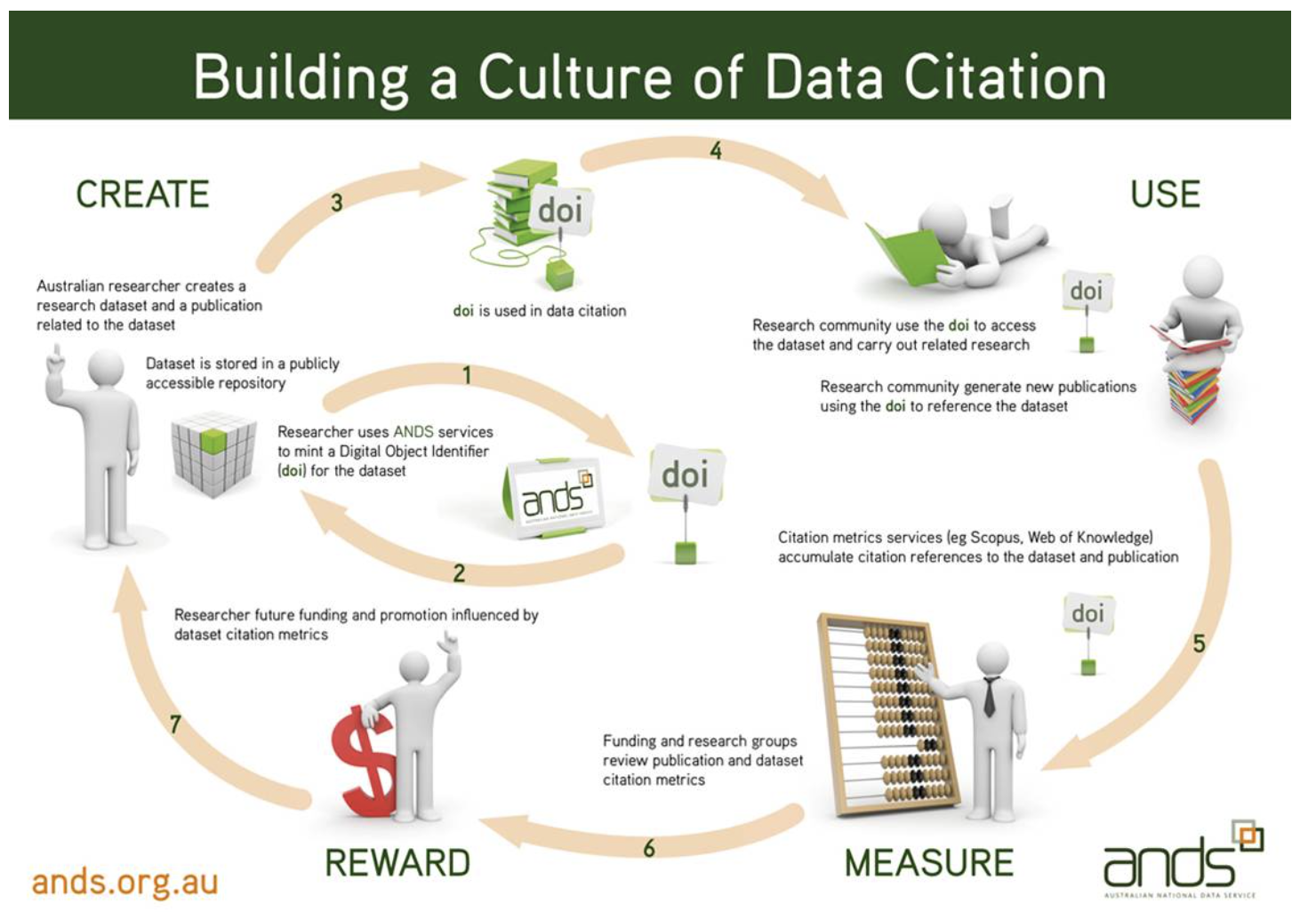
@consideratio jag skrev lite om DOI som publik unik identifierare här som jag tror är det sätt vi borde vandra att peka unikt på en version av ett dataset
DOI och ORCID används av forskare och detta mönster känns värt att följa....
Tycker mig ha sett att https://www.fairsfair.eu/ driver detta på ett bra sätt video
-
 M Maria_Dalhage moved this topic from Goda exempel och inspiration on
M Maria_Dalhage moved this topic from Goda exempel och inspiration on
{kind=link}