Hej,
Idag har vi på Riksarkivet officiellt släppt en öppen basmodell för handskriftsigenkänning (HTR). Den fungerar bäst på svenska handskrifter ca 1650 - 1900.
Med basmodell avses att den har två tänkta användningsområden:1. Att HTR:a stora mängder bilder av handskriven text med god nog kvalitet för att indexera texten för sök.2. Att fungera som en utgångspunkt för att mha egen träningsdata skapa mer specialiserade HTR-modeller.
I släppet ingår modeller för region och linjeanalys. Dessa är väl anpassade för dokument som tex rapporter, brev, protokoll, och bokmanuskript. De är dock inte anpassade för analys av tabeller och formulär. För det syftet behöver skräddarsydda modeller tas fram för varje materialtyp.
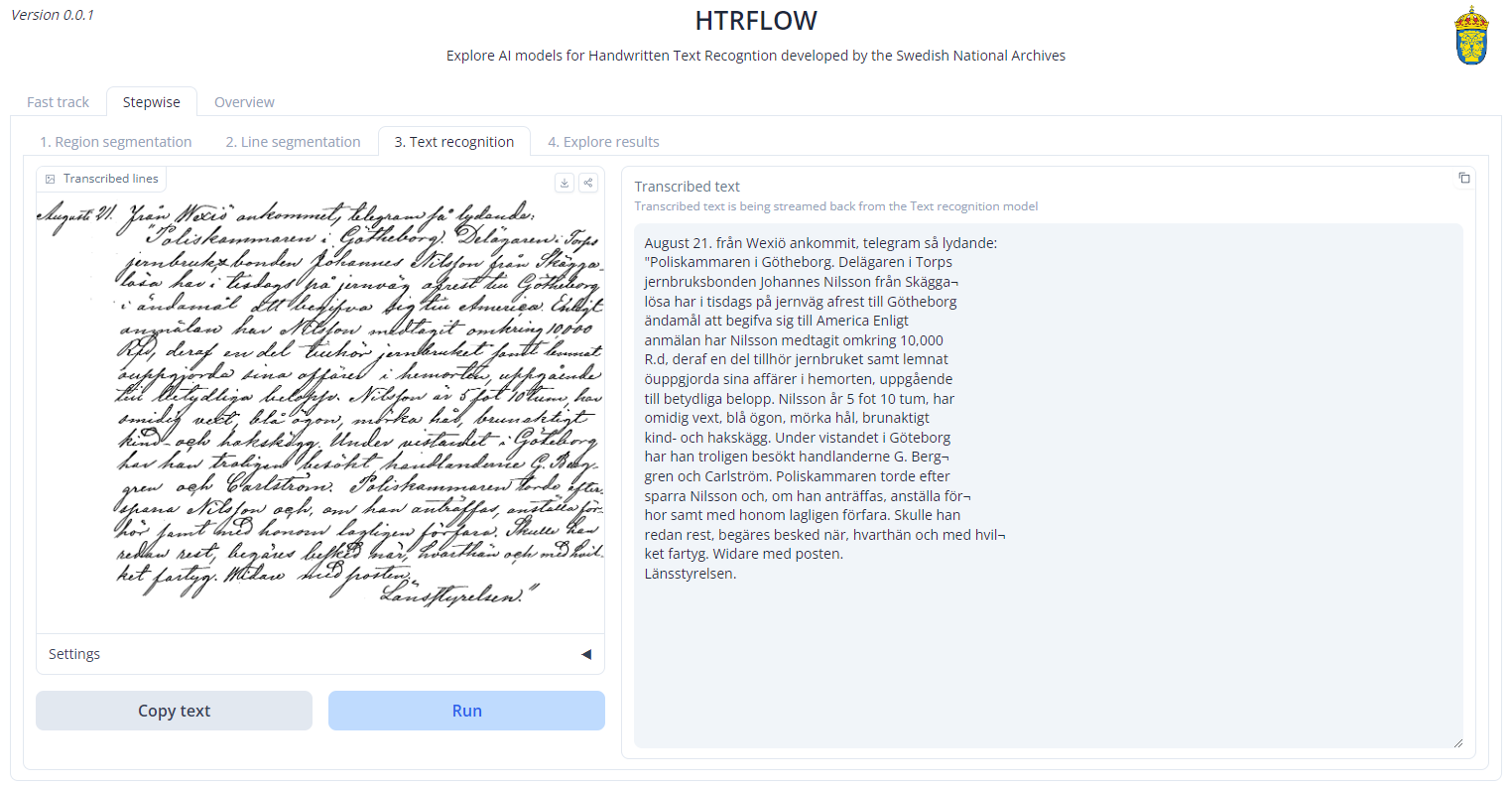
Vidare ingår i släppet en enkel mjukvara för att köra dessa modeller, HTRFLOW. Det går att testa denna på enstaka filer på HuggingFace men vill du använda den i någon större skala så behöver du installera HTRFLOW i egen miljö.
Det finns många fler detaljer än det jag skrivit ovan så har ni frågor så ställ dem så ska jag svara efter bästa förmåga!
Vår HuggingFace: https://huggingface.co/Riksarkivet Källkoden till HTRFLOW: https://github.com/Riksarkivet/HTRFLOW